Можно использовать Classification Learner, чтобы автоматически обучить выбор различных моделей классификации на данных. Используйте автоматизированное обучение быстро попробовать выбор типов модели, затем исследуйте многообещающие модели в интерактивном режиме. Чтобы начать, попробуйте эти опции сначала:

| Кнопки классификатора Запуска | Описание |
|---|---|
| All Quick-To-Train | Попробуйте это сначала. Приложение обучит все типы модели, доступные для вашего набора данных, которые обычно быстры, чтобы соответствовать. |
| All Linear | Попробуйте это, если вы ожидаете линейные контуры между классами в ваших данных. Эта опция соответствует только Линейному SVM и Линейному Дискриминанту. |
| All | Используйте это, чтобы обучить все доступные nonoptimizable типы модели. Обучает каждый тип независимо от любых предшествующих обученных моделей. Может быть длительным. |
Смотрите автоматизированное обучение классификатора.
Если вы хотите исследовать классификаторы по одному, или вы уже знаете, какой тип классификатора вы хотите, можно выбрать отдельные модели или обучить группу того же типа. Чтобы видеть все доступные опции классификатора, на вкладке Classification Learner, кликают по стреле на ультраправом из раздела Model Type, чтобы расширить список классификаторов. nonoptimizable опции модели в галерее Model Type являются предварительно установленными начальными точками с различными настройками, подходящими для области значений различных проблем классификации. Чтобы использовать optimizable опции модели и гиперпараметры модели мелодии автоматически, смотрите Гипероптимизацию параметров управления в Приложении Classification Learner.
Для справки, выбирая лучший тип классификатора для вашей проблемы, см., что таблица показывает типичные характеристики различных алгоритмов контролируемого обучения. Используйте таблицу в качестве руководства для вашего итогового выбора алгоритмов. Выберите компромисс, который вы хотите в скорости, использовании памяти, гибкости и interpretability. Лучший тип классификатора зависит от ваших данных.
Чтобы постараться не сверхсоответствовать, ищите модель более низкой гибкости, которая обеспечивает достаточную точность. Например, ищите простые модели, такие как деревья решений и дискриминанты, которые быстры и легки интерпретировать. Если модели не являются достаточно точным предсказанием ответа, выбирают другие классификаторы с более высокой гибкостью, такие как ансамбли. Чтобы управлять гибкостью, смотрите детали для каждого типа классификатора.
Характеристики типов классификатора
| Классификатор | Скорость предсказания | Использование памяти | Interpretability |
|---|---|---|---|
|
Деревья решений
| Быстро | Маленький | Легкий |
|
Дискриминантный анализ
| Быстро | Маленький для линейного, большого для квадратичного | Легкий |
|
Логистическая регрессия
| Быстро | Носитель | Легкий |
ПримечаниеГенерация кода C поддержек для предсказания.
| Носитель для линейного Медленный для других | Носитель для линейного. Все другие: носитель для мультикласса, большого для двоичного файла. | Легкий для линейного SVM. Трудный для всех других типов ядра. |
|
Самые близкие соседние классификаторы
| Медленный для кубического Носитель для других | Носитель | Трудно |
|
Классификаторы ансамбля
| Быстро к носителю в зависимости от выбора алгоритма | Низко к высоко в зависимости от выбора алгоритма | Трудно |
| Наивные классификаторы Байеса
| Носитель для простых распределений Медленный для распределений ядра или высоко-размерных данных | Маленький для простых распределений Носитель для распределений ядра или высоко-размерных данных | Легкий |
Таблицы на этой странице описывают общие характеристики скорости и использования памяти для всех nonoptimizable предварительно установленных классификаторов. Классификаторы были протестированы с различными наборами данных (до 7 000 наблюдений, 80 предикторов и 50 классов), и результаты задают следующие группы:
Скорость
Быстро 0,01 секунды
Средняя 1 секунда
Замедлите 100 секунд
Memory
Маленький 1 МБ
Средние 4 МБ
Большие 100 МБ
Эти таблицы предоставляют общее руководство. Ваши результаты зависят от ваших данных и скорости вашей машины.
Чтобы считать описание каждого классификатора в Classification Learner, переключитесь на представление деталей.
После того, как вы выберете тип классификатора (например, деревья решений), попробуйте обучение с помощью каждого из классификаторов. nonoptimizable опции в галерее Model Type являются начальными точками с различными настройками. Судите их всех, чтобы видеть, какая опция производит лучшую модель с вашими данными.
Для инструкций по рабочему процессу смотрите, Обучают Модели Классификации в Приложении Classification Learner.
В Classification Learner галерея Model Type показывает как доступную типы классификатора, которые поддерживают ваши выбранные данные.
| Классификатор | Все числовые предикторы | Все категориальные предикторы | Некоторые категориальные, некоторые числовые |
|---|---|---|---|
| Деревья решений | Да | Да | Да |
| Дискриминантный анализ | Да | Нет | Нет |
| Логистическая регрессия | Да | Да | Да |
| SVM | Да | Да | Да |
| NearestNeighbor | Евклидово расстояние только | Расстояние Хемминга только | Нет |
| Ансамбли | Да | Да, кроме дискриминанта подпространства | Да, кроме любого Подпространства |
| Наивный байесов | Да | Да | Да |
Деревья решений легко интерпретировать, быстро для подбора кривой и предсказания, и низко на использовании памяти, но у них может быть низкая прогнозирующая точность. Попытайтесь вырастить более простые деревья, чтобы предотвратить сверхподбор кривой. Управляйте глубиной с установкой Maximum number of splits.
Гибкость модели увеличивается с установкой Maximum number of splits.
| Тип классификатора | Скорость предсказания | Использование памяти | Interpretability | Гибкость модели |
|---|---|---|---|---|
| Крупное дерево | Быстро | Маленький | Легкий | Низко Немного листов, чтобы сделать крупные различия между классами (максимальное количество разделений равняется 4). |
| Среднее дерево | Быстро | Маленький | Легкий | Носитель Среднее количество уезжает в более прекрасные различия между классами (максимальное количество разделений равняется 20). |
| Прекрасное дерево | Быстро | Маленький | Легкий | Высоко Много листов, чтобы сделать много тонких различий между классами (максимальное количество разделений равняется 100). |
В Model Type галерея нажимают All Trees, чтобы попробовать каждую из nonoptimizable опций дерева решений. Обучите их всех видеть, какие настройки производят лучшую модель с вашими данными. Выберите лучшую модель в Списке предыстории. Чтобы попытаться улучшить вашу модель, попробуйте выбор признаков, и затем попытайтесь изменить некоторые расширенные настройки.
Вы обучаете деревья классификации предсказывать ответы на данные. Чтобы предсказать ответ, следуйте за решениями в дереве от корня (начало) узел вниз к вершине. Вершина содержит ответ. Деревья Statistics and Machine Learning Toolbox™ являются двоичным файлом. Каждый шаг в предсказании включает проверку значения одного предиктора (переменная). Например, вот простое дерево классификации:
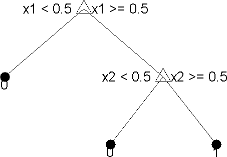
Это дерево предсказывает классификации на основе двух предикторов, x1 и x2. Чтобы предсказать, запустите в главном узле. При каждом решении проверяйте значения предикторов, чтобы решить который ветвь следовать. Когда ветви достигают вершины, данные классифицируются любой как тип 0 или 1.
Можно визуализировать модель дерева принятия решения путем экспорта модели из приложения и затем ввода:
view(trainedModel.ClassificationTree,'Mode','graph')
fisheriris данные.

Для примера смотрите, Обучают Деревья решений Используя Приложение Classification Learner.
Деревья классификации в Classification Learner используют fitctree функция. Можно установить эти опции:
Maximum number of splits
Задайте максимальное количество разделений или точек разветвления, чтобы управлять глубиной вашего дерева. Когда вы выращиваете дерево решений, рассматриваете его простоту и предсказательную силу. Чтобы изменить количество разделений, нажмите кнопки или введите положительное целочисленное значение в поле Maximum number of splits .
Прекрасное дерево со многими листами обычно очень точно на обучающих данных. Однако древовидная сила не показывает сопоставимую точность на независимом наборе тестов. Покрытое листвой дерево имеет тенденцию перетренироваться, и его точность валидации часто намного ниже, чем его обучение (или перезамена) точность.
В отличие от этого крупное дерево не достигает высокой учебной точности. Но крупное дерево может быть более устойчивым в той своей учебной точности, может приблизиться к тому из представительного набора тестов. Кроме того, крупное дерево легко интерпретировать.
Split criterion
Задайте меру по критерию разделения для решения, когда разделить узлы. Попробуйте каждую из этих трех настроек, чтобы видеть, улучшают ли они модель с вашими данными.
Разделите опциями критерия является Gini's diversity index, Twoing rule, или Maximum deviance reduction (также известный как перекрестную энтропию).
Дерево классификации пытается оптимизировать к чистым узлам, содержащим только один класс. Индекс разнообразия Джини (значение по умолчанию) и критерий отклонения измеряет примесь узла. Правило twoing является различной мерой для решения, как разделить узел, где, максимизировав чистоту узла увеличений выражения правила twoing.
Для получения дополнительной информации этих критериев разделения, смотрите ClassificationTree
Больше о.
Surrogate decision splits — Только для недостающих данных.
Задайте суррогатное использование для разделений решения. Если у вас есть данные с отсутствующими значениями, используйте суррогатные разделения, чтобы улучшить точность предсказаний.
Когда вы устанавливаете Surrogate decision splits на On, дерево классификации находит самое большее 10 суррогатных разделений в каждом узле ветви. Чтобы изменить номер, нажмите кнопки или введите положительное целочисленное значение в поле Maximum surrogates per node.
Когда вы устанавливаете Surrogate decision splits на Find All, дерево классификации находит все суррогатные разделения в каждом узле ветви. Find All установка может использовать продолжительное время и память.
В качестве альтернативы можно позволить приложению выбрать некоторые из этих опций модели автоматически при помощи гипероптимизации параметров управления. Смотрите Гипероптимизацию параметров управления в Приложении Classification Learner.
Дискриминантный анализ является популярным первым алгоритмом классификации, который попробует, потому что это быстро, точно и легко интерпретировать. Дискриминантный анализ хорош для широких наборов данных.
Дискриминантный анализ принимает, что различные классы генерируют данные на основе различных Распределений Гаусса. Чтобы обучить классификатор, подходящая функция оценивает параметры Распределения Гаусса для каждого класса.
| Тип классификатора | Скорость предсказания | Использование памяти | Interpretability | Гибкость модели |
|---|---|---|---|---|
| Линейный дискриминант | Быстро | Маленький | Легкий | Низко Создает линейные контуры между классами. |
| Квадратичный дискриминант | Быстро | Большой | Легкий | Низко Создает нелинейные контуры между классами (эллипс, парабола или гипербола). |
Дискриминантный анализ в Classification Learner использует fitcdiscr функция. И для линейных и для квадратичных дискриминантов, можно изменить опцию Covariance structure. Если у вас есть предикторы с нулевым отклонением или если какая-либо из ковариационных матриц ваших предикторов сингулярна, учебный может привести использование к сбою значения по умолчанию, Full структура ковариации. Если обучение перестало работать, выберите Diagonal структура ковариации вместо этого.
В качестве альтернативы можно позволить приложению выбрать некоторые из этих опций модели автоматически при помощи гипероптимизации параметров управления. Смотрите Гипероптимизацию параметров управления в Приложении Classification Learner.
Если у вас есть 2 класса, логистическая регрессия является популярным простым алгоритмом классификации, чтобы попробовать, потому что легко интерпретировать. Классификатор моделирует вероятности класса как функцию линейной комбинации предикторов.
| Тип классификатора | Скорость предсказания | Использование памяти | Interpretability | Гибкость модели |
|---|---|---|---|---|
| Логистическая регрессия | Быстро | Носитель | Легкий | Низко Вы не можете изменить параметры в гибкость модели управления. |
Логистическая регрессия в Classification Learner использует fitglm функция. Вы не можете установить опции для этого классификатора в приложении.
В Classification Learner можно обучить SVMs, когда данные имеют два или больше класса.
После того, как вы обучите модель SVM, можно сгенерировать код С для предсказания. Требует MATLAB® Coder™. Смотрите Генерируют код С для Предсказания.
| Тип классификатора | Скорость предсказания | Использование памяти | Interpretability | Гибкость модели |
|---|---|---|---|---|
| Линейный SVM | Двоичный файл: быстро Мультикласс: носитель | Носитель | Легкий | Низко Делает простое линейное разделение между классами. |
| Квадратичный SVM | Двоичный файл: быстро Мультикласс: медленный | Двоичный файл: носитель Мультикласс: большой | Трудно | Носитель |
| Кубический SVM | Двоичный файл: быстро Мультикласс: медленный | Двоичный файл: носитель Мультикласс: большой | Трудно | Носитель |
| Прекрасный гауссов SVM | Двоичный файл: быстро Мультикласс: медленный | Двоичный файл: носитель Мультикласс: большой | Трудно | Высоко — уменьшается с установкой шкалы ядра. Делает точно подробные различия между классами, с набором шкалы ядра к sqrt(P)/4. |
| Средний гауссов SVM | Двоичный файл: быстро Мультикласс: медленный | Двоичный файл: носитель Мультикласс: большой | Трудно | Носитель Средние различия, с ядром масштабируют набор к sqrt(P). |
| Крупный гауссов SVM | Двоичный файл: быстро Мультикласс: медленный | Двоичный файл: носитель Мультикласс: большой | Трудно | Низко Делает крупные различия между классами, с набором шкалы ядра к sqrt(P)*4, где P является количеством предикторов. |
Попробуйте обучение каждая из nonoptimizable опций машины опорных векторов в галерее Model Type. Обучите их всех видеть, какие настройки производят лучшую модель с вашими данными. Выберите лучшую модель в Списке предыстории. Чтобы попытаться улучшить вашу модель, попробуйте выбор признаков, и затем попытайтесь изменить некоторые расширенные настройки.
SVM классифицирует данные путем нахождения лучшей гиперплоскости, которая разделяет точки данных одного класса от тех из другого класса. Лучшая гиперплоскость для SVM означает тот с самым большим полем между этими двумя классами. Поле означает максимальную ширину плиты, параллельной гиперплоскости, которая не имеет никаких внутренних точек данных.
support vectors является точками данных, которые являются самыми близкими к отделяющейся гиперплоскости; эти точки находятся на контуре плиты. Следующая фигура иллюстрирует эти определения, с + указание на точки данных типа 1, и – указание на точки данных типа-1.
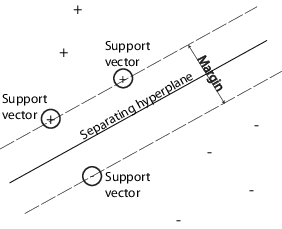
SVMs может также использовать мягкое поле, означая гиперплоскость, которая разделяет многих, но не все точки данных.
Для примера смотрите, Обучают Машины опорных векторов Используя Приложение Classification Learner.
Если у вас есть точно два класса, Classification Learner использует fitcsvm функция, чтобы обучить классификатор. Если у вас есть больше чем два класса, приложение использует fitcecoc функция, чтобы уменьшать многоклассовую задачу классификации до набора бинарных подпроблем классификации, с одним учеником SVM для каждой подпроблемы. Чтобы исследовать код на двоичный файл и типы классификатора мультикласса, можно сгенерировать код от обученных классификаторов в приложении.
Можно установить эти опции в приложении:
Kernel function
Задайте функцию Ядра, чтобы вычислить классификатор.
Линейное ядро, самое легкое интерпретировать
Ядро гауссовой или Радиальной основной функции (RBF)
Квадратичный
Кубический
Box constraint level
Задайте ограничение поля, чтобы сохранить допустимые значения множителей Лагранжа в поле, ограниченной области.
Чтобы настроить ваш классификатор SVM, попытайтесь увеличить ограничительный уровень поля. Нажмите кнопки или введите значение положительной скалярной величины в поле Box constraint level. Увеличение ограничительного уровня поля может сократить число векторов поддержки, но также и может увеличить учебное время.
Параметр ограничения Поля является мягко-граничным штрафом, известным C в основных уравнениях, и является трудным ограничением “поля” в двойных уравнениях.
Kernel scale mode
Задайте ручное ядро, масштабирующееся при желании.
Когда вы устанавливаете Kernel scale mode на Auto, затем программное обеспечение использует эвристическую процедуру, чтобы выбрать значение шкалы. Эвристическая процедура использует подвыборку. Поэтому, чтобы воспроизвести результаты, установите seed случайных чисел с помощью rng перед обучением классификатор.
Когда вы устанавливаете Kernel scale mode на Manual, можно задать значение. Нажмите кнопки или введите значение положительной скалярной величины в поле Manual kernel scale. Программное обеспечение делит все элементы матрицы предиктора значением шкалы ядра. Затем программное обеспечение применяет соответствующую норму ядра, чтобы вычислить матрицу Грамма.
Гибкость модели уменьшается с установкой шкалы ядра.
Multiclass method
Только для данных с 3 или больше классами. Этот метод уменьшает многоклассовую задачу классификации до набора бинарных подпроблем классификации с одним учеником SVM для каждой подпроблемы. One-vs-One обучает одного ученика каждой паре классов. Это учится отличать один класс от другого. One-vs-All обучает одного ученика каждому классу. Это учится отличать один класс от всех других.
Standardize data
Задайте, масштабировать ли каждое координатное расстояние. Если предикторы имеют широко различные шкалы, стандартизация может улучшить подгонку.
В качестве альтернативы можно позволить приложению выбрать некоторые из этих опций модели автоматически при помощи гипероптимизации параметров управления. Смотрите Гипероптимизацию параметров управления в Приложении Classification Learner.
Самые близкие соседние классификаторы обычно имеют хорошую прогнозирующую точность в низких размерностях, но не может в высоких размерностях. Они имеют использование верхней памяти и не легки интерпретировать.
Гибкость модели уменьшается с установкой Number of neighbors.
| Тип классификатора | Скорость предсказания | Использование памяти | Interpretability | Гибкость модели |
|---|---|---|---|---|
| Прекрасный KNN | Носитель | Носитель | Трудно | Точно подробные различия между классами. Номер соседей определяется к 1. |
| Средний KNN | Носитель | Носитель | Трудно | Средние различия между классами. Номер соседей определяется к 10. |
| Крупный KNN | Носитель | Носитель | Трудно | Крупные различия между классами. Номер соседей определяется к 100. |
| Косинус KNN | Носитель | Носитель | Трудно | Средние различия между классами, с помощью метрики расстояния Косинуса. Номер соседей определяется к 10. |
| Кубический KNN | Медленный | Носитель | Трудно | Средние различия между классами, с помощью кубической метрики расстояния. Номер соседей определяется к 10. |
| Взвешенный KNN | Носитель | Носитель | Трудно | Средние различия между классами, с помощью веса расстояния. Номер соседей определяется к 10. |
Попробуйте обучение каждая из nonoptimizable самых близких соседних опций в галерее Model Type. Обучите их всех видеть, какие настройки производят лучшую модель с вашими данными. Выберите лучшую модель в Списке предыстории. Чтобы попытаться улучшить вашу модель, попробуйте выбор признаков, и затем (опционально) попытайтесь изменить некоторые расширенные настройки.
Что такое k - Самая близкая Соседняя классификация? Категоризация точек запроса на основе их расстояния до точек (или соседи) в обучающем наборе данных может быть простым все же эффективным способом классифицировать новые точки. Можно использовать различные метрики, чтобы определить расстояние. Учитывая набор X точек n и функции расстояния, k - самый близкий сосед (k NN) поиск позволяет вам найти k самыми близкими точками в X к точке запроса или набору точек. k основанные на NN алгоритмы широко используется в качестве правил машинного обучения сравнительного теста.

Для примера смотрите, Обучают Самые близкие Соседние Классификаторы Используя Приложение Classification Learner.
Самые близкие Соседние классификаторы в Classification Learner используют fitcknn функция. Можно установить эти опции:
Number of neighbors
Задайте количество самых близких соседей, чтобы найти для классификации каждой точки при предсказании. Задайте штраф (небольшое число) или крупный классификатор (высокий номер) путем изменения количества соседей. Например, прекрасный KNN использует одного соседа, и крупный KNN использует 100. Многие соседи могут быть трудоемкими, чтобы соответствовать.
Distance metric
Можно использовать различные метрики, чтобы определить расстояние до точек. Для определений смотрите класс ClassificationKNN.
Distance weight
Задайте функцию взвешивания расстояния. Можно выбрать Equal (никакие веса), Inverse (вес 1/дистанцировать), или Squared Inverse (вес является 1/distance2).
Standardize data
Задайте, масштабировать ли каждое координатное расстояние. Если предикторы имеют широко различные шкалы, стандартизация может улучшить подгонку.
В качестве альтернативы можно позволить приложению выбрать некоторые из этих опций модели автоматически при помощи гипероптимизации параметров управления. Смотрите Гипероптимизацию параметров управления в Приложении Classification Learner.
Комбинация классификаторов ансамбля следует из многих слабых учеников в одну высококачественную модель ансамбля. Качества зависят от выбора алгоритма.
Гибкость модели увеличивается с установкой Number of learners.
Все классификаторы ансамбля имеют тенденцию не спешить соответствовать, потому что им часто нужны многие ученики.
| Тип классификатора | Скорость предсказания | Использование памяти | Interpretability | Метод ансамбля | Гибкость модели |
|---|---|---|---|---|---|
| Повышенные деревья | Быстро | Низко | Трудно | AdaBoost, с Decision Tree ученики | Носитель к высокому — увеличивается с установкой Number of learners или Maximum number of splits.
СоветПовышенные деревья могут обычно добиваться большего успеха, чем сложенный в мешок, но могут потребовать настройки параметра и большего количества учеников
|
| Сложенные в мешок деревья | Носитель | Высоко | Трудно | Случайный лесBag, с Decision Tree ученики | Высоко — увеличивается с установкой Number of learners.
СоветПопробуйте этот классификатор сначала.
|
| Дискриминант подпространства | Носитель | Низко | Трудно | Subspace, с Discriminant ученики | Носитель — увеличивается с установкой Number of learners. Хороший для многих предикторов |
| Подпространство KNN | Носитель | Носитель | Трудно | Subspace, с Nearest Neighbor ученики | Носитель — увеличивается с установкой Number of learners. Хороший для многих предикторов |
| Деревья RUSBoost | Быстро | Низко | Трудно | RUSBoost, с Decision Tree ученики | Носитель — увеличивается с установкой Number of learners или Maximum number of splits. Хороший для скошенных данных (со значительно большим количеством наблюдений за 1 классом) |
| GentleBoost или LogitBoost — не доступный в галерее Model Type. Если у вас есть 2 данных о классе, выберите вручную. | Быстро | Низко | Трудно | GentleBoost или LogitBoost, с Decision Tree ученикиВыберите Boosted Trees и превратитесь в GentleBoost метод. | Носитель — увеличивается с установкой Number of learners или Maximum number of splits. Для бинарной классификации только |
Сложенные в мешок деревья используют 'random forest' Бреимена алгоритм. Для ссылки смотрите Бреимена, L. Случайные Леса. Машинное обучение 45, стр 5–32, 2001.
Советы
Попробуйте сложенные в мешок деревья сначала. Повышенные деревья могут обычно добиваться большего успеха, но могут потребовать поиска многих значений параметров, который длителен.
Попробуйте обучение каждая из nonoptimizable опций классификатора ансамбля в галерее Model Type. Обучите их всех видеть, какие настройки производят лучшую модель с вашими данными. Выберите лучшую модель в Списке предыстории. Чтобы попытаться улучшить вашу модель, попробуйте выбор признаков, PCA, и затем (опционально) попытайтесь изменить некоторые расширенные настройки.
Для повышения методов ансамбля можно получить мелкие детали или с более глубокими деревьями или с большим числом мелких деревьев. Как с одним древовидными классификаторами, глубокие деревья могут вызвать сверхподбор кривой. Необходимо экспериментировать, чтобы выбрать лучшую древовидную глубину для деревьев в ансамбле, для того, чтобы к совпадению данных компромисса с древовидной сложностью. Используйте настройки Number of learners и Maximum number of splits.
Для примера смотрите, Обучают Классификаторы Ансамбля Используя Приложение Classification Learner.
Классификаторы ансамбля в Classification Learner используют fitcensemble функция. Можно установить эти опции:
Для Ensemble method выбора справки и Learner type, см. таблицу Ensemble. Попробуйте предварительные установки сначала.
Maximum number of splits
Для повышения методов ансамбля задайте максимальное количество разделений или точек разветвления, чтобы управлять глубиной ваших древовидных учеников. Много ветвей имеют тенденцию сверхсоответствовать, и более простые деревья могут быть более устойчивыми и легкими интерпретировать. Экспериментируйте, чтобы выбрать лучшую древовидную глубину для деревьев в ансамбле.
Number of learners
Попытайтесь изменить количество учеников, чтобы видеть, можно ли улучшить модель. Многие ученики могут произвести высокую точность, но могут быть трудоемкими, чтобы соответствовать. Начните с нескольких дюжин учеников, и затем смотрите производительность. Ансамблю с хорошей предсказательной силой могут быть нужны несколько сотен учеников.
Learning rate
Задайте скорость обучения для уменьшения. Если вы устанавливаете скорость обучения на меньше чем 1, ансамбль требует большего количества итераций изучения, но часто достигает лучшей точности. 0.1 популярный выбор.
Subspace dimension
Для ансамблей подпространства задайте количество предикторов к выборке в каждом ученике. Приложение выбирает случайное подмножество предикторов для каждого ученика. Подмножества, выбранные различными учениками, независимы.
В качестве альтернативы можно позволить приложению выбрать некоторые из этих опций модели автоматически при помощи гипероптимизации параметров управления. Смотрите Гипероптимизацию параметров управления в Приложении Classification Learner.
Наивные классификаторы Байеса легко интерпретировать и полезный для классификации мультиклассов. Наивный алгоритм Бейеса усиливает теорему Бейеса и делает предположение, что предикторы условно независимы, учитывая класс. Используйте эти классификаторы, если это предположение независимости допустимо для предикторов в ваших данных. Однако алгоритм все еще, кажется, работает хорошо, когда предположение независимости не допустимо.
Для наивных классификаторов Байеса ядра можно управлять ядром более сглаженный тип с установкой Kernel Type и управлять ядром, сглаживающим поддержку плотности с установкой Support.
| Тип классификатора | Скорость предсказания | Использование памяти | Interpretability | Гибкость модели |
|---|---|---|---|---|
| Гауссов наивный байесов | Носитель Медленный для высоко-размерных данных | Маленький Носитель для высоко-размерных данных | Легкий | Низко Вы не можете изменить параметры в гибкость модели управления. |
| Ядро, наивное байесов | Медленный | Носитель | Легкий | Носитель Можно изменить настройки для Kernel Type и Support, чтобы управлять как распределения предиктора моделей классификатора. |
Наивный Байесов в Classification Learner использует fitcnb функция.
Для наивных классификаторов Байеса ядра можно установить эти опции:
Kernel Type — Задайте ядро более сглаженный тип. Попытайтесь установить каждую из этих опций видеть, улучшают ли они модель с вашими данными.
Опциями типа ядра является Gaussianполе, Epanechnikov, или Triangle.
Поддержка Задайте ядро, сглаживающее поддержку плотности. Попытайтесь установить каждую из этих опций видеть, улучшают ли они модель с вашими данными.
Вариантами поддержки является Unbounded (все действительные значения) или Positive (все положительные действительные значения).
В качестве альтернативы можно позволить приложению выбрать некоторые из этих опций модели автоматически при помощи гипероптимизации параметров управления. Смотрите Гипероптимизацию параметров управления в Приложении Classification Learner.
Для следующих моделей обучения шагов смотрите, Обучают Модели Классификации в Приложении Classification Learner.
