FTDNN имел коснувшуюся память линии задержки только во входе к первому слою статической сети feedforward. Можно также распределить коснувшиеся линии задержки в сети. Распределенный TDNN был сначала введен в [WaHa89] для распознавания фонемы. Исходная архитектура была очень специализированной для той конкретной проблемы. Следующий рисунок показывает, что общий 2D слой распределил TDNN.
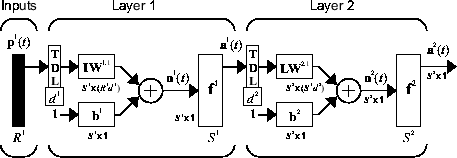
Эта сеть может использоваться в упрощенной проблеме, которая похожа на распознавание фонемы. Сеть попытается распознать содержимое частоты входного сигнала. Следующий рисунок показывает сигнал, в котором одна из двух частот присутствует в любой момент времени.
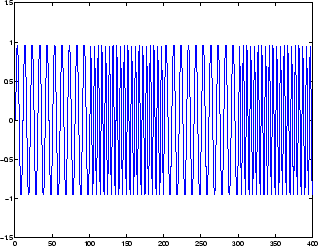
Следующий код создает этот сигнал и целевой сетевой выход. Целевой выход равняется 1, когда вход в низкой частоте и-1, когда вход в высокой частоте.
time = 0:99; y1 = sin(2*pi*time/10); y2 = sin(2*pi*time/5); y = [y1 y2 y1 y2]; t1 = ones(1,100); t2 = -ones(1,100); t = [t1 t2 t1 t2];
Теперь создайте распределенную сеть TDNN с distdelaynet функция. Единственная разница между distdelaynet функционируйте и timedelaynet функция состоит в том, что первый входной параметр является массивом ячеек, который содержит коснувшиеся задержки, которые будут использоваться в каждом слое. В следующем примере задержки нуля к четыре используются в слое 1, и нуль к три используются в слое 2. (Чтобы добавить некоторое разнообразие, учебный функциональный trainbr используется в этом примере вместо значения по умолчанию, которое является trainlm. Можно использовать любую учебную функцию, обсужденную в Многоуровневых Мелких Нейронных сетях и Обучении Обратной связи.)
d1 = 0:4;
d2 = 0:3;
p = con2seq(y);
t = con2seq(t);
dtdnn_net = distdelaynet({d1,d2},5);
dtdnn_net.trainFcn = 'trainbr';
dtdnn_net.divideFcn = '';
dtdnn_net.trainParam.epochs = 100;
dtdnn_net = train(dtdnn_net,p,t);
yp = sim(dtdnn_net,p);
plotresponse(t,yp)
Сеть может точно отличить эти две “фонемы”.
Вы заметите, что обучение обычно медленнее для распределенной сети TDNN, чем для FTDNN. Это вызвано тем, что распределенный TDNN должен использовать динамическую обратную связь.
