Следующие ограничения применяются к размерам наборов данных точки останова и табличных данных, сопоставленных с блоками интерполяционной таблицы:
Ограничения памяти вашей системы ограничивают полный размер интерполяционной таблицы.
Интерполяционные таблицы должны использовать сопоставимые размерности так, чтобы полный размер табличных данных отразил размер каждого набора данных точки останова.
Чтобы проиллюстрировать второе ограничение, рассмотрите следующие векторы значений ввода и вывода, которые создают отношение в графике.
Vector of input values: [-3 -2 -1 0 1 2 3] Vector of output values: [-3 -1 0 -1 0 1 3]
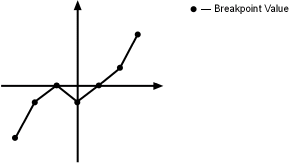
В этом примере входные и выходные данные одного размера (1 7), делая данные последовательно определяемыми размеры для 1D интерполяционной таблицы.
Следующие значения ввода и вывода задают двумерную интерполяционную таблицу, которую графически показывают.
Row index input values: [1 2 3] Column index input values: [1 2 3 4] Table data: [11 12 13 14; 21 22 23 24; 31 32 33 34]
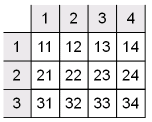
В этом примере размеры векторов, представляющих индексы строки и столбца, 1 3 и 1 на 4, соответственно. Следовательно, выходная таблица должна иметь размер, 3 на 4 для сопоставимых размерностей.
Первая стадия операции поиска по таблице включает имеющие отношение входные параметры к наборам данных точки останова. Алгоритм поиска требует, чтобы ввел наборы точки останова быть strictly monotonically increasing, то есть, каждый последовательный элемент больше своего предыдущего элемента. Например, вектор
A = [0 0.5 1 1.9 2.1 3]
допустимый набор данных точки останова, когда каждый элемент больше, чем его предшественники.
Несмотря на то, что набор данных точки останова является строго монотонным в double формат, это не может быть так после преобразования в тип данных с фиксированной точкой.
Можно представлять равномерно распределенные точки останова в наборе данных при помощи одного из этих методов.
| Формулировка | Пример | Когда использовать эту формулировку |
|---|---|---|
[first_value:spacing:last_value] | [10:10:200] | Интерполяционная таблица не использует double или single. |
first_value + spacing * [0:(last_value-first_value)/spacing] | 1 + (0.02 * [0:450]) | Интерполяционная таблица использует double или single. |
Поскольку типы данных с плавающей точкой не могут точно представлять некоторые числа, вторая формулировка работает лучше на double и single. Например, используйте 1 + (0.02 * [0:450]) вместо [1:0.02:10]. Для списка блоков интерполяционной таблицы, которые поддерживают равномерно распределенные точки останова, см. Сводные данные Функций Блока Интерполяционной таблицы.
Среди других преимуществ равномерно распределенные точки останова могут сделать сгенерированный код без делений и уменьшать использование памяти. Для получения дополнительной информации см.:
fixpt_evenspace_cleanup в документации Simulink®
Эффекты разрядки на скорости, ошибке и использовании памяти (Fixed-Point Designer)
Идентифицируйте сомнительные операции фиксированной точки (Embedded Coder)
Не используйте MATLAB® linspace функция, чтобы задать равномерно распределенные точки останова. Simulink использует более трудный допуск, чтобы проверять, имеет ли набор точки останова даже интервал. Если вы используете linspace чтобы задать точки останова для вашей интерполяционной таблицы, Simulink полагает, что точки останова неравномерно распределены.
