Декодирование имеющей малую плотность проверки четности (LDPC)
[ возвращает LDPC-декодируемую выходную матрицу out,actNumIter,finalParityChecks] = nrLDPCDecode(in,bgn,maxNumIter)out для матрицы входных данных in, основной номер графика bgn, и максимальное количество декодирования итераций maxNumIter. Функция также возвращает фактическое количество итераций actNumIter и итоговые проверки четности на кодовую комбинацию finalParityChecks.
Декодер использует алгоритм передачи сообщений продукта суммы. Биты данных должны быть LDPC-закодированы, как задано в Разделе TS 38.212 5.3.2 [1].
[ задает дополнительные аргументы пары "имя-значение", в дополнение к входным параметрам в предыдущем синтаксисе.out,actNumIter,finalParityChecks] = nrLDPCDecode(___,Name,Value)
nrLDPCDecode функционируйте поддерживает эти четыре LDPC декодирование алгоритмов.
Реализация алгоритма распространения веры основана на алгоритме декодирования, представленном в [2]. Для переданной LDPC-закодированной кодовой комбинации, c, где , вход к декодеру LDPC является значением отношения логарифмической правдоподобности (LLR) .
В каждой итерации ключевые компоненты алгоритма обновляются на основе этих уравнений:
,
, инициализированный как перед первой итерацией, и
.
В конце каждой итерации, обновленная оценка значения LLR для переданного бита . Значение мягкое решение выход для . Если , трудное решение выход для 1. В противном случае выход 0.
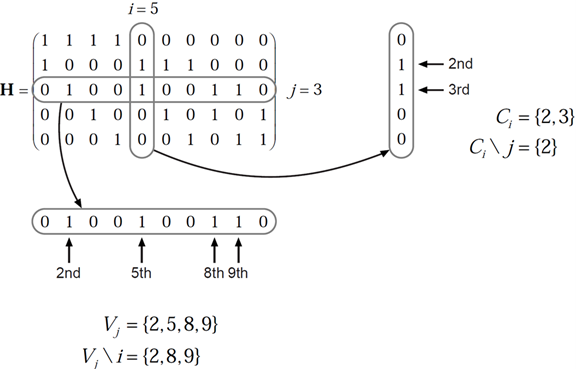
Индексируйте наборы и основаны на матрице проверки четности (PCM). Индексируйте наборы и соответствуйте всем ненулевым элементам в столбце i и строка j PCM, соответственно.
Этот рисунок подсвечивает расчет этих наборов индекса в данном PCM для i = 5 и j = 3.
Чтобы избежать бесконечных чисел в уравнениях алгоритма, atanh (1) и atanh (-1) установлены в 19,07 и –19.07, соответственно. Из-за конечной точности, MATLAB® возвращается 1 для tanh (19.07) и –1 для tanh (–19.07).
Когда аргумент пары "имя-значение" 'Termination' установлен в 'max', декодирование завершает работу после maxNumIter количество итераций. Когда 'Termination' установлен в 'early', декодирование завершает работу, когда всем проверкам четности удовлетворяют () или после maxNumIter количество итераций.
[1] 3GPP TS 38.212. “NR; Мультиплексирование и кодирование канала”. Проект Партнерства третьего поколения; Сеть радиодоступа Technical Specification Group.
[2] Gallager, Роберт Г. Имеющие малую плотность коды с проверкой четности, Кембридж, MA, нажатие MIT, 1963.
[3] Hocevar, D.E. "Уменьшаемая архитектура декодера сложности через многоуровневое декодирование кодов LDPC". В Семинаре IEEE по Системам Обработки сигналов, 2004. ГЛОТКИ 2004. doi: 10.1109/SIPS.2004.1363033
[4] Чен, Jinghu, Р.М. Таннер, К. Джонс и Ян Ли. "Улучшенные алгоритмы декодирования суммы min для неправильных кодов LDPC". В Продолжениях. Международный Симпозиум по Теории информации, 2005. ISIT 2005. doi: 10.1109/ISIT.2005.1523374
