Модель Latent Dirichlet allocation (LDA)
Модель скрытого выделения Дирихле (LDA) является моделью темы, которая обнаруживает базовые темы в наборе документов и выводит вероятности слова в темах. Если модель была подходящим использованием мешка n модели граммов, то программное обеспечение обрабатывает N-граммы как отдельные слова.
Создайте модель LDA с помощью fitlda функция.
logp | Логарифмические вероятности документа и качество подгонки модели LDA |
predict | Предскажите главные темы LDA документов |
resume | Продолжите подбирать модель LDA |
topkwords | Большинство важных слов в модели сумки слов или теме LDA |
transform | Преобразуйте документы в более низкое мерное пространство |
wordcloud | Создайте график облака слова из текста, модели сумки слов, мешка n модели граммов или модели LDA |
Чтобы воспроизвести результаты в этом примере, установите rng к 'default'.
rng('default')Загрузите данные в качестве примера. Файл sonnetsPreprocessed.txt содержит предварительно обработанные версии сонетов Шекспира. Файл содержит один сонет на строку со словами, разделенными пробелом. Извлеките текст из sonnetsPreprocessed.txt, разделите текст в документы в символах новой строки, и затем маркируйте документы.
filename = "sonnetsPreprocessed.txt";
str = extractFileText(filename);
textData = split(str,newline);
documents = tokenizedDocument(textData);Создайте модель сумки слов использование bagOfWords.
bag = bagOfWords(documents)
bag =
bagOfWords with properties:
Counts: [154x3092 double]
Vocabulary: [1x3092 string]
NumWords: 3092
NumDocuments: 154
Подбирайте модель LDA с четырьмя темами.
numTopics = 4; mdl = fitlda(bag,numTopics)
Initial topic assignments sampled in 0.107614 seconds. ===================================================================================== | Iteration | Time per | Relative | Training | Topic | Topic | | | iteration | change in | perplexity | concentration | concentration | | | (seconds) | log(L) | | | iterations | ===================================================================================== | 0 | 0.03 | | 1.215e+03 | 1.000 | 0 | | 1 | 0.04 | 1.0482e-02 | 1.128e+03 | 1.000 | 0 | | 2 | 0.01 | 1.7190e-03 | 1.115e+03 | 1.000 | 0 | | 3 | 0.02 | 4.3796e-04 | 1.118e+03 | 1.000 | 0 | | 4 | 0.02 | 9.4193e-04 | 1.111e+03 | 1.000 | 0 | | 5 | 0.02 | 3.7079e-04 | 1.108e+03 | 1.000 | 0 | | 6 | 0.02 | 9.5777e-05 | 1.107e+03 | 1.000 | 0 | =====================================================================================
mdl =
ldaModel with properties:
NumTopics: 4
WordConcentration: 1
TopicConcentration: 1
CorpusTopicProbabilities: [0.2500 0.2500 0.2500 0.2500]
DocumentTopicProbabilities: [154x4 double]
TopicWordProbabilities: [3092x4 double]
Vocabulary: [1x3092 string]
TopicOrder: 'initial-fit-probability'
FitInfo: [1x1 struct]
Визуализируйте темы с помощью облаков слова.
figure for topicIdx = 1:4 subplot(2,2,topicIdx) wordcloud(mdl,topicIdx); title("Topic: " + topicIdx) end

Составьте таблицу слов с самой высокой вероятностью темы LDA.
Чтобы воспроизвести результаты, установите rng к 'default'.
rng('default')Загрузите данные в качестве примера. Файл sonnetsPreprocessed.txt содержит предварительно обработанные версии сонетов Шекспира. Файл содержит один сонет на строку со словами, разделенными пробелом. Извлеките текст из sonnetsPreprocessed.txt, разделите текст в документы в символах новой строки, и затем маркируйте документы.
filename = "sonnetsPreprocessed.txt";
str = extractFileText(filename);
textData = split(str,newline);
documents = tokenizedDocument(textData);Создайте модель сумки слов использование bagOfWords.
bag = bagOfWords(documents);
Подбирайте модель LDA с 20 темами. Чтобы подавить многословный выход, установите 'Verbose' к 0.
numTopics = 20;
mdl = fitlda(bag,numTopics,'Verbose',0);Найдите лучшие 20 слов первой темы.
k = 20; topicIdx = 1; tbl = topkwords(mdl,k,topicIdx)
tbl=20×2 table
Word Score
________ _________
"eyes" 0.11155
"beauty" 0.05777
"hath" 0.055778
"still" 0.049801
"true" 0.043825
"mine" 0.033865
"find" 0.031873
"black" 0.025897
"look" 0.023905
"tis" 0.023905
"kind" 0.021913
"seen" 0.021913
"found" 0.017929
"sin" 0.015937
"three" 0.013945
"golden" 0.0099608
⋮
Найдите лучшие 20 слов первой темы и используйте среднее значение инверсии масштабироваться на баллах.
tbl = topkwords(mdl,k,topicIdx,'Scaling','inversemean')
tbl=20×2 table
Word Score
________ ________
"eyes" 1.2718
"beauty" 0.59022
"hath" 0.5692
"still" 0.50269
"true" 0.43719
"mine" 0.32764
"find" 0.32544
"black" 0.25931
"tis" 0.23755
"look" 0.22519
"kind" 0.21594
"seen" 0.21594
"found" 0.17326
"sin" 0.15223
"three" 0.13143
"golden" 0.090698
⋮
Создайте облако слова с помощью масштабированных баллов в качестве данных о размере.
figure wordcloud(tbl.Word,tbl.Score);

Доберитесь вероятности тематики документа (также известный как смеси темы) документов раньше подбирали модель LDA.
Чтобы воспроизвести результаты, установите rng к 'default'.
rng('default')Загрузите данные в качестве примера. Файл sonnetsPreprocessed.txt содержит предварительно обработанные версии сонетов Шекспира. Файл содержит один сонет на строку со словами, разделенными пробелом. Извлеките текст из sonnetsPreprocessed.txt, разделите текст в документы в символах новой строки, и затем маркируйте документы.
filename = "sonnetsPreprocessed.txt";
str = extractFileText(filename);
textData = split(str,newline);
documents = tokenizedDocument(textData);Создайте модель сумки слов использование bagOfWords.
bag = bagOfWords(documents);
Подбирайте модель LDA с 20 темами. Чтобы подавить многословный выход, установите 'Verbose' к 0.
numTopics = 20;
mdl = fitlda(bag,numTopics,'Verbose',0)mdl =
ldaModel with properties:
NumTopics: 20
WordConcentration: 1
TopicConcentration: 5
CorpusTopicProbabilities: [1x20 double]
DocumentTopicProbabilities: [154x20 double]
TopicWordProbabilities: [3092x20 double]
Vocabulary: [1x3092 string]
TopicOrder: 'initial-fit-probability'
FitInfo: [1x1 struct]
Просмотрите вероятности темы первого документа в обучающих данных.
topicMixtures = mdl.DocumentTopicProbabilities; figure bar(topicMixtures(1,:)) title("Document 1 Topic Probabilities") xlabel("Topic Index") ylabel("Probability")

Чтобы воспроизвести результаты в этом примере, установите rng к 'default'.
rng('default')Загрузите данные в качестве примера. Файл sonnetsPreprocessed.txt содержит предварительно обработанные версии сонетов Шекспира. Файл содержит один сонет на строку со словами, разделенными пробелом. Извлеките текст из sonnetsPreprocessed.txt, разделите текст в документы в символах новой строки, и затем маркируйте документы.
filename = "sonnetsPreprocessed.txt";
str = extractFileText(filename);
textData = split(str,newline);
documents = tokenizedDocument(textData);Создайте модель сумки слов использование bagOfWords.
bag = bagOfWords(documents)
bag =
bagOfWords with properties:
Counts: [154x3092 double]
Vocabulary: [1x3092 string]
NumWords: 3092
NumDocuments: 154
Подбирайте модель LDA с 20 темами.
numTopics = 20; mdl = fitlda(bag,numTopics)
Initial topic assignments sampled in 0.172684 seconds. ===================================================================================== | Iteration | Time per | Relative | Training | Topic | Topic | | | iteration | change in | perplexity | concentration | concentration | | | (seconds) | log(L) | | | iterations | ===================================================================================== | 0 | 0.18 | | 1.159e+03 | 5.000 | 0 | | 1 | 0.10 | 5.4884e-02 | 8.028e+02 | 5.000 | 0 | | 2 | 0.06 | 4.7400e-03 | 7.778e+02 | 5.000 | 0 | | 3 | 0.09 | 3.4597e-03 | 7.602e+02 | 5.000 | 0 | | 4 | 0.07 | 3.4662e-03 | 7.430e+02 | 5.000 | 0 | | 5 | 0.08 | 2.9259e-03 | 7.288e+02 | 5.000 | 0 | | 6 | 0.05 | 6.4180e-05 | 7.291e+02 | 5.000 | 0 | =====================================================================================
mdl =
ldaModel with properties:
NumTopics: 20
WordConcentration: 1
TopicConcentration: 5
CorpusTopicProbabilities: [1x20 double]
DocumentTopicProbabilities: [154x20 double]
TopicWordProbabilities: [3092x20 double]
Vocabulary: [1x3092 string]
TopicOrder: 'initial-fit-probability'
FitInfo: [1x1 struct]
Предскажите главные темы для массива новых документов.
newDocuments = tokenizedDocument([
"what's in a name? a rose by any other name would smell as sweet."
"if music be the food of love, play on."]);
topicIdx = predict(mdl,newDocuments)topicIdx = 2×1
19
8
Визуализируйте предсказанные темы с помощью облаков слова.
figure subplot(1,2,1) wordcloud(mdl,topicIdx(1)); title("Topic " + topicIdx(1)) subplot(1,2,2) wordcloud(mdl,topicIdx(2)); title("Topic " + topicIdx(2))

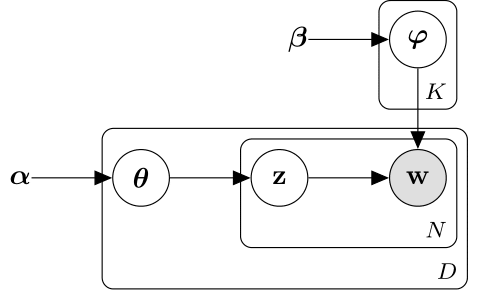
Модель скрытого выделения Дирихле (LDA) является моделью тематики документа, которая обнаруживает базовые темы в наборе документов и выводит вероятности слова в темах. LDA моделирует набор документов D как смеси темы , по темам K, охарактеризованным векторами вероятностей слова . В модели принимается, что смеси темы , и темы следуйте за распределением Дирихле параметрами концентрации и соответственно.
Смеси темы векторы вероятности длины K, где K является количеством тем. Запись вероятность темы i, появляющийся в d th документ. Смеси темы соответствуют строкам DocumentTopicProbabilities свойство ldaModel объект.
Темы векторы вероятности длины V, где V является количеством слов в словаре. Запись соответствует вероятности v th слово словаря, появляющегося в i th тема. Темы соответствуйте столбцам TopicWordProbabilities свойство ldaModel объект.
Учитывая темы и предшествующий Дирихле на смесях темы LDA принимает следующий порождающий процесс для документа:
Произведите смесь темы . Случайная переменная вектор вероятности длины K, где K является количеством тем.
Для каждого слова в документе:
Произведите список тем . z случайной переменной является целым числом от 1 до K, где K является количеством тем.
Произведите слово . w случайной переменной является целым числом от 1 до V, где V является количеством слов в словаре и представляет соответствующее слово в словаре.
При этом порождающем процессе, совместном распределении документа со словами , со смесью темы , и с индексами темы дают
где N является количеством слов в документе. Подведение итогов совместного распределения по z и затем интеграция дает к предельному распределению документа w:
Следующая схема иллюстрирует модель LDA как вероятностную графическую модель. Теневые узлы являются наблюдаемыми переменными, незаштрихованные узлы являются скрытыми переменными, узлы без основ являются параметрами модели. Стрелы подсвечивают, что зависимости между случайными переменными и пластинами указывают на повторенные узлы.
bagOfWords | fitlda | logp | lsaModel | predict | resume | topkwords | transform | wordcloud
