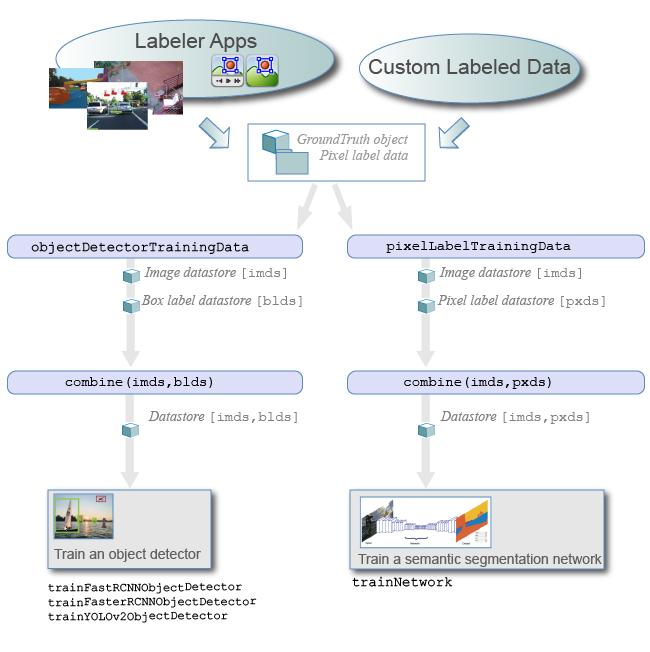
Можно использовать приложение Image Labeler, приложение Video Labeler или приложение Ground Truth Labeler (требует Automated Driving Toolbox™). наряду с объектами Computer Vision Toolbox™ и функциями, чтобы обучить алгоритмы от достоверных данных. Используйте приложение для маркировки, чтобы интерактивно помечать достоверные данные в видео, последовательности изображений, коллекции изображений или пользовательском источнике данных. Используйте маркированные данные, чтобы создать обучающие данные, чтобы обучить детектор объектов или обучить сеть семантической сегментации.
Загрузите данные для маркировки
Image Labeler — Загрузите коллекцию изображений из файла или ImageDatastore объект в приложение.
Video Labeler или Ground Truth Labeler — Загрузите видео, последовательность изображений или пользовательский источник данных в приложение.
Пометьте данные и выберите алгоритм автоматизации: Создайте ROI и метки сцены в рамках приложения. Для получения дополнительной информации см.:
Image Labeler — Запуск с Image Labeler
Video Labeler — Запуск с Video Labeler
Ground Truth Labeler — Запуск с Ground Truth Labeler (Automated Driving Toolbox)
Можно выбрать из одного из встроенных алгоритмов или создать собственный алгоритм, чтобы пометить объекты в данных. Чтобы изучить, как создать ваш собственный алгоритм автоматизации, смотрите, Создают Алгоритм Автоматизации для Маркировки.
Метки экспорта: После маркировки ваших данных можно экспортировать метки в рабочую область или сохранить их в файл. Метки экспортируются как groundTruth объект. Если ваш источник данных состоит из наборов повторного изображения, пометьте целый набор коллекций изображений, чтобы получить массив groundTruth объекты. Для получения дополнительной информации о совместном использовании groundTruth объекты, смотрите Долю, и Хранилище Пометило Ground Truth Data.
Создайте обучающие данные: создать обучающие данные из groundTruth объект, используйте одну из этих функций:
Обучающие данные для детекторов объектов — Использование objectDetectorTrainingData функция.
Обучающие данные для сетей семантической сегментации — Использование pixelLabelTrainingData функция.
Для объектов, созданных с помощью видеофайла или пользовательского источника данных, objectDetectorTrainingData и pixelLabelTrainingData функции пишут изображения в диск для groundTruth. Произведите достоверные данные путем определения фактора выборки. Выборка смягчает перетренировку детектора объектов на подобных выборках.
Алгоритм Обучения:
Детекторы объектов — Использование один из нескольких детекторов объектов Computer Vision Toolbox. Для списка детекторов смотрите, что Обнаружение объектов использует Функции и Обнаружение объектов с помощью Глубокого обучения. Для детекторов объектов, характерных для автоматизированного управления, смотрите детекторы объектов Automated Driving Toolbox, перечисленные в Визуальном Восприятии (Automated Driving Toolbox).
Сеть семантической сегментации — для получения дополнительной информации при обучении сети семантической сегментации, смотрите Начало работы С Семантической Сегментацией Используя Глубокое обучение.
objectDetectorTrainingData | pixelLabelTrainingData | semanticseg | trainACFObjectDetector | trainFasterRCNNObjectDetector | trainRCNNObjectDetector | trainRCNNObjectDetector | trainYOLOv2ObjectDetector