Пользовательский интерфейс Basic Fitting MATLAB® позволяет вам в интерактивном режиме:
Подбор модели по данным с помощью сплайн интерполяции, кубической Эрмитовой интерполяции или многочлена до десятой степени включительно
Построение графика одной или нескольких моделей с данными
Постройте остаточные значения подгонок
Вычисление коэффициентов модели
Вычислите норму остаточных значений (статистическая величина, которую можно использовать, чтобы анализировать, как хорошо модель соответствует данным),
Используйте модель, чтобы интерполировать или экстраполировать за пределами данных
Сохраните коэффициенты и вычисленные значения к рабочему пространству MATLAB для использования за пределами диалогового окна
Сгенерируйте код MATLAB, чтобы повторно вычислить модель и воспроизвести графики с новыми данными
Пользовательский интерфейс Basic Fitting только доступен для 2D графиков. Для более усовершенствованного подбора кривой и регрессионного анализа, см. документацию Curve Fitting Toolbox™ и документацию Statistics and Machine Learning Toolbox™.
Пользовательский интерфейс Basic Fitting сортирует ваши данные в порядке возрастания перед подбором кривой. Если ваш набор данных будет большим, и значения не сортируются в порядке возрастания, у Пользовательского интерфейса Basic Fitting займет больше времени предварительно обработать ваши данные перед подбором кривой.
Можно ускорить Пользовательский интерфейс Basic Fitting первой сортировкой данных. Создать отсортированные векторы x_sorted и y_sorted от векторов данных x и y, используйте sort MATLAB функция:
[x_sorted, i] = sort(x); y_sorted = y(i);
Чтобы использовать Пользовательский интерфейс Basic Fitting, необходимо сначала отобразить данные на графике в окне рисунка, с помощью любого MATLAB, строящего команду, которая производит (только) данные о X и Y.
Чтобы открыть Пользовательский интерфейс Basic Fitting, выберите Tools > Basic Fitting из меню наверху окна рисунка.
В этом примере показано, как использовать Пользовательский интерфейс Basic Fitting, чтобы соответствовать, визуализировать, анализировать, сохранить и сгенерировать код для параболических регрессий.
Файл census.mat содержит американские данные о населении в течение лет 1790 - 1990 в 10-летних интервалах.
Чтобы загрузить и отобразить данные на графике, введите следующие команды в посдказке MATLAB:
load census plot(cdate,pop,'ro')
load команда добавляет следующие переменные в рабочее пространство MATLAB:
cdate — Вектор-столбец, содержащий годы от 1 790 до 1990 с шагом 10. Это - переменный предиктор.
pop — Вектор-столбец с американским населением в течение каждого года в cdate. Это - переменная отклика.
Векторы данных сортируются в порядке возрастания по годам. График показывает население функцией года.
Теперь вы готовы подогнать под уравнение данные для моделирования роста населения с течением времени.
Откройте диалоговое окно Basic Fitting путем выбора Tools > Basic Fitting в Окне рисунка.
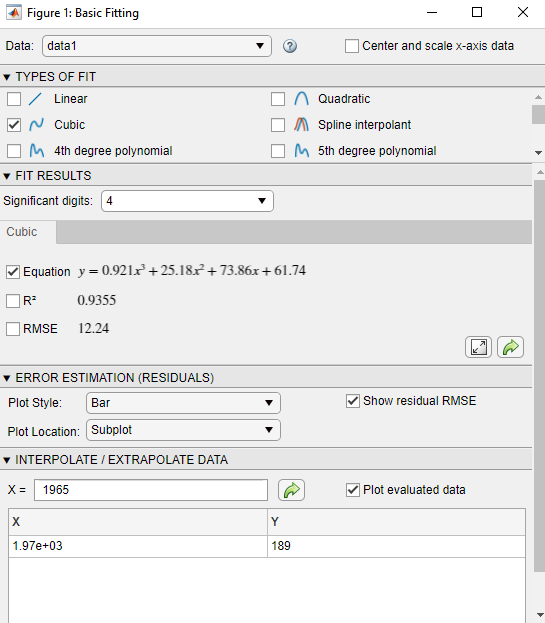
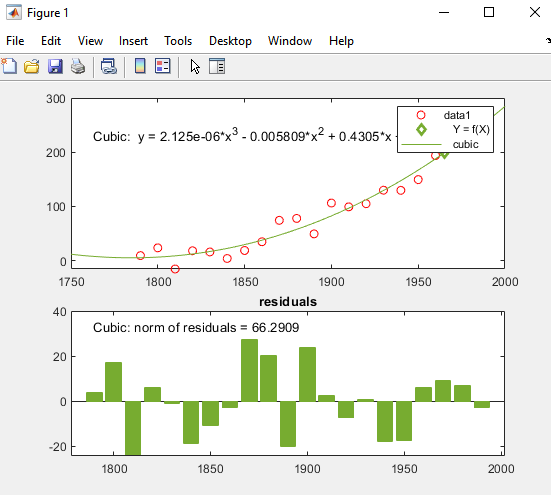
В области TYPES OF FIT диалогового окна Basic Fitting установите флажок Cubic, чтобы соответствовать кубическому полиному к данным.
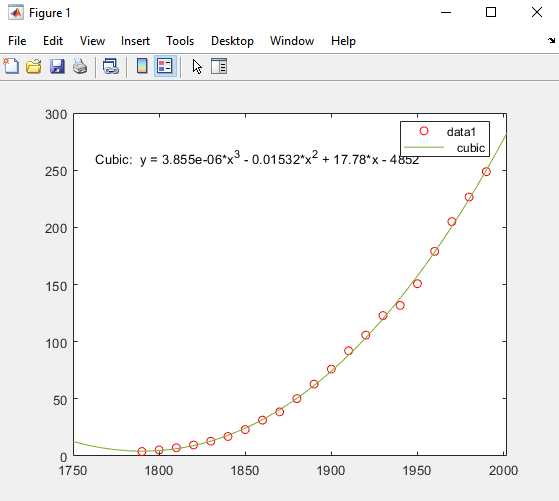
MATLAB использует ваш выбор, чтобы соответствовать данным и добавляет кубическую линию регрессии в график можно следующим образом.
При расчете модели MATLAB сталкивается с проблемами и выдает следующее предупреждение:
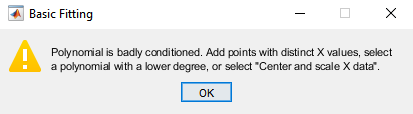
Это предупреждение указывает, что вычисленные коэффициенты для модели чувствительны к случайным ошибкам в ответе (измеренное население). Это также предлагает некоторые вещи, которые можно сделать, чтобы получить лучшую подгонку.
Продолжите использовать кубический полином. Поскольку вы не можете добавить новые наблюдения к данным переписи, улучшите подгонку, преобразовав значения, которые у вас есть, в z-оценки перед пересчетом подгонки. Установите флажок Center and scale x-axis data в правом верхнем из диалогового окна, чтобы заставить инструмент Basic Fitting выполнить преобразование.
Чтобы изучить, как центрирование и масштабирование данных работают, смотрите Узнать, как Basic Fitting Tool Computes Fits.
Под ERROR ESTIMATION (RESIDUALS) установите флажок Show residual RMSE. Выберите Bar как Plot Style.
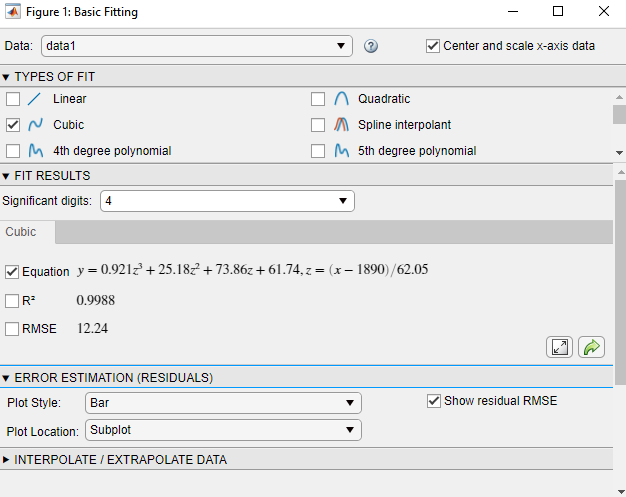
Выбор этих опций создает подграфик остаточных значений как столбчатый график.
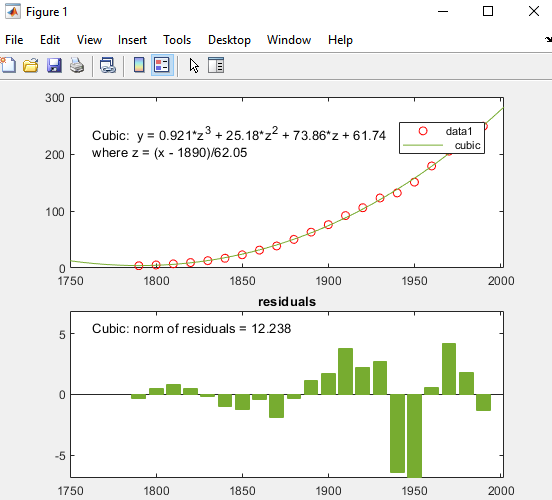
Кубическое соответствие является плохим предиктором перед годом 1790, где это указывает на уменьшающееся население. Модель, кажется, аппроксимирует данные обоснованно много позже 1790. Однако шаблон в остаточных значениях показывает, что модель не соответствует предположению о нормальной ошибке, которая является основанием для подбора кривой наименьших квадратов. Линией data 1, идентифицированной в легенде, является наблюдаемый x (cdate) и y (pop) значения данных. Линия регрессии Cubic представляет подгонку после центрирования и масштабирования значений данных. Заметьте, что рисунок показывает исходные модули данных, даже при том, что инструмент вычисляет подгонку с помощью преобразованных z-баллов.
Для сравнения попробуйте подбор другого полиномиального уравнения к данным о переписи путем выбора его в области TYPES OF FIT.
В диалоговом окне Basic Fitting нажмите кнопку Expand Results![]() , чтобы отобразить предполагаемые коэффициенты и RMSE.
, чтобы отобразить предполагаемые коэффициенты и RMSE.
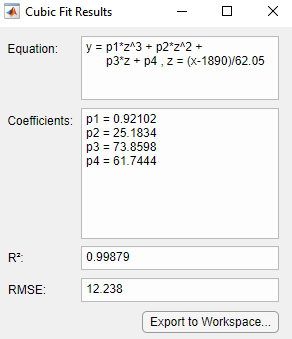
Сохраните данные подгонки в рабочее пространство MATLAB путем нажатия кнопки Export to Workspace на Числовой панели результатов. Диалоговое окно Save Fit to Workspace открывается.
Со всеми установленными флажками нажмите OK, чтобы сохранить подходящие параметры как структуру MATLAB fit:
fit
fit =
struct with fields:
type: 'polynomial degree 3'
coeff: [0.9210 25.1834 73.8598 61.7444]Теперь можно использовать результаты подгонки в программировании MATLAB, за пределами Пользовательского интерфейса Basic Fitting.
Можно получить индикацию относительно того, как хорошо параболическая регрессия предсказывает наблюдаемые данные путем вычисления coefficient of determination, или R-square (записанный как R2). Статистическая величина R2, которая лежит в диапазоне от 0 до 1, меры, насколько полезный независимая переменная находится в предсказании значений зависимой переменной:
Значение R2 около 0 указывает, что подгонка не намного лучше, чем модель y = constant.
Значение R2 около 1 указывает, что независимая переменная объясняет большую часть изменчивости в зависимой переменной.
R2 вычисляется из residuals, различий со знаком между наблюдаемым зависимым значением и значением, которое ваша подгонка предсказывает для него.
| остаточные значения = yobserved - yfitted | (1) |
Номер R2 для кубического соответствия в этом примере, 0.9988, расположен под FIT RESULTS в диалоговом окне Basic Fitting.
Чтобы сравнить номер R2 для кубического соответствия к линейной подгонке квадратов списка, выберите Linear под TYPES OF FIT и получите номер R2, 0.921. Этот результат показывает, что линейный метод наименьших квадратов данных о населении объясняет 92,1% своего отклонения. Поскольку кубическая подгонка этих данных объясняют 99,9% этой дисперсии, последняя, по-видимому, является лучшим предиктором. Однако, потому что кубическое соответствие предсказывает использование трех переменных (x, x2 и x3), основное значение R2 не полностью отражает, насколько устойчивый подгонка. Более соответствующей мерой для оценки совершенства многомерных соответствий является adjusted R2. Для получения информации о вычислении и использовании скорректированного R2, смотрите Остаточные значения и Качество подгонки.
Предположим, что вы хотите использовать кубическую модель, чтобы интерполировать американское население в 1 965 (дата, не обеспеченная в исходных данных).
В диалоговом окне Basic Fitting, под INTERPOLATE / EXTRAPOLATE DATA, вводят значение X 1965 и устанавливают флажок Plot evaluated data.
Используйте немасштабированный и нецентрированный X значения. Вы не должны сосредотачиваться и масштабироваться сначала, даже при том, что вы выбрали, чтобы масштабировать X значения, чтобы получить коэффициенты в Предсказывают Данные о переписи с Подгонкой Кубического полинома. Инструмент Basic Fitting вносит необходимые корректировки негласно.
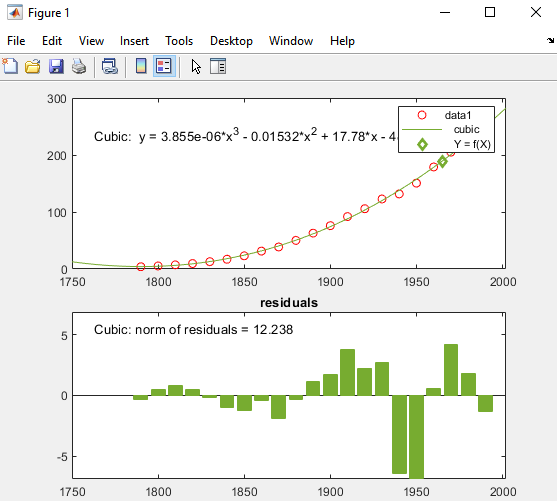
X значения и соответствующие значения для f(X) вычислены из подгонки и построены можно следующим образом:
После завершения сеанса Basic Fitting можно сгенерировать код MATLAB, который повторно вычисляет модель и воспроизводит графики с новыми данными.
В Окне рисунка выберите File > Generate Code.
Это создает функцию и отображает ее в редакторе MATLAB. Код показывает вам, как программно воспроизвести то, что вы сделали в интерактивном режиме с диалоговым окном Basic Fitting.
Измените имя функции на первой линии от createfigure к чему-то более определенному, как censusplot. Сохраните файл кода в свою текущую папку с именем файла censusplot.m Функция начинается:
function censusplot(X1, Y1, valuesToEvaluate1)
Создайте новые, со случайной ошибкой данные переписи:
rng('default')
randpop = pop + 10*randn(size(pop));Воспроизведите график с новыми данными и повторно вычислите подгонку:
censusplot(cdate,randpop,1965)
Вам нужны три входных параметра: значения x,y (data 1) построенный в исходном графике, плюс x - значение для маркера.
Следующая фигура отображает график, который производит сгенерированный код. Новый график совпадает с внешним видом фигуры от который вы сгенерированный код за исключением значений данных y, уравнения для кубического соответствия и остаточных значений в столбчатом графике, как ожидалось.
Инструмент Basic Fitting вызывает polyfit функция, чтобы вычислить аппроксимации полиномом. Это вызывает polyval функция, чтобы оценить подгонки. polyfit анализирует его входные данные, чтобы определить, хорошо подготовлены ли данные для требуемой степени подгонки.
Когда это находит плохо подготовленные данные, polyfit вычисляет регрессию, а также она может, но она также возвращает предупреждение, что подгонка могла быть улучшена. Раздел Predict the Census Data Basic Fitting в качестве примера с Подгонкой Кубического полинома выводит это предупреждение.
Один способ улучшить надежность модели состоит в том, чтобы добавить точки данных. Однако добавление наблюдений к набору данных не всегда выполнимо. Альтернативная стратегия состоит в том, чтобы преобразовать переменный предиктор, чтобы нормировать его центр и шкалу. (В примере предиктор является вектором дат переписи.)
polyfit функция нормирует вычислительными z-баллами:
где x является данными о предикторе, μ является средним значением x, и σ является стандартным отклонением x. z - баллы дают данным среднее значение 0 и стандартное отклонение 1. В Пользовательском интерфейсе Basic Fitting вы преобразовываете данные о предикторе к z - баллы путем установки флажка Center and scale x-axis data.
После центрирования и масштабирования, коэффициенты модели вычисляются для данных y как функция z. Они отличаются (и более устойчивы), чем коэффициенты, вычисленные для y как функция x. Форма модели и норма остаточных значений не изменяются. Пользовательский интерфейс Basic Fitting автоматически перемасштабирует z - баллы так, чтобы подгонка построила по той же шкале как исходные данные x.
Чтобы изучить путь, которым и масштабированные данные в центре используются в качестве посредника, чтобы создать итоговый график, запустите следующий код в Командном окне:
close load census x = cdate; y = pop; z = (x-mean(x))/std(x); % Compute z-scores of x data plot(x,y,'ro') % Plot data as red markers hold on % Prepare axes to accept new graph on top zfit = linspace(z(1),z(end),100); pz = polyfit(z,y,3); % Compute conditioned fit yfit = polyval(pz,zfit); xfit = linspace(x(1),x(end),100); plot(xfit,yfit,'b-') % Plot conditioned fit vs. x data
И масштабированный кубический полином в центре строит как синяя линия, как показано здесь:
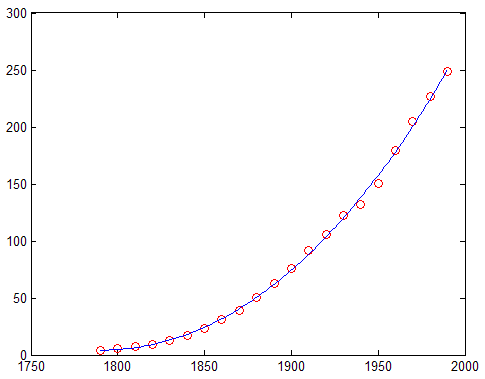
В коде, расчете z иллюстрирует, как нормировать данные. polyfit функция выполняет само преобразование, если вы обеспечиваете три возвращаемых аргумента при вызове его:
[p,S,mu] = polyfit(x,y,n)
p, теперь основаны, нормировал x. Возвращенный вектор, mu, содержит среднее и стандартное отклонение x. Для получения дополнительной информации смотрите polyfit страница с описанием.