После того, как вы проектируете и отлаживаете функциональность своей модели в Simulink®, тесте и отлаживаете его как приложение реального времени. При тестировании приложения реального времени можно столкнуться с проблемами производительности.
Производительность в реальном времени состоит из шага расчета и пропускной способности.
Шаг расчета относится ко времени, в течение которого приложение реального времени считывает данные в блоки и обрабатывает их. Физические системы имеют свойственный шаг расчета (шаг расчета Найквиста), который основан на физических ограничениях. Например, когда вы используете тормоза в грузовике, инерции пределов грузовика, как быстро дорожная скорость может измениться. Существенное изменение требует приблизительно секунды. Поэтому спидометр не должен производить дорожную скорость чаще, чем каждая десятая часть секунды.
Если данные значительно изменяются между выборками, взятыми в свойственном шаге расчета, шаги расчета дольше, чем тот уровень может пропустить те изменения. Если данные включают нежелательный шум, шаги расчета короче, чем свойственный шаг расчета может получить тот шум.
Пропускная способность относится к тому, сколько данных приложение реального времени может обработать без перегрузки ЦП в данном шаге расчета. Пропускная способность ограничивается ресурсами, которые доступны от целевого компьютера. Шаги расчета, которые слишком коротки, могут перегрузить центральный процессор целевого компьютера и остановить выполнение.
Для получения дополнительной информации см.:
Шаги расчета в системах (Simulink)
Ресурсы целевого компьютера, которые влияют на приложение реального времени, включают:
Циклы ЦП, доступные в многожильных системах
Целевой компьютер скорость доступа RAM
RAM, доступный для псевдодиска
Пропускная способность канала ввода-вывода основной платы и задержка
Пропускная способность памяти на диске и задержка
Многожильный целевой компьютер может улучшить пропускную способность и шаг расчета. Многоядерный компьютер содержит несколько центральных процессоров или ядра, та доля загрузка обработки. В целевом компьютере с четырьмя ядрами, например, следующие задачи могут произойти одновременно на различных ядрах:
Выполните модель, на которую ссылаются,
Получите данные через канал ввода-вывода
Регистрируйте результаты к псевдодиску
Свяжитесь с компьютером разработчика
Стратегия, которую вы используете, чтобы улучшить пропускную способность, зависит от ваших требований прикладной системы.
| Требование прикладной системы | Возможности оборудования | Моделирование стиля | Доступные инструменты |
|---|---|---|---|
Тяжелый ввод-вывод датчика и исполнительного элемента | Быстрые каналы ввода-вывода | Профилировщик Simulink Real-Time™ | |
Тяжелый расчет в реальном времени |
| Режим Polling |
|
Эталонные модели с различными свойственными уровнями | Многоядерные процессоры |
| Simulink Performance Advisor |
Приложения реального времени соединяются сетью |
| Несколько приложений реального времени, которые используют сетевые блоки в коммуникации |
|
Регистрация данных |
|
| Инспектор Данных моделирования в буферизированном режиме |
| Низкоуровневое механическое устройство и электронное управление | FPGA | HDL Workflow Advisor HDL Coder™ |
Можно ли использовать параллелизм, чтобы улучшать производительность в реальном времени, зависит от модели. Например, модель, которая имеет тяжелый поток данных между моделями, на которые ссылаются, ограничивается распространением данных а не обработкой данных. Для получения дополнительной информации см.:
Чтобы использовать параллелизм, сначала преобразуйте блоки на корневом уровне вашей модели в блоки MATLAB System или в модели, на которые ссылаются с блоками Model. Не используйте блоки Subsystem.
Simulink обеспечивает настройки параллелизма в панели Solver под Additional options:
Allow tasks to execute concurrently on target — 'on' (значение по умолчанию) или 'off'. Когда этим параметром является 'on' (значение по умолчанию), ядро выделяет задачи следующему доступному ядру процессора. Для большинства моделей используйте значение по умолчанию.
Когда Allow tasks to execute concurrently on target является 'off', параметр Treat each discrete rate as a separate task доступен. Когда Treat each discrete rate as a separate task является 'off', приложение реального времени выполняется в однозадачном режиме. В однозадачном режиме приложение не использует в своих интересах многожильный целевой компьютер.
В будущем релизе однозадачный режим не будет работать на многоскоростные модели Simulink Real-Time.
Enable explicit model partitioning for concurrent behavior — 'on' или 'off' (значение по умолчанию). Этот параметр доступен, только если Allow tasks to execute concurrently on target является 'on' и вы нажимаете Configure tasks.
Этот сценарий показывает, как использовать свойственный шаг расчета модели и параллелизма, чтобы улучшить шаг расчета и пропускную способность модели. Как часто происходит во время прототипирования, исходная версия является односкоростной моделью. Используя Simulink Performance Advisor и профилировщик, этот сценарий выполняет итерации через эти задачи:
Устранение перегрузок ЦП при выполнении в необходимой области значений шага расчета
Преобразование односкоростной модели к многоскоростному при помощи спецификации проекта
Улучшание многоскоростной производительности при помощи параллелизма с неявным разделением
Рефакторинг многоскоростной модели, чтобы уменьшать требования центрального процессора индивидуума сослался на модели
Улучшание многоскоростной производительности при помощи параллелизма с явным разделением
На каждом этапе вы просматриваете выделение односкоростных и многоскоростных моделей среди ядер многожильного целевого компьютера при помощи функций профилировщика Simulink Real-Time.
Этот сценарий принимает, что вы можете:
Открытый Simulink Real-Time Explorer.
Запустите целевой компьютер.
Соедините Проводник с целевым компьютером.
Создайте и загрузите приложение реального времени на целевой компьютер.
Выполните приложение реального времени на целевом компьютере.
Для получения дополнительной информации см. Похожие темы.
Вы реализовали основную функциональность как односкоростную модель. Чтобы ускорить настройку шага расчета, вы использовали переменную Ts, чтобы задать основной шаг расчета для постоянных блоков в ref1 и ref2 модели, на которые ссылаются.
Вы отладили модель в шаге расчета Ts = 1.0e-3 s. Чтобы соответствовать ее требованию к производительности в реальном времени, эта модель должна достигнуть основного шага расчета в области значений 1.0e-4 ≤ Ts ≤ 3.0e-4 при работе целевого компьютера с четырьмя ядрами.
Протестируйте Против Требования. Чтобы протестировать модель, установите ее основной шаг расчета на верхнюю часть необходимой области значений, 3.0e-4 s.
Чтобы открыть эту модель, откройте эти файлы в последовательности:
Чтобы просмотреть легенду шага расчета, щелкните правой кнопкой по Редактору Simulink и нажмите Sample Time Display> All. Для односкоростной модели цвет легенды шага расчета верхнего уровня применяется ко всем моделям, на которые ссылаются.
Установите Ts = 3.0e-4.
Создайте, загрузите и выполните приложение реального времени.
Приложение реального времени перегружает центральный процессор. Целевой компьютер не имеет достаточного количества циклов ЦП, чтобы полностью выполнить модель в основном шаге расчета.
Определите Минимальный Шаг расчета. Поскольку центральный процессор перегрузился, вы не можете взять базовую линию, пока вы не определили минимальный шаг расчета.
Откройте Performance Advisor. На вкладке Debug нажмите Performance Advisor.
Выберите действие Execute real-time execution.
Выберите и осуществите базовые проверки кроме Real-Time Performance Baseline, включая Determine minimum sample time.
Оцените самый маленький шаг расчета, которого эта модель может достигнуть о 2.2e-3.
Чтобы избежать перегрузок ЦП, вызванных случайными изменениями, установите Ts на значение о 5% выше, чем тот шаг расчета или Ts = 2.3e-3.
Определите Базовую линию. Используя Performance Advisor, установите базовую линию и оцените, возможно ли улучшение для этой версии модели.
В Performance Advisor, запуск Real-Time Performance Baseline.
Запуск следует и производит круговую диаграмму.
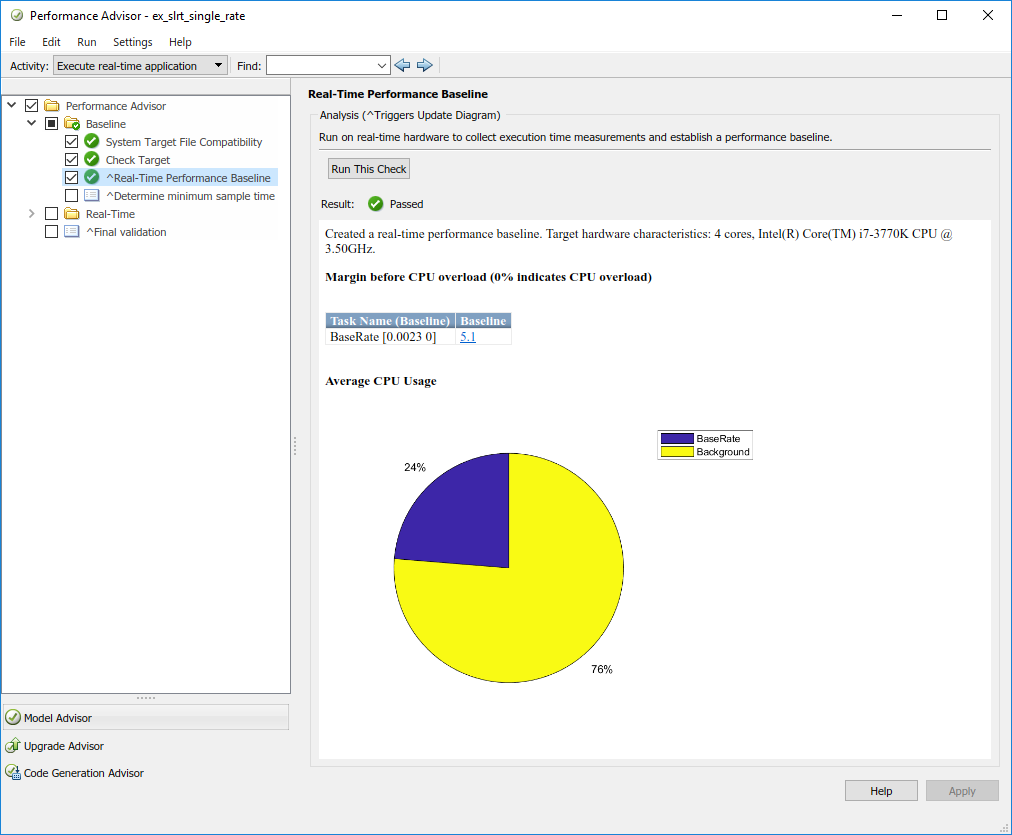
Этот график показывает два выделения использования, BaseRate и Background. BaseRate выделение показывает выполнение односкоростного приложения реального времени как одна задача. Background выделение показывает выполнение задач ядра, таких как доступ к диску целевого компьютера для регистрации данных или передачи между разработкой и целевыми компьютерами.
Этот пример использует целевой компьютер с четырьмя ядрами, но приложение реального времени только использует четверть доступных циклов ЦП. BaseRate имеет низкое поле перед перегрузкой ЦП, о 5%. Чтобы улучшать производительность, приложение реального времени должно использовать больше доступных ресурсов центрального процессора.
Как лучшая практика, осуществите все проверки Real-Time кроме Simscape checks.
Real-Time проверяет передачу. Эта версия модели не может быть улучшена далее.
Оцените Выделение Задачи. Оцените выделение задач через эти четыре ядра.
В Командном окне запустите профилировщик:
tg = slrt; startProfiler(tg); start(tg); stop(tg);
stop функционируйте также вызывает stopProfiler функция.
Получите данные профилировщика и отобразите результаты:
profiler_data = getProfilerData(tg); plot(profiler_data);
Чтобы пропустить инициализацию, запустите отображение в 3*Ts. Чтобы показать представительный пример параллелизма, используйте область значений 4*Ts.
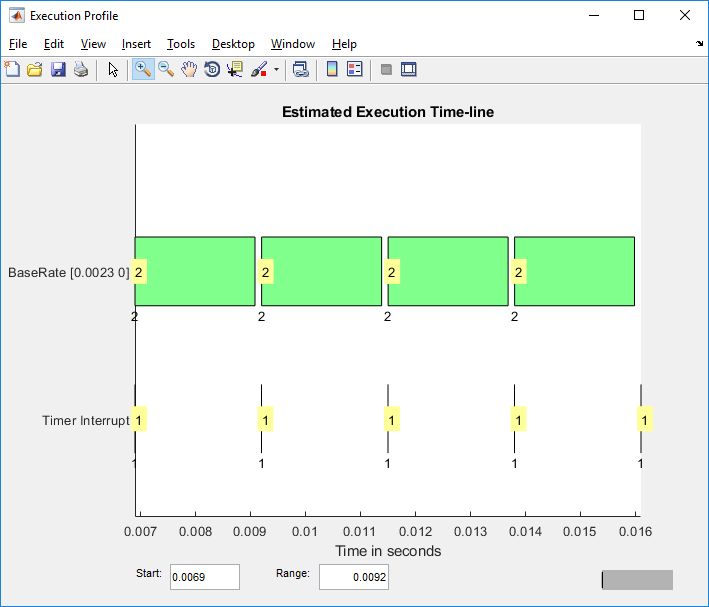
В отображении профилировщика подсвеченные числа в каждой панели задач дают номер задачи. Номер задачи 2 показывает, сколько из доступного времени используется BaseRate задача. Номер задачи 1 прерывание по таймеру, часть фоновых задач.
Метки под панелями задач дают ядро процессора, на котором запускается каждая задача. Поскольку эта модель является односкоростной моделью, задачи модели, на которые ссылаются, запущенные один за другим на базовом 2 на том же уровне после каждого прерывания по таймеру.
Панель выполнения при одном прерывании по таймеру почти заполняет время до следующего прерывания по таймеру. Если панель выполнения в одном прерывании накладывается с панелью выполнения в следующем, выполнении перегрузок ЦП и остановок целевого компьютера.
На этом этапе процесса оптимизации, текущем значении Ts = 2.3e-3, который является вне необходимой области значений 1.0e-4 ≤ Ts ≤ 3.0e-4.
Чтобы улучшить шаг расчета приложения реального времени, запустите со свойственных уровней модели. После преобразования односкоростной модели к многоскоростной модели можно включить параллелизм с неявным разделением.
Преобразуйте в Многоскоростную модель. От спецификации проекта определите, какие части модели могут запуститься на более низких уровнях и который не может.
Задайте уровни для частей модели.
Как лучшая практика, задайте уровни, которые являются множителями одной базовой ставки. В этой модели допустимые уровни являются множителями Ts: Ts, 2*Ts, 3*Ts, и 4*Ts.
В исходной модели, Ref1/Out4 подключения непосредственно к Ref2/In1. Поскольку Ref1/Out4 и Ref2/In1 имейте различные уровни, добавьте блок Rate Transition в Ref1.
Сконфигурируйте блок Rate Transition:
Установите параметр Ensure data integrity during data transfer.
Очистите параметр Ensure deterministic data transfer (maximum delay).
Передачи данных между инициированными задачами не могут потребовать детерминированной целостности данных.
Чтобы открыть эту модель, откройте эти файлы в последовательности:
Для этой модели цвета легенды шага расчета для верхнего уровня также применяются к Ref1 модель, на которую ссылаются. Отдельный набор цветов легенды шага расчета появляется для Ref2 модель, на которую ссылаются.
Сконфигурируйте Неявное Разделение. Чтобы сконфигурировать неявное разделение, включите параллелизм уровня задачи и возьмите значения по умолчанию.
Откройте Параметры конфигурации для модели верхнего уровня. На вкладке Real-Time нажмите Hardware Settings.
Выберите Solver> Allow tasks to execute concurrently on target.
На вкладке Simulation нажмите Prepare> Update Model.
Протестируйте Против Требования. Чтобы протестировать модель, установите ее основной шаг расчета на верхнюю часть необходимой области значений, 3.0e-4 s.
Установите Ts = 3.0e-4.
Создайте, загрузите и выполните приложение реального времени.
Приложение реального времени перегружает центральный процессор. Целевой компьютер не имеет достаточного количества циклов ЦП, чтобы полностью выполнить модель в основном шаге расчета.
Определите Минимальный Шаг расчета. Поскольку центральный процессор перегрузился, вы не можете взять базовую линию, пока вы не определили минимальный шаг расчета.
Откройте Performance Advisor. На вкладке Debug нажмите Performance Advisor.
Выберите действие Execute real-time execution.
Выберите и осуществите базовые проверки кроме Real-Time Performance Baseline, включая Determine minimum sample time.
Оцените самый маленький шаг расчета, которого эта модель может достигнуть о 4.2e-4.
Чтобы избежать перегрузок ЦП, вызванных случайными изменениями, установите Ts на значение о 5% выше, чем тот шаг расчета или Ts = 4.4e-4.
Определите Базовую линию. Используя Performance Advisor, установите базовую линию и оцените, возможно ли улучшение для этой версии модели.
Чтобы взять базовую линию для оптимизации, запустите Real-Time Performance Baseline.
Запуск следует и производит круговую диаграмму.
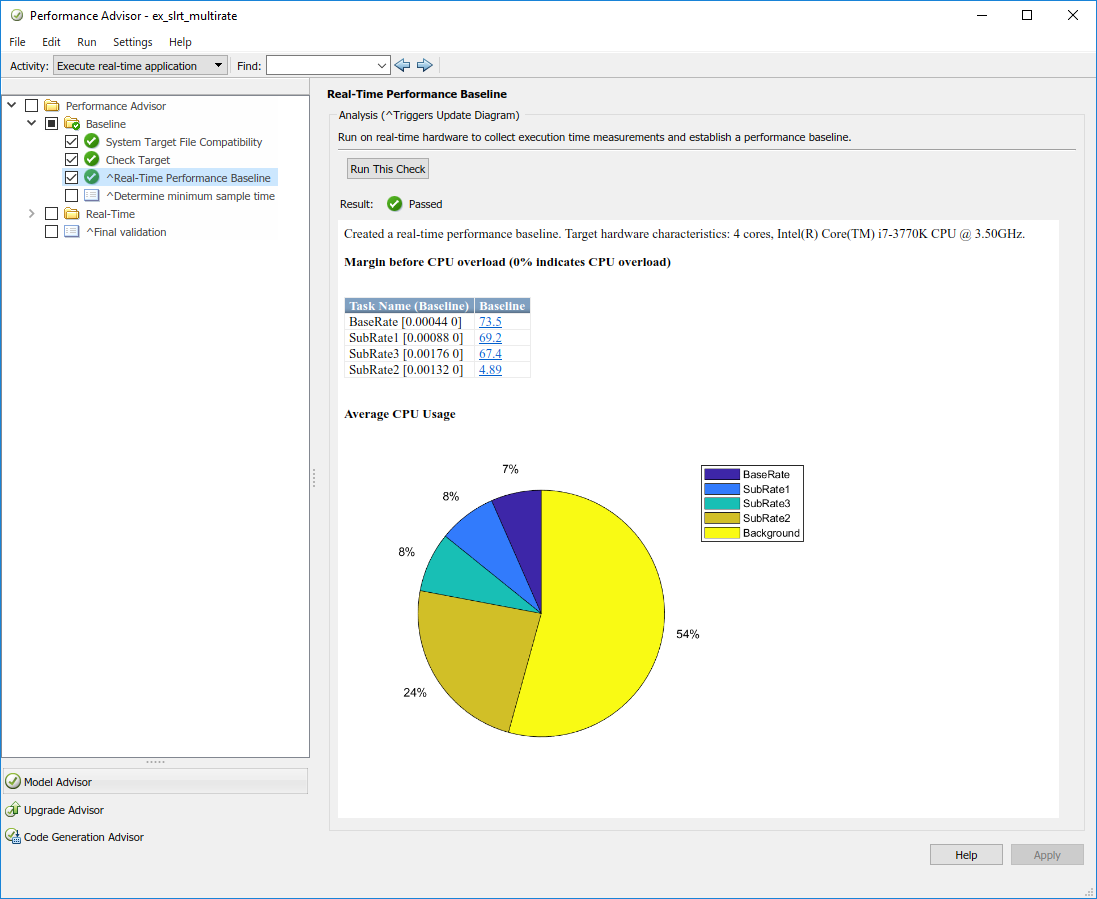
Использование ядра процессора улучшилось, но приложение реального времени только использует половину доступных циклов ЦП. Кроме того, SubRate2 имеет низкое поле перед перегрузкой ЦП, о 5%. Для приложения реального времени нужно лучшее выравнивание нагрузки, чтобы улучшить основной шаг расчета и сделать его выполнение более вероятно, чтобы успешно выполниться.
Как лучшая практика, осуществите все проверки Real-Time кроме Simscape checks.
Real-Time проверяет передачу. Эта версия модели не может быть улучшена далее.
Оцените Выделение Задачи. Оцените выделение задач через эти четыре ядра.
В Командном окне запустите профилировщик:
tg = slrt; startProfiler(tg); start(tg); stop(tg);
Получите данные профилировщика и отобразите результаты:
profiler_data = getProfilerData(tg); plot(profiler_data);
Чтобы пропустить инициализацию, запустите отображение в 3*Ts. Чтобы показать представительный пример параллелизма, используйте область значений 4*Ts.
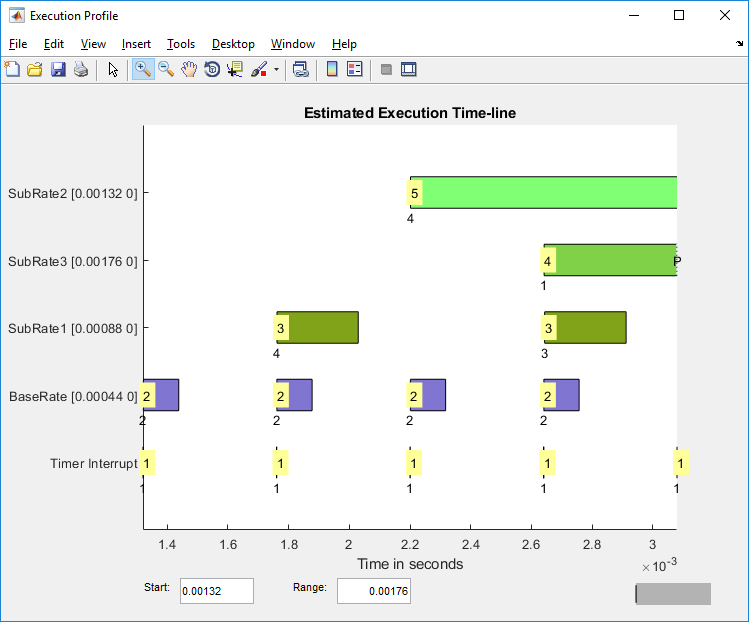
Панели выполнения для SubRate2, задача с самым большим требованием центрального процессора, почти наложитесь. Параллелизм находится в полной операции с метки деления времени 1.32e-3.
На этом этапе процесса оптимизации, текущем значении Ts = 4.4e-4, который является все еще вне необходимой области значений 1.0e-4 ≤ Ts ≤ 3.0e-4.
Можно улучшать производительность приложения реального времени путем явной балансировки загрузки различных процессорных узлов в многожильном целевом компьютере. Этот процесс включает итеративно рефакторинг модели, движущихся задач между различными процессорными узлами и тестирования результата. Для получения дополнительной информации смотрите Концепции в Многоядерном программировании (Simulink).
Прежде, чем осуществить рефакторинг модель, отметьте, какие задачи системы зависят от выхода других задач. Зависимость по данным между задачами определяет их порядок выполнения во временном шаге. Два или больше раздела, содержащие зависимости по данным в цикле, создают цикл зависимости по данным, также известный как алгебраический цикл. Чтобы обнаружить эти циклы, в панели Diagnostics, устанавливают параметр Algebraic loop на error. Simulink идентифицирует алгебраические циклы во время выполнения, отображает сообщение об ошибке и подсвечивает фрагмент блок-схемы, которая включает цикл. Удалите эти циклы из своей модели. Для получения дополнительной информации смотрите Алгебраический цикл (Simulink).
Осуществите рефакторинг Модель. В этом сценарии многоскоростная модель состоит из двух моделей, на которые ссылаются, каждый содержащий много сигналов обработать во время каждого шага расчета. С неявным разделением каждая задача модели, на которую ссылаются, присвоена ядру. Чтобы улучшить перемежение среди ядер процессора, разделите каждую модель, на которую ссылаются пополам. Каждая половина содержит половину количества сигналов в исходной модели, на которую ссылаются. Эта настройка производит то же количество моделей, на которые ссылаются, как ядра с каждой моделью, на которую ссылаются, имеющей меньшие требования центрального процессора, чем оригинал.
Разделите Ref1 модели, на которые ссылаются, в две модели, на которые ссылаются, Ref1A и Ref1B. Каждый блок имеет половину количества сигналов как Ref1.
Разделите Ref2 модели, на которые ссылаются, в две модели, на которые ссылаются, Ref2A и Ref2B. Каждый блок имеет половину количества сигналов как Ref2.
Чтобы открыть эту модель, откройте эти файлы в последовательности:
Сконфигурируйте Явное Разделение. Чтобы сконфигурировать явное разделение, включите параллелизм уровня задачи и явным образом сконфигурируйте задачи для каждой модели, на которую ссылаются. Явное разделение может увеличить перемежение центрального процессора задач в реальном времени.
Откройте Параметры конфигурации для модели верхнего уровня. На вкладке Real-Time нажмите Hardware Settings.
Выберите Solver> Allow tasks to execute concurrently on target.
Нажмите Configure Tasks, и затем выберите Enable explicit model partitioning for concurrent behavior.
Под Concurrent Execution> Tasks and Mapping, откройте CPU> Periodic.
Создайте периодические задачи для каждого уровня в каждой модели, на которую ссылаются. Назовите задачи Model1_R1, Model1_R2, и так далее.
Вы используете периодический триггер, чтобы представлять периодические источники прерывания, такие как таймер. Периодичность триггера является или базовой ставкой задачи или периодом триггера. Смотрите Концепции в Многоядерном программировании (Simulink).
Присвойте каждую периодическую задачу соответствующему уровню в каждой модели, на которую ссылаются.
Model1, Model3 — Четыре задачи уровней Ts, 2*Ts, 3*Ts, и 4*Ts.
Model2, Model4 — Три задачи уровней Ts, 3*Ts, и 4*Ts
В конце этого процесса окно Concurrent Execution похоже на фигуру.
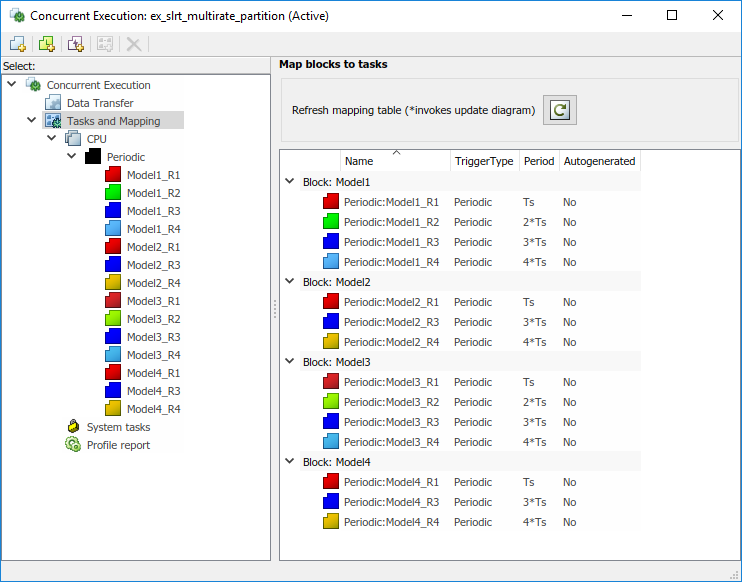
На вкладке Simulation нажмите Prepare> Update Model.
Для этой модели цвета легенды шага расчета для верхнего уровня также применяются к Ref1A и Ref1B модели, на которые ссылаются. Отдельный набор цветов легенды шага расчета появляется для Ref2A и Ref2B модели, на которые ссылаются.
Протестируйте Против Требования. Чтобы протестировать модель, установите ее основной шаг расчета на верхнюю часть необходимой области значений, 3.0e-4 s.
Установите Ts = 3.0e-4.
Создайте, загрузите и выполните приложение реального времени.
Запуски приложения реального времени. Ваша модель удовлетворила основное требование шага расчета.
Определите Минимальный Шаг расчета. Чтобы оценить, где эта версия модели падает в области значений шага расчета и сколько поля это имеет:
Откройте Performance Advisor. На вкладке Debug нажмите Performance Advisor.
Выберите действие Execute real-time execution.
Выберите и осуществите базовые проверки кроме Real-Time Performance Baseline, включая Determine minimum sample time. Вы не можете взять базовую линию, пока вы не определили минимальный шаг расчета.
Оцените самый маленький шаг расчета, которого эта модель может достигнуть о 2.6e-4.
Чтобы избежать перегрузок ЦП, вызванных случайными изменениями, установите Ts на значение о 5% выше, чем тот шаг расчета или Ts = 2.7e-4.
Определите Базовую линию. Используя Performance Advisor, установите базовую линию и оцените, возможно ли улучшение для этой версии модели.
Чтобы взять базовую линию, запустите Real-Time Performance Baseline.
Запуск следует и производит выход как фигура.
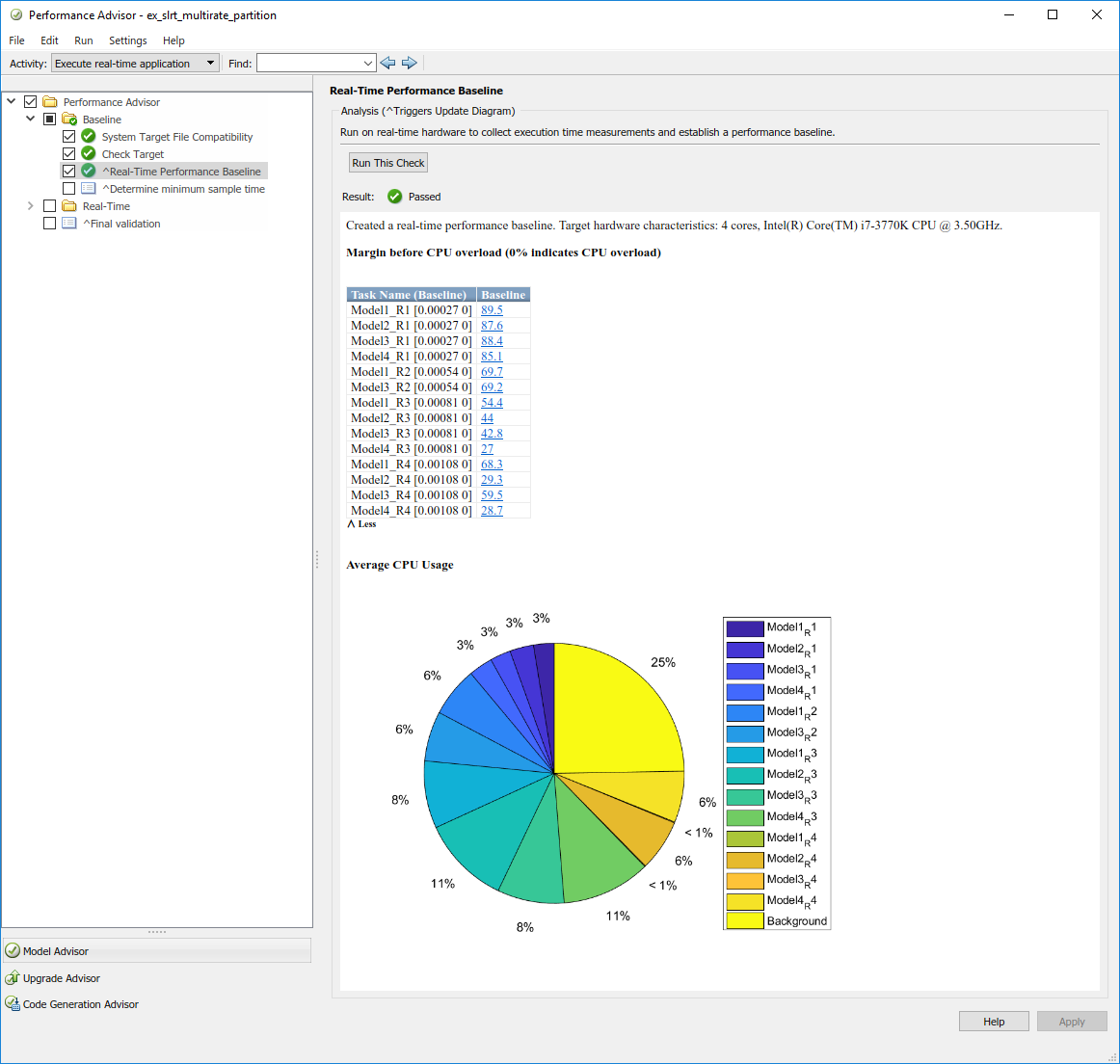
В самом низком достижимом шаге расчета это приложение реального времени использует три четверти доступных циклов ЦП. Самое маленькое поле перед перегрузкой ЦП о 27%, который является улучшением по сравнению с 5% поле в предыдущей версии.
Как лучшая практика, осуществите все проверки Real-Time кроме Simscape checks.
Real-Time проверяет передачу. Эта версия модели не может быть улучшена далее.
Оцените Выделение Задачи. Оцените выделение задач через эти четыре ядра.
В Командном окне запустите профилировщик:
tg = slrt; startProfiler(tg); start(tg); stop(tg);
Получите данные профилировщика и отобразите результаты:
profiler_data = getProfilerData(tg); plot(profiler_data);
Чтобы пропустить инициализацию, запустите отображение в 3*Ts. Чтобы показать представительный пример параллелизма, используйте область значений 4*Ts.
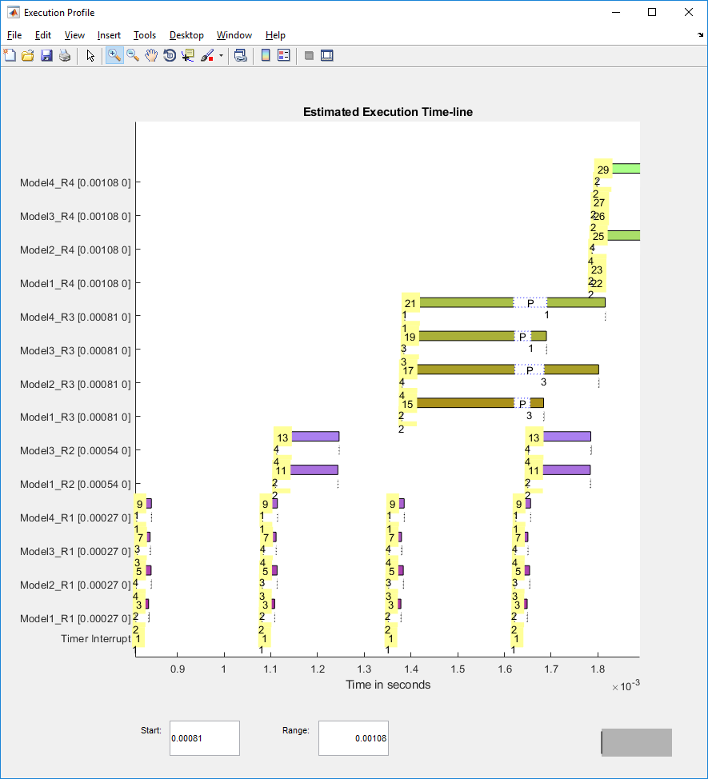
Model*_R3 задачи начинают работать на всех четырех процессорах, но Model*_R1 задачи вытесняют их. Издержки вытеснения ограничивают повышение производительности, которого можно достигнуть при помощи одного только параллелизма.
В сценарии модели изменение, которое произвело самое большое улучшение, шло от односкоростного до многоскоростного выполнения с отображением задачи по умолчанию (по 5X улучшение). Другая оптимизация произвела меньше улучшения (1.5X), но потребовался, чтобы достигать необходимого шага расчета 1.0e-4 ≤ Ts ≤ 3.0e-4.
| Оптимизация | Достижимый шаг расчета Ts |
|---|---|
| Односкоростной | 2.3e-3 |
| Многоскоростное, неявное отображение задачи | 4.4e-4 |
| Разделенное многоскоростное, явное отображение задачи | 2.7e-4 |
Чтобы получить больше улучшения, рассмотрите следующую оптимизацию.
Если многоскоростная модель содержит много блоков перехода уровня, покрывающих несколько перекрывающихся уровней, рассмотрите извлечение каждого подобного перехода уровня в новую модель, на которую ссылаются. Можно затем установить параметр Enable explicit model partitioning for concurrent behavior и создать явное периодическое отображение задачи для новых моделей, на которые ссылаются. Если модель, на которую ссылаются, не содержит блок с шагом расчета тарифной ставки, добавьте отдельную задачу тарифной ставки в таблицу отображения для той модели.
Для этой модели, факторизуя переходы уровня обеспечивает только маленькое улучшение. Открыть ex_slrt_multirate_refactor, откройте эти файлы в последовательности:
Если модель является односкоростной моделью с высоким вычислительным требованием для каждой модели, на которую ссылаются, без зависимостей по данным между ними, рассмотрите установку параметра Enable explicit model partitioning for concurrent behavior. Можно затем создать явное периодическое отображение задачи для каждой из моделей, на которые ссылаются.
Улучшение, которого можно достигнуть путем явного отображения задач односкоростной модели, ограничивается количеством ядер. Например, если у вас есть четыре ядра и задачи, запущенные на одном уровне, большинством, которого можно достигнуть, является 4X улучшение использования ЦП.
Чтобы найти дополнительную оптимизацию, считайте выполнение профилировщика Simulink Real-Time с функциональным логгированием времени выполнения включенным (см. Профилирование и Оптимизацию). Профилировщик предоставляет подробную, низкоуровневую информацию о задачах центрального процессора. Можно затем идентифицировать блоки узкого места и заменить или улучшить их.
В случаях, где вы не можете соответствовать своим системным требованиям другими методами оптимизации, рассмотрите встраивание решающих алгоритмов в FPGA при помощи HDL Workflow Advisor HDL Coder.
Enable Profiler | Profiler Data | Rate Transition | SimulinkRealTime.utils.minimumSampleTime | getProfilerData | resetProfiler | startProfiler | stopProfiler
