Приложение Diagnostic Feature Designer позволяет вам выполнять фрагмент проекта функции прогнозирующего рабочего процесса обслуживания с помощью многофункционального графического интерфейса. Вы проектируете и сравниваете функции в интерактивном режиме. Затем определите, какие функции являются лучшими при различении между данными из различных групп, такими как данные из номинальных систем и из неисправных систем. Если у вас есть данные запуска к отказу, можно также оценить, какие функции являются лучшими для определения остающегося срока полезного использования (RUL). Самые эффективные функции в конечном счете становятся вашими индикаторами состояния для диагностики отказа и предзнаменований.
Следующая фигура иллюстрирует отношение между прогнозирующим рабочим процессом обслуживания и функциями Diagnostic Feature Designer.

Приложение работает с данными ансамбля. Данные ансамбля содержат измерения данных от нескольких членов, таких как несколько подобных машин или одна машина, данные которой сегментируются временным интервалом, таким как дни или годы. Данные могут также включать условные переменные, которые описывают условие отказа или условия работы члена ансамбля. Часто условные переменные задавали значения, известные как labels. Для получения дополнительной информации об ансамблях данных смотрите Ансамбли Данных для Мониторинга состояния и Прогнозирующего Обслуживания.
Рабочий процесс в приложении запускается при импорте данных с данных, которые уже являются:
Предварительно обработанный с функциями очистки
Организованный или в отдельные файлы данных или в один файл данных ансамбля, который содержит или ссылки все члены ансамбля
В Diagnostic Feature Designer рабочий процесс включает шаги, требуемые далее обрабатывать ваши данные, функции извлечения из ваших данных, и ранжировать те признаки эффективностью. Рабочий процесс завершает выбором самых эффективных функций и экспортированием тех признаков к приложению Classification Learner для обучения модели.
Рабочий процесс включает дополнительный шаг генерации кода MATLAB®. Когда вы генерируете код, который получает вычисления для признаков, которые вы выбираете, можно автоматизировать те вычисления для большего набора данных об измерении, которые включают больше членов, таких как подобные машины от различных фабрик. Получившийся набор функций обеспечивает дополнительные учебные входные параметры для Classification Learner.
Следующее изображение иллюстрирует основные функциональности Diagnostic Feature Designer. Взаимодействуйте со своими данными и своими результатами при помощи средств управления во вкладках, таких как вкладка Feature Designer, которая показана на рисунке. Просмотрите свои импортированные и выведенные переменные, функции и наборы данных в Data Browser. Визуализируйте свои результаты в области графического вывода.
Первый шаг в использовании приложения должен импортировать ваши данные. Можно импортировать данные из таблиц, расписаний или матриц. Можно также импортировать datastore ансамбля, который содержит информацию, которая позволяет приложению взаимодействовать с внешними файлами данных. Ваши файлы могут содержать фактические или симулированные данные об измерении временного интервала, спектральные модели, имена переменных, условие и операционные переменные, и показывают вас сгенерированный ранее. Diagnostic Feature Designer комбинирует все ваши данные члена в один набор данных ансамбля. В этом наборе данных каждая переменная является коллективным сигналом или моделью, которая содержит все отдельные значения члена.
Чтобы использовать те же данные на нескольких сеансах, можно сохранить начальный сеанс. Данные о сеансе включают и импортированные переменные и любые дополнительные переменные и функции, которые вы вычислили. Можно затем открыть тот сеанс в любое время при использовании приложения.
Для получения информации о подготовке ваших данных для процесса импорта см.:
Для получения информации о самом процессе импорта смотрите Импорт и Визуализируйте Данные Ансамбля в Diagnostic Feature Designer.
Чтобы построить сигналы или спектры, которые вы импортируете или что вы генерируете с инструментами обработки, выберите из галереи графика. Фигура здесь иллюстрирует типичную трассировку сигнала. Интерактивные инструменты графического вывода позволяют вам панорамированию, изменению масштаба, отображение пиковые местоположения и расстояния между peaks, и показывают статистическое изменение в ансамбле. Группировка данных меткой условия в графиках позволяет вам ясно видеть, прибывают ли данные члена из, например, номинальные или неисправные системы.
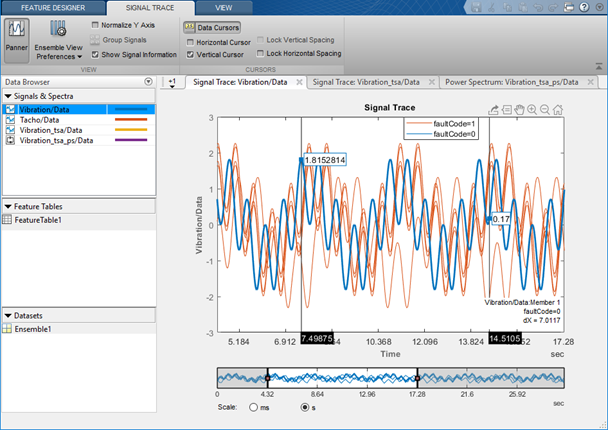
Для получения информации о графическом выводе в приложении смотрите Импорт и Визуализируйте Данные Ансамбля в Diagnostic Feature Designer.
Чтобы исследовать ваши данные и подготовить ваши данные к извлечению признаков, используйте инструменты обработки данных. Каждый раз, когда вы применяете инструмент обработки, приложение создает новую выведенную переменную с именем, которое содержит и исходную переменную и обработку вас, использовал. Например, если вы вычисляете спектр мощности из переменной Vibration/Data, новым выведенным именем переменной является Vibration_ps/Data.
Опции обработки данных для всех сигналов включают статистику уровня ансамбля, остатки сигнала, фильтрацию и степень и заказывают спектр. Можно также интерполировать данные к регулярной координатной сетке, если выборки члена не происходят в тех же интервалах независимой переменной.
Если ваши данные прибывают из вращающегося машинного оборудования, можно выполнить синхронное во времени усреднение сигнала (TSA) на основе тахометра выходные параметры или номинального об/мин. От сигнала TSA можно сгенерировать дополнительные сигналы, такие как невязка TSA и сигналы различия. Эти выведенные из TSA сигналы изолируют физические компоненты в вашей системе путем сохранения или отбрасывания гармоник и боковых полос, и они - основание для многих функций условия механизма.
Многие опции обработки могут использоваться независимо. Некоторые опции могут или должны быть выполнены как последовательность. В дополнение к вращающемуся машинному оборудованию и сигналам TSA, ранее обсужденным, другим примером является генерация остатка для любого сигнала. Вы можете:
Используйте Ensemble Statistics, чтобы сгенерировать одно член статистические переменные, такие как среднее значение и макс. которые характеризуют целый ансамбль.
Используйте Subtract Reference, чтобы сгенерировать сигналы остатка для каждого члена путем вычитания значений уровня ансамбля. Эти остатки представляют изменение среди сигналов, и другие ясно показывают сигналы, которые отклоняются от остальной части ансамбля.
Используйте эти остаточные сигналы в качестве источника для дополнительных опций обработки или для генерации функции.
Для получения информации об опциях обработки данных в приложении смотрите, Обрабатывают Данные и Исследуют Функции в Diagnostic Feature Designer.
Приложение предоставляет возможности для сегментации сигнала, локальной буферизации в приложении значений datastore ансамбля и параллельной обработки.
По умолчанию приложение обрабатывает ваш целый сигнал в одной операции. Можно также сегментировать сигналы и обработать отдельные кадры. Основанная на системе координат обработка особенно полезна если члены на вашей выставке ансамбля неустановившееся, изменяющееся во времени, или периодическое поведение. Основанная на системе координат обработка также поддерживает предвещающий рейтинг, поскольку это предоставляет историю времени значений функции.
Когда вы импортируете свои данные члена в приложение, приложение создает локальный ансамбль и пишет новые переменные и функции тому ансамблю. Когда вместо этого вы импортируете объект datastore ансамбля, приложение по умолчанию взаимодействует с внешними файлами, перечисленными в объекте. Если вы не хотите, чтобы приложение записало в ваши внешние файлы, можно принять решение иметь приложение, создают локальный ансамбль и результаты записи там. После того, как у вас есть результаты, которые вы хотите, можно экспортировать ансамбль в рабочее пространство MATLAB. Оттуда, можно записать переменные и функции, которые вы хотите сохранить назад в ваши исходные файлы с помощью функций datastore ансамбля командной строки. Для получения дополнительной информации о хранилищах данных ансамбля смотрите Ансамбли Данных для Мониторинга состояния и Прогнозирующего Обслуживания.
Если у вас есть Parallel Computing Toolbox™, можно использовать параллельную обработку. Поскольку приложение часто выполняет ту же обработку независимо на всех членах, параллельная обработка может значительно улучшить время вычисления.
От ваших исходных и выведенных сигналов и спектров, можно вычислить функции и оценить их эффективность. Вы можете уже знать, какие функции, вероятно, будут работать лучше всего, или вы можете хотеть экспериментировать со всеми применимыми функциями. Доступные функции лежат в диапазоне от общей статистики сигнала до специализированных метрик условия механизма, которые могут идентифицировать точное местоположение отказов и нелинейные функции, которые подсвечивают хаотическое поведение.
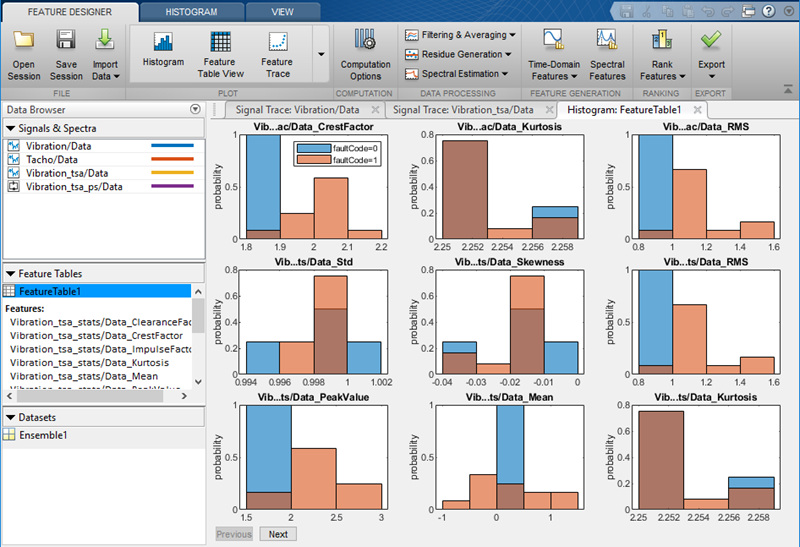
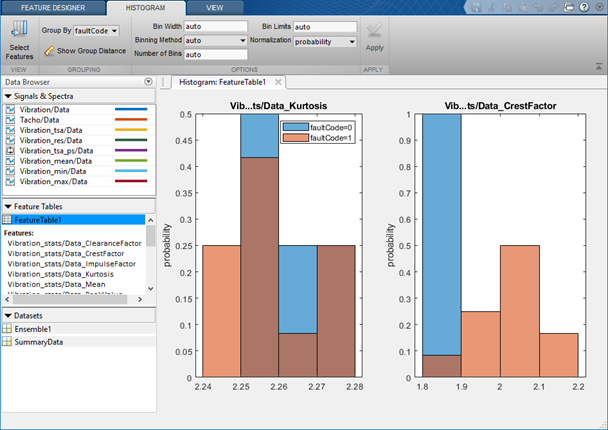
Любое время вы вычисляете набор функций, приложение, добавляет их в таблицу функции и генерирует гистограмму распределения значений через члены. Фигура здесь иллюстрирует гистограммы для двух функций. Гистограммы иллюстрируют, как хорошо каждая функция дифференцирует данные. Например, предположите, что вашей условной переменной является faultCode с состояниями 0 для данных номинальной системы и 1 для данных неисправной системы, как в фигуре. Вы видите в гистограмме, приводят ли номинальные и дефектные группировки к отличным или смешанным интервалам гистограммы. Можно просмотреть все гистограммы функции целиком или выбор, который показывает приложение, включает в набор графика гистограммы.
Чтобы сравнить значения всех ваших функций вместе, используйте табличное представление функции и график трассировки функции. Табличное представление функции отображает таблицу всех значений функции всех членов ансамбля. Трассировка функции строит эти значения. Этот график визуализирует расхождение значений функции в вашем ансамбле и позволяет вам идентифицировать определенный член, который представляет значение функции.
Для получения информации о генерации функции и интерпретации гистограммы в приложении, см.:
Гистограммы позволяют вам выполнять начальную оценку эффективности функции. Чтобы выполнить более строгую относительную оценку, можно отранжировать признаки с помощью специализированных статистических методов. Приложение обеспечивает два типа рейтинга — classification ranking и prognostic ranking.
Методы рейтинга классификации выигрывают и ранжируют признаки способностью различить между или среди групп данных, такой как между номинальным и дефектным поведением. Рейтинг классификации требует условных переменных, которые содержат метки, которые характеризуют группы данных
Предвещающие методы рейтинга выигрывают и ранжируют признаки на основе способности отследить ухудшение для того, чтобы включить предсказание остающегося срока полезного использования (RUL). Предвещающий рейтинг требует действительных или симулированных данных запуска к отказу или прогрессии отказа и не использует условные переменные.
Фигура здесь иллюстрирует результаты рейтинга классификации. Можно попробовать несколько методов рейтинга и просмотреть результаты каждого метода вместе. Занимающие место результаты позволяют вам устранять неэффективные функции и оценивать занимающие место эффекты корректировок параметра, когда вычисление вывело переменные или функции.
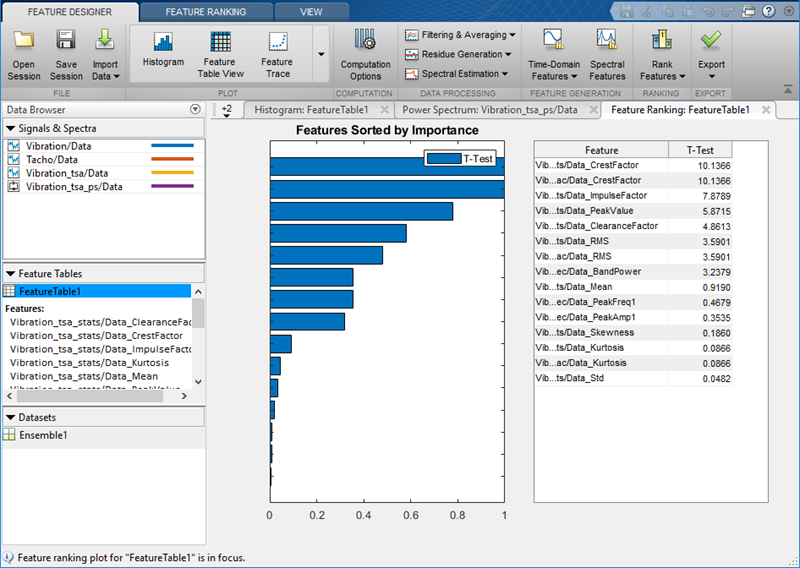
Для получения информации о рейтинге функции см.:
Оцените и экспортируйте признаки в Diagnostic Feature Designer
Diagnostic Feature Designer Feature Ranking Tab и разделы Ranking Technique
После того, как вы задали свой набор функций кандидата, можно экспортировать их в приложение Classification Learner в Statistics and Machine Learning Toolbox™. Classification Learner обучает модели классифицировать данные при помощи автоматизированных методов, чтобы протестировать различные типы моделей с набором функций. При этом Classification Learner определяет лучшую модель и самые эффективные функции. Для прогнозирующего обслуживания цель использования Classification Learner состоит в том, чтобы выбрать и обучить модель, которая различает между данными из здорового и из неисправных систем. Можно включить эту модель в алгоритм для обнаружения отказа и предсказание. Для примера экспорта из приложения в Classification Learner смотрите, Анализируют и Выбирают Features for Pump Diagnostics.
Можно также экспортировать признаки и наборы данных к рабочему пространству MATLAB. Выполнение так позволяет вам визуализировать и обрабатывать свои исходные и выведенные данные ансамбля с помощью функций командной строки или других приложений. В командной строке можно также сохранить функции и переменные, которые вы выбираете в файлы, включая файлы, на которые ссылаются в datastore ансамбля.
Для получения информации об экспорте смотрите Ранг и Экспортируйте Признаки в Diagnostic Feature Designer.
Сгенерируйте код для функций, которые вы выбираете так, чтобы можно было автоматизировать расчеты функции с помощью функции MATLAB. Например, предположите, что у вас есть большой набор входных данных со многими членами, но для более быстрого отклика приложений, вы хотите использовать подмножество тех данных, когда вы сначала исследуете возможные функции в интерактивном режиме. После того, как вы идентифицируете свои самые эффективные функции с помощью приложения, можно сгенерировать код, и затем применить те же расчеты для тех функций к набору данных все-члена с помощью сгенерированного кода. Более крупный член установил, позволяет вам обеспечить больше выборок, когда обучение вводит к Classification Learner.
function [featureTable,outputTable] = diagnosticFeatures(inputData) %DIAGNOSTICFEATURES recreates results in Diagnostic Feature Designer. %
