Обнаружьте контуры речи в звуковом сигнале
idx = detectSpeech(audioIn,fs,Name,Value)Name,Value парные аргументы.
detectSpeech(audioIn,fs,'Window',hann(512,'periodic'),'OverlapLength',256) обнаруживает речь с помощью периодического окна Hann с 512 точками с перекрытием с 256 точками.[ также возвращается, пороги использовались для расчета контуров речи.idx,thresholds] = detectSpeech(___)
detectSpeech(___) без выходных аргументов отображает график обнаруженных речевых областей во входном сигнале.
Читайте в звуковом сигнале. Отсеките звуковой сигнал к 20 секундам.
[audioIn,fs] = audioread('Rainbow-16-8-mono-114secs.wav');
audioIn = audioIn(1:20*fs);Вызовите detectSpeech. Не задайте выходные аргументы, чтобы отобразить график обнаруженных речевых областей.
detectSpeech(audioIn,fs);

detectSpeech функционируйте использует алгоритм пороговой обработки на основе энергии и спектрального распространения на аналитическую систему координат. Можно изменить Window, OverlapLength, и MergeDistance подстраивать алгоритм для ваших определенных потребностей.
windowDuration =0.074; % seconds numWindowSamples = вокруг (windowDuration*fs); победите = hamming (numWindowSamples,'periodic'); percentOverlap =
35; перекройтесь = раунд (numWindowSamples*percentOverlap/100); mergeDuration =
0.44; mergeDist = вокруг (mergeDuration*fs); detectSpeech (audioIn, фс,"Window", победите,"OverlapLength", перекройтесь,"MergeDistance", mergeDist)

Читайте в звуковом файле, содержащем речь. Разделите звуковой сигнал в первую половину и вторую половину.
[audioIn,fs] = audioread('Counting-16-44p1-mono-15secs.wav');
firstHalf = audioIn(1:floor(numel(audioIn)/2));
secondHalf = audioIn(numel(firstHalf):end);Вызовите detectSpeech на первой половине звукового сигнала. Задайте два выходных аргумента, чтобы возвратить индексы, соответствующие областям обнаруженной речи и порогам, используемым в решении.
[speechIndices,thresholds] = detectSpeech(firstHalf,fs);
Вызовите detectSpeech на второй половине без выходных аргументов, чтобы построить области обнаруженной речи. Задайте пороги, определенные от предыдущего вызова до detectSpeech.
detectSpeech(secondHalf,fs,'Thresholds',thresholds)
Работа с большими наборами данных
Многократное использование речевых порогов обнаружения обеспечивает значительный вычислительный КПД, когда вы работаете с большими наборами данных, или когда вы развертываете глубокое обучение или конвейер машинного обучения для вывода в реальном времени. Загрузите и извлеките набор данных [1].
url = 'https://storage.googleapis.com/download.tensorflow.org/data/speech_commands_v0.01.tar.gz'; downloadFolder = tempdir; datasetFolder = fullfile(downloadFolder,'google_speech'); if ~exist(datasetFolder,'dir') disp('Downloading data set (1.9 GB) ...') untar(url,datasetFolder) end
Создайте аудио datastore, чтобы указать на записи. Используйте имена папок в качестве меток.
ads = audioDatastore(datasetFolder,'IncludeSubfolders',true,'LabelSource','foldernames');
Уменьшайте набор данных на 95% в целях этого примера.
ads = splitEachLabel(ads,0.05,'Exclude','_background_noise');
Создайте два хранилища данных: один для обучения и один для тестирования.
[adsTrain,adsTest] = splitEachLabel(ads,0.8);
Вычислите средние пороги по обучающему набору данных.
thresholds = zeros(numel(adsTrain.Files),2); for ii = 1:numel(adsTrain.Files) [audioIn,adsInfo] = read(adsTrain); [~,thresholds(ii,:)] = detectSpeech(audioIn,adsInfo.SampleRate); end thresholdAverage = mean(thresholds,1);
Используйте предварительно вычисленные пороги, чтобы обнаружить речевые области на файлах от набора тестовых данных. Постройте обнаруженную область для трех файлов.
[audioIn,adsInfo] = read(adsTest);
detectSpeech(audioIn,adsInfo.SampleRate,'Thresholds',thresholdAverage);
[audioIn,adsInfo] = read(adsTest);
detectSpeech(audioIn,adsInfo.SampleRate,'Thresholds',thresholdAverage);
[audioIn,adsInfo] = read(adsTest);
detectSpeech(audioIn,adsInfo.SampleRate,'Thresholds',thresholdAverage);
Ссылки
[1] Начальник, Пит. "Речевые команды: общедоступный набор данных для распознавания речи отдельного слова". Распределенный TensorFlow. Приписывание Creative Commons 4.0 лицензии.
Читайте в звуковом файле и слушайте его. Постройте spectrogram.
[audioIn,fs] = audioread('Counting-16-44p1-mono-15secs.wav'); sound(audioIn,fs) spectrogram(audioIn,hann(1024,'periodic'),512,1024,fs,'yaxis')

Для приложений машинного обучения вы часто хотите извлечь функции из звукового сигнала. Вызовите spectralEntropy функция на звуковом сигнале, затем постройте histogram отобразить распределение спектральной энтропии.
entropy = spectralEntropy(audioIn,fs); numBins = 40; histogram(entropy,numBins,'Normalization','probability') title('Spectral Entropy of Audio Signal')

В зависимости от вашего приложения вы можете хотеть извлечь спектральную энтропию только из областей речи. Получившиеся статистические данные являются более характеристическими для динамика и менее характеристическими для канала. Вызовите detectSpeech на звуковом сигнале и затем создают новый сигнал, который содержит только области обнаруженной речи.
speechIndices = detectSpeech(audioIn,fs); speechSignal = []; for ii = 1:size(speechIndices,1) speechSignal = [speechSignal;audioIn(speechIndices(ii,1):speechIndices(ii,2))]; end
Слушайте речь, сигнализируют и строят спектрограмму.
sound(speechSignal,fs) spectrogram(speechSignal,hann(1024,'periodic'),512,1024,fs,'yaxis')

Вызовите spectralEntropy функция на речевом сигнале и затем строит histogram отобразить распределение спектральной энтропии.
entropy = spectralEntropy(speechSignal,fs); histogram(entropy,numBins,'Normalization','probability') title('Spectral Entropy of Speech Signal')

detectSpeech алгоритм основан [1], несмотря на то, что изменено так, чтобы статистические данные к порогу были краткосрочной энергией и спектральным распространением вместо краткосрочной энергии и спектральным центроидом. Схема и шаги предоставляют общий обзор алгоритма. Для получения дополнительной информации см. [1].
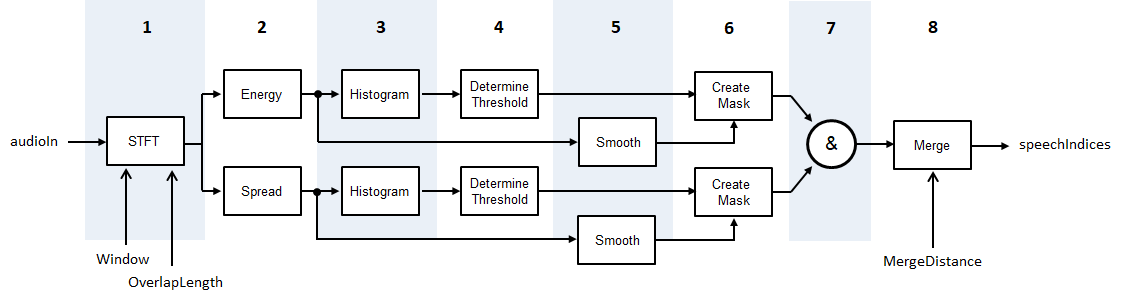
Звуковой сигнал преобразован в представление частоты времени с помощью заданного Window и OverlapLength.
Краткосрочная энергия и спектральное распространение вычисляются для каждой системы координат. Спектральное распространение вычисляется согласно spectralSpread.
Гистограммы создаются и для краткосрочной энергии и для спектральных распределений распространения.
Для каждой гистограммы порог определяется согласно , где M 1 и M 2 является первыми и вторыми локальными максимумами, соответственно. W установлен в 5.
И спектральное распространение и краткосрочная энергия сглаживаются через время путем прохождения через последовательные движущиеся средние фильтры с пятью элементами.
Маски создаются путем сравнения краткосрочной энергии и спектрального распространения с их соответствующими порогами. Чтобы объявить систему координат как содержащий речь, функция должна быть выше ее порога.
Маски объединены. Для системы координат, которая будет объявлена как речь, и краткосрочная энергия и спектральное распространение должны быть выше их соответствующих порогов.
Области, объявленные как речь, объединены, если расстояние между ними меньше MergeDistance.
[1] Джиэннэкопулос, Теодорос. "Метод для удаления тишины и сегментации речевых сигналов, реализованных в MATLAB", (Университет Афин, Афин, 2009).
