Вычислите количество чтений, сопоставленных с геномными функциями
T = featurecount(GTFfile,Inputfile)Inputfile та карта на геномные функции, как задано в отформатированном GTF файле GTFfile. GTFfile задает файл аннотации. Inputfile задает имена BAM или файлов SAM, чтобы рассмотреть. Выход T таблица, где строки соответствуют функциям, и столбцы соответствуют входным файлам. Элементы таблицы состоят из количества отображения чтений с каждой функцией данного входного файла.
[___] = featurecount(___, дополнительные опции использования заданы одним или несколькими Name,Value)Name,Value парные аргументы.
GTFfile — Отформатированное GTF имя файлаОтформатированное GTF имя файла в виде вектора символов или строки.
Пример: 'Dmel_BDGP5_nohc.gtf'
Inputfile — Отформатированное BAM или SAM-отформатированное имя файлаОтформатированное BAM или SAM-отформатированное имя файла в виде вектора символов, строки, представляет в виде строки вектор или массив ячеек из символьных векторов.
Пример: 'rnaseq_sample1.sam'
Задайте дополнительные разделенные запятой пары Name,Value аргументы. Name имя аргумента и Value соответствующее значение. Name должен появиться в кавычках. Вы можете задать несколько аргументов в виде пар имен и значений в любом порядке, например: Name1, Value1, ..., NameN, ValueN.
'CountFragments',true задает, чтобы считать чтения как пары помощников.'BothEndsMapped' — Логическая переменная, указывающая, должен ли фрагмент иметь обоих помощников, сопоставилаfalse (значение по умолчанию) | trueЛогическая переменная, указывающая, должен ли фрагмент иметь обоих помощников, сопоставленных в виде true или false. Помощник, сопоставляющий информацию, получен из FLAG поле во входном файле. Значением по умолчанию является false.
'ProperlyPaired' — Логическая переменная, указывающая, должен ли фрагмент быть правильно соединенfalse (значение по умолчанию) | trueЛогическая переменная, указывающая, должен ли фрагмент быть правильно соединен в виде true или false. Помощник, соединяющий информацию, получен из FLAG поле во входном файле. Значением по умолчанию является false.
'ShowZeroCounts' — Логическая переменная, указывающая, сообщить ли о функциях или метафункциях с нулевым количествомfalse (значение по умолчанию) | trueЛогическая переменная, указывающая, сообщить ли о функциях или метафункциях с нулем, значит каждый входной файл в выходной таблице в виде true или false.
Значением по умолчанию является false, то есть, только строки с ненулевыми количествами и столбцы с ненулевыми количествами включены в выходную таблицу.
'OverlapMethod' — Метод, чтобы использовать при присвоении данного чтения, чтобы метапоказать'partial' (значение по умолчанию) | 'full' | 'max' | 'hits'Метод, чтобы использовать при присвоении данного чтения, чтобы метапоказать в виде 'partial'полныйMax , или 'hits'. Если 'Summarization' установлен в false, затем чтения присвоены функциям, вместо метафункций, на основе заданного метода.
В следующей таблице R относится к чтению или фрагменту, и M относится к метафункции.
| Метод | Описание |
|---|---|
'partial' | R присвоен M, если R перекрывается (даже частично) только с M. В противном случае R рассматривается неоднозначным. |
'full' | R присвоен M, если R полностью сопоставлен только в M, то есть, полностью перекрывающийся только M. В противном случае R рассматривается неоднозначным |
'max' | R присвоен M, если R удовлетворяет перекрывающимся критериям только M, или если R удовлетворяет перекрывающимся критериям несколькими метафункциями, но перекрывается полностью только с M. |
'hits' | R присвоен M, если R перекрывает даже частично только M, или если M является единственной метафункцией с самым большим количеством функций, пораженных R; в противном случае R рассматривается неоднозначным. |
Следующая принципиальная схема и таблица иллюстрируют результат этих методов в сочетании с 'CountMultiOverlap' аргумент пары "имя-значение". На рисунке чтение относится к последовательности короткого чтения из входного файла, и функция A и функция B относятся к функциям, перечисленным в файле GTF.
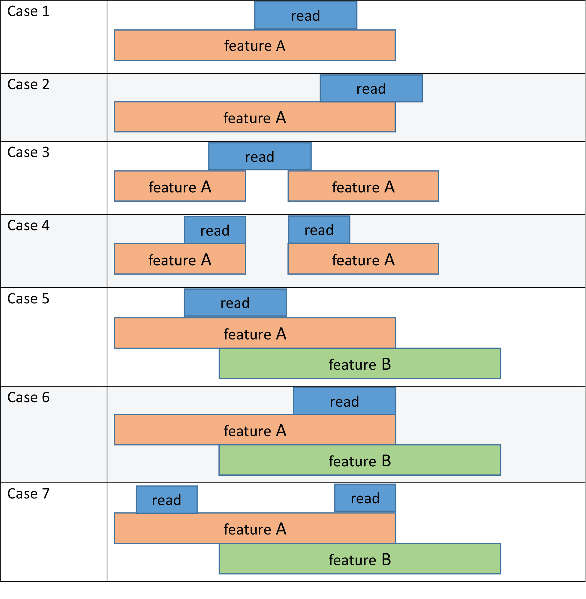
Каждые списки столбцов метода функция, что чтение присвоено на основе соответствующего метода. 'CountMultiOverlap' столбец указывает, установлена ли эта пара "имя-значение" в true или false и если это оказывает какое-либо влияние в результате каждого метода.
'CountMultiOverlap' | 'partial' | 'full' | 'max' | 'hits' | |
|---|---|---|---|---|---|
| Случай 1 | Никакой эффект начиная с чтения не сопоставляет только с одной функцией (покажите A). | покажите A | покажите A | покажите A | покажите A |
| Случай 2 | Никакой эффект начиная с чтения не сопоставляет только с одной функцией (покажите A). | покажите A | никакая функция | покажите A | покажите A |
| Случай 3 | Никакой эффект начиная с чтения не сопоставляет только с одной функцией (покажите A). | покажите A | никакая функция | покажите A | покажите A |
| Случай 4 | Никакой эффект начиная с чтения не сопоставляет только с одной функцией (покажите A). | покажите A | покажите A | покажите A | покажите A |
| Случай 5 | false | неоднозначный | покажите A | покажите A | неоднозначный |
true | покажите A, покажите B | покажите A | покажите A | покажите A, покажите B | |
| Случай 6 | false | неоднозначный | неоднозначный | неоднозначный | неоднозначный |
true | покажите A, покажите B | покажите A, покажите B | покажите A, покажите B | покажите A, покажите B | |
| Случай 7 | false | Неоднозначный | покажите A | покажите A | покажите A |
true | покажите A, покажите B | покажите A | покажите A | покажите A |
никакая функция не означает, что чтение не присвоено никакой функции. Если вы задали вторую выходную таблицу S, его Unassigned_noFeature строка постепенно увеличивается одной для такого вхождения. неоднозначный означает, что чтение не присвоено никакой функции, поскольку это удовлетворяет перекрывающимся критериям нескольких функций и Unassigned_ambiguous строка постепенно увеличивается одной для такого вхождения.
'UseParallel' — Логическая переменная, указывающая, вычислить ли параллельноfalse (значение по умолчанию) | trueЛогическая переменная, указывающая, вычислить ли параллельно в виде true или false.
Для того, чтобы выполнить расчет параллельно, у вас должен быть Parallel Computing Toolbox™. Если пул параллели MATLAB® не существует, каждый автоматически создается, когда опция автосоздания включена в ваших параллельных настройках. В противном случае расчет запускается в последовательном режиме.
Значением по умолчанию является false, то есть, последовательный режим.
'Verbose' — Логическая переменная, указывающая, отобразить ли прогресс расчетаtrue (значение по умолчанию) | falseЛогическая переменная, указывающая, отобразить ли прогресс расчета в виде true или false.
