Политика обучения с подкреплением является отображением, которое выбирает действие, чтобы взять на основе наблюдений из среды. Во время обучения агент настраивает параметры своего представления политики, чтобы максимизировать долгосрочное вознаграждение.
В зависимости от типа агента обучения с подкреплением вы используете, вы задаете агента и функцию критика approximators, который использование агента представлять и обучить его политику. Агент представляет политику, которая выбирает лучшее действие, чтобы взять. Критик представляет функцию значения, которая оценивает долгосрочное вознаграждение за текущую политику. В зависимости от вашего приложения и выбранного агента, можно задать политику и функции значения с помощью глубоких нейронных сетей, линейных основных функций или интерполяционных таблиц.
Для получения дополнительной информации об агентах смотрите Агентов Обучения с подкреплением.
В зависимости от типа агента вы используете, пакет Reinforcement Learning Toolbox™ поддерживает следующие типы функции approximators:
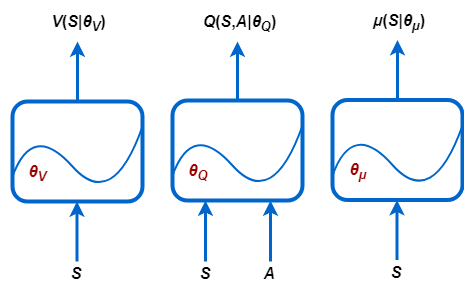
V (S |θV) — Критики, которые оценивают ожидаемое долгосрочное вознаграждение на основе наблюдения S
Q (S, A |θQ) — Критики, которые оценивают ожидаемое долгосрочное вознаграждение на основе наблюдения S и действие A
μ (S |θμ) — Агенты, которые выбирают действие на основе наблюдения S
Каждая функция approximator имеет соответствующий набор параметров (θV, θQ или θμ), которые вычисляются во время процесса обучения.
Для систем с ограниченным количеством дискретных наблюдений и дискретных действий, можно сохранить функции значения в интерполяционной таблице. Для систем, которые имеют много дискретных наблюдений и действий или с пробелами наблюдения и действия, которые непрерывны, храня наблюдения и действия, становится непрактичным. Для таких систем можно представлять агентов и критиков, использующих глубокие нейронные сети или линейные основные функции.
Можно создать два типа табличных представлений:
Таблицы значения, которые хранят вознаграждения за соответствующие наблюдения.
Q-таблицы, которые хранят вознаграждения за соответствующие пары действия наблюдения.
Чтобы создать табличное представление, сначала составьте таблицу значения или Q-таблицу с помощью rlTable функция. Затем создайте представление для таблицы с помощью rlRepresentation функция. Чтобы сконфигурировать темп обучения и оптимизацию, используемую представлением, используйте rlRepresentationOptions объект.
Можно создать агента и функцию критика approximators использование представлений глубокой нейронной сети. Выполнение так использует программные функции Deep Learning Toolbox™.
Размерности вашего агента и сетей критика должны совпадать с соответствующими спецификациями действия и наблюдения от учебного объекта среды. Получить размерности действия и наблюдения для среды env, используйте getActionInfo и getObservationInfo функции, соответственно. Затем получите доступ к Dimensions свойство объектов спецификации.
actInfo = getActionInfo(env); actDimensions = actionInfo.Dimensions; obsInfo = getObservationInfo(env); obsDimensions = observatonInfo.Dimensions;
Для сетей критика, которые берут только наблюдения в качестве входных параметров, таких как используемые в AC или агентах PG, размерности входных слоев должны совпадать с размерностями спецификаций наблюдения среды. Размерности выходного слоя критика должны быть функцией скалярного значения.
Для сетей критика, которые берут только наблюдения и действия как входные параметры, такие как используемые в DQN или агентах DDPG, размерности входных слоев должны совпадать с размерностями соответствующего наблюдения среды и спецификаций действия. В этом случае размерности выходного слоя критика должны также быть функцией скалярного значения.
Поскольку агент объединяется в сеть, размерности входных слоев должны совпадать с размерностями спецификаций наблюдения среды. Если агент имеет a:
Дискретный пробел действия, затем его выходной размер должен равняться количеству дискретных действий.
Непрерывный пробел действия, затем его выходной размер должен быть скалярным или векторным значением, как задано в спецификации наблюдения.
Глубокие нейронные сети состоят из серии взаимосвязанных слоев. В следующей таблице перечислены некоторые общие слои глубокого обучения, используемые в приложениях обучения с подкреплением. Для полного списка доступных слоев смотрите Список слоев глубокого обучения (Deep Learning Toolbox).
| Слой | Описание |
|---|---|
imageInputLayer | Входные векторы и 2D изображения, и нормируют данные. |
tanhLayer | Примените гиперболический слой активации касательной к входным параметрам слоя. |
reluLayer | Установите любые входные значения, которые меньше нуля, чтобы обнулить. |
fullyConnectedLayer | Умножьте входной вектор на матрицу веса и добавьте вектор смещения. |
convolution2dLayer | Примените скользящие сверточные фильтры к входу. |
additionLayer | Добавьте выходные параметры нескольких слоев вместе. |
concatenationLayer | Конкатенация входных параметров в заданном измерении. |
lstmLayer, bilstmLayer, и batchNormalizationLayer слои не поддержаны для обучения с подкреплением.
Можно также создать собственные слои. Для получения дополнительной информации смотрите, Задают Пользовательские Слои Глубокого обучения (Deep Learning Toolbox). Программное обеспечение Reinforcement Learning Toolbox обеспечивает следующие пользовательские слои.
| Слой | Описание |
|---|---|
scalingLayer | Линейно масштабируйте и сместите входной массив. Этот слой полезен для масштабирования и перемещения выходных параметров нелинейных слоев, таков как tanhLayer и сигмоидальный. |
quadraticLayer | Создайте вектор квадратичных одночленов, созданных из элементов входного массива. Этот слой полезен, когда вам нужен выход, который является некоторой квадратичной функцией его входных параметров, такой что касается контроллера LQR. |
scalingLayer и quadraticLayer пользовательские слои не содержат настраиваемые параметры; то есть, они не изменяются во время обучения.
Для приложений обучения с подкреплением вы создаете свою глубокую нейронную сеть путем соединения серии слоев для каждого входа path (наблюдения или действия) и для каждого выхода path (оцененные вознаграждения или действия). Вы затем соединяете эти пути вместе с помощью connectLayers функция.
Можно также создать глубокую нейронную сеть с помощью приложения Deep Network Designer. Для примера смотрите, Создают Агента Используя Deep Network Designer и Обучаются Используя Наблюдения Изображений.
Когда вы создаете глубокую нейронную сеть, необходимо задать имена для первого слоя каждого входа path и последнего слоя выхода path.
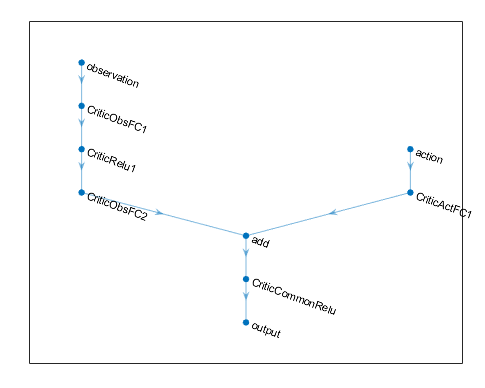
Следующий код создает и соединяет следующие пути к вводу и выводу:
Вход path наблюдения, observationPath, с первым слоем под названием 'observation'.
Вход path действия, actionPath, с первым слоем под названием 'action'.
Функция ориентировочной стоимости выход path, commonPath, который берет выходные параметры observationPath и actionPath как входные параметры. Последний слой этого пути называют 'output'.
observationPath = [
imageInputLayer([4 1 1],'Normalization','none','Name','observation')
fullyConnectedLayer(24,'Name','CriticObsFC1')
reluLayer('Name','CriticRelu1')
fullyConnectedLayer(24,'Name','CriticObsFC2')];
actionPath = [
imageInputLayer([1 1 1],'Normalization','none','Name','action')
fullyConnectedLayer(24,'Name','CriticActFC1')];
commonPath = [
additionLayer(2,'Name','add')
reluLayer('Name','CriticCommonRelu')
fullyConnectedLayer(1,'Name','output')];
criticNetwork = layerGraph(observationPath);
criticNetwork = addLayers(criticNetwork,actionPath);
criticNetwork = addLayers(criticNetwork,commonPath);
criticNetwork = connectLayers(criticNetwork,'CriticObsFC2','add/in1');
criticNetwork = connectLayers(criticNetwork,'CriticActFC1','add/in2');Поскольку все наблюдение и действие вводят пути, необходимо задать imageInputLayer слой как первый слой в пути.
Можно просмотреть структуру глубокой нейронной сети с помощью plot функция.
plot(criticNetwork)
Для PG и агентов AC, слоями окончательного результата вашего представления агента глубокой нейронной сети является fullyConnectedLayer и softmaxLayer слой. Когда вы задаете слои для своей сети, необходимо задать fullyConnectedLayer и можно опционально задать softmaxLayer слой. Если вы не используете softmaxLayer, программное обеспечение автоматически добавляет один для вас.
При определении номера введите, и размер слоев для представления глубокой нейронной сети может затруднить и является зависящим от приложения. Однако самый критический компонент для любой функции approximator - может ли функция аппроксимировать оптимальную политику или обесцененную функцию значения для вашего приложения; то есть, делает это имеет слои, которые могут правильно изучить функции вашего наблюдения, действия и сигналов вознаграждения.
Рассмотрите следующие советы при построении сети.
Для непрерывных пробелов действия, связанных действий с tanhLayer сопровождаемый ScalingLayer, при необходимости.
Глубоко плотные сети с reluLayers может быть довольно хорошо в аппроксимации многих различных функций. Поэтому они часто - хороший предпочтительный вариант.
При аппроксимации сильной нелинейности или систем с алгебраическими ограничениями, часто лучше добавить больше слоев, а не растущего числа выходных параметров на слой. Добавление большего количества слоев способствует экспоненциальному исследованию при добавлении, что слой выходные параметры способствует полиномиальному исследованию.
Для агентов на политике, таких как AC и агенты PG, параллельное обучение работает лучше, если ваши сети являются большими (например, сеть с двумя скрытыми слоями с 32 узлами каждый, который имеет несколько сотен параметров). Параллельные обновления на политике принимают, что каждый рабочий обновляет другую часть сети, такой как тогда, когда они исследуют различные области пространства наблюдений. Если сеть мала, обновления рабочего могут коррелировать друг с другом и сделать обучение нестабильным.
Чтобы создать агента или объект представления критика для вашей глубокой нейронной сети, используйте rlRepresentation функция. Чтобы сконфигурировать темп обучения и оптимизацию, используемую представлением, используйте rlRepresentationOptions объект.
Например, создайте объект представления для сети criticNetwork критика, определение темпа обучения 0.0001. Когда вы создаете представление, передаете спецификации действия и наблюдения среды rlRepresentation функция, и задает имена сетевых слоев, с которыми соединяются действия и наблюдения.
opt = rlRepresentationOptions('LearnRate',0.0001); critic = rlRepresentation(criticNetwork,'Observation',{'observation'},obsInfo... 'Action',{'action'},actInfo,opt);
При создании глубокой нейронной сети и конфигурировании объекта представления, рассмотрите использование одного из следующих подходов как начальная точка:
Запустите с самой маленькой сети и высокого темпа обучения (0.01). Обучите эту начальную сеть, чтобы видеть, сходится ли агент быстро к плохой политике или действиям случайным способом. Если или этих проблем происходят, повторно масштабируют сеть путем добавления большего количества слоев или большего количества выходных параметров на каждом слое. Ваша цель состоит в том, чтобы найти сетевую структуру, которая является только достаточно большой, не учится слишком быстро и показывает знаки изучения (улучшающаяся траектория премиального графика) после периода начальной подготовки.
Первоначально сконфигурируйте агента, чтобы медленно учиться путем установки низкого темпа обучения. Путем изучения медленно, можно проверять, чтобы видеть, на правильном пути ли агент, который может помочь проверить, является ли сетевая архитектура удовлетворительной для проблемы. Для трудных проблем настройка параметров намного легче, если вы обосновываетесь на хорошей сетевой архитектуре.
Кроме того, рассмотрите следующие советы при конфигурировании представления глубокой нейронной сети:
Будьте терпеливы с DDPG и агентами DQN, поскольку они ничего не могут изучать в течение некоторого времени во время ранних эпизодов, и они обычно показывают падение в совокупном вознаграждении рано в учебном процессе. В конечном счете они могут показать знаки изучения после первой нескольких тысяч эпизодов.
Для DDPG и агентов DQN, способствуя исследованию агента очень важно.
Для агентов и с агентом и с сетями критика, набор начальные темпы обучения обоих представлений тому же значению. Для некоторых проблем, устанавливая темп обучения критика на более высокое значение, чем тот из агента может улучшить изучение результатов.
Линейные представления основной функции имеют форму f = W'B, где W массив веса и B вектор-столбец выход пользовательской основной функции. learnable параметры линейного представления основной функции являются элементами W.
Для представлений критика, f скалярное значение и W вектор-столбец с той же длиной как B.
Для представлений агента, с a:
Непрерывный пробел действия, размерности f совпадайте с размерностями спецификации действия агента, которая является или скаляром или вектор-столбцом.
Дискретный пробел действия, f вектор-столбец с длиной, равной количеству дискретных действий.
Для представлений агента, количества столбцов в W равняется числу элементов в f.
Чтобы создать линейное представление основной функции, сначала создайте пользовательскую основную функцию, которая возвращает вектор-столбец. Подпись этой основной функции зависит от того, какую функцию approximator вы создаете. Когда вы создаете:
Представление критика с наблюдением вводит только или представление агента, ваша основная функция должна иметь следующую подпись.
B = myBasisFunction(obs1,obs2,...,obsN)
Представление критика с входными параметрами наблюдения и действия, ваша основная функция должна иметь следующую подпись.
B = myBasisFunction(obs1,obs2,...,obsN,act)
Здесь obs1 к obsN наблюдения в том же порядке и с совпадающим типом данных и размерностями как спецификации наблюдения агента и act имеет совпадающий тип данных и размерности как спецификация действия агента.
Каждый элемент B может быть любая функция сигналов наблюдения и действия, в зависимости от требований вашего приложения.
Для получения дополнительной информации о создании такого представления смотрите rlRepresentation.
Для примера, который обучает пользовательского агента, который использует линейное представление основной функции, смотрите, Обучают Пользовательского Агента LQR.
Если вы создаете своего агента и представления критика, можно создать агента обучения с подкреплением, который использует эти представления. Например, создайте агента PG с помощью данного агента и сети критика.
agentOpts = rlPGAgentOptions('UseBaseline',true);
agent = rlPGAgent(actor,baseline,agentOpts);Для получения дополнительной информации о различных типах агентов обучения с подкреплением смотрите Агентов Обучения с подкреплением.
Можно получить агента и представления критика от существующего агента с помощью getActor и getCritic, соответственно.
Можно также установить агента и критика существующего агента с помощью setActor и setCritic, соответственно. Когда вы задаете представление с помощью этих функций, слои ввода и вывода заданного представления должны совпадать с наблюдением и спецификациями действия исходного агента.
rlRepresentation | rlRepresentationOptions
