

Линейные сети, обсужденные в этом разделе, похожи на perceptron, но их передаточная функция линейна, а не трудно ограничивает. Это позволяет их выходным параметрам брать любое значение, тогда как perceptron выход ограничивается или 0 или 1. Линейные сети, как perceptron, могут только решить линейно отделимые задачи.
Здесь вы проектируете линейную сеть, которая, когда подарено набор данных входных векторов, производит выходные параметры соответствующих целевых векторов. Для каждого входного вектора можно вычислить выходной вектор сети. Различием между выходным вектором и его целевым вектором является ошибка. Вы хотели бы найти значения для сетевых весов и смещаете таким образом, что сумма квадратов ошибок минимизирована или ниже определенного значения. Эта проблема управляема, потому что линейные системы имеют один ошибочный минимум. В большинстве случаев можно вычислить линейную сеть непосредственно, такой, что ее ошибка является минимумом для данных входных векторов и целевых векторов. В других случаях числовые проблемы запрещают прямое вычисление. К счастью, можно всегда обучать сеть, чтобы иметь минимальную ошибку при помощи наименьшего количества средних квадратичных (Видроу-Хофф) алгоритм.
Этот раздел вводит linearlayer, функция, которая создает линейный слой, и newlind, функция, которая проектирует линейный слой для определенной цели.
Линейный нейрон с входными параметрами R показывают ниже.
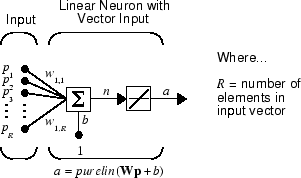
Эта сеть имеет ту же базовую структуру как perceptron. Единственная разница - то, что линейный нейрон использует линейную передаточную функцию purelin.
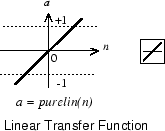
Линейная передаточная функция вычисляет, выход нейрона путем простого возвращения значения передал ей.
Этот нейрон может быть обучен изучить аффинную функцию своих входных параметров или найти линейную аппроксимацию к нелинейной функции. Линейная сеть не может, конечно, быть сделана выполнить нелинейный расчет.
Линейная сеть, показанная ниже, имеет один слой нейронов S, соединенных с входными параметрами R через матрицу весов W.
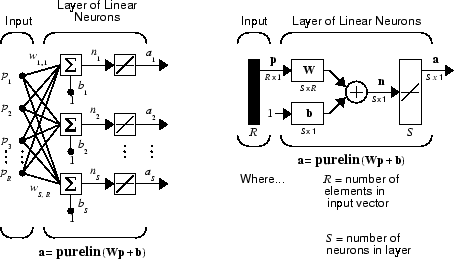
Обратите внимание на то, что фигура справа задает S - выходной вектор длины a.
Одноуровневую линейную сеть показывают. Однако эта сеть так же способна как многоуровневые линейные сети. Для каждой многоуровневой линейной сети существует эквивалентная одноуровневая линейная сеть.
Рассмотрите один линейный нейрон с двумя входными параметрами. Следующий рисунок показывает схему для этой сети.
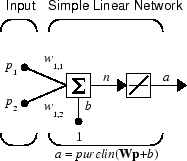
Матрица W веса в этом случае имеет только одну строку. Сетевой выход
или
Как perceptron, линейная сеть имеет контур решения, который определяется входными векторами, для которых сетевой вход n является нулем. Для n = 0 уравнение Wp + b = 0 задает такой контур решения, как показано ниже (адаптированный с благодарностью от [HDB96]).
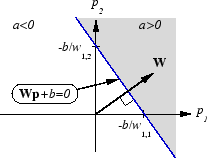
Входные векторы в верхней правой серой области приводят к выходу, больше, чем 0. Входные векторы в нижней левой белой области приводят к выходу меньше чем 0. Таким образом линейная сеть может использоваться, чтобы классифицировать объекты в две категории. Однако это может классифицировать таким образом, только если объекты линейно отделимы. Таким образом линейная сеть имеет то же ограничение как perceptron.
Можно создать это сетевое использование linearlayer, и сконфигурируйте его размерности с двумя значениями, таким образом, вход имеет два элемента, и выход имеет тот.
net = linearlayer; net = configure(net,[0;0],0);
Сетевые веса и смещения обнуляются по умолчанию. Вы видите текущие значения с командами
W = net.IW{1,1}
W =
0 0
и
b= net.b{1}
b =
0
Однако можно дать весам любые значения, с которыми вы хотите, такой как 2 и 3, соответственно,
net.IW{1,1} = [2 3];
W = net.IW{1,1}
W =
2 3
Можно установить и проверять смещение таким же образом.
net.b{1} = [-4];
b = net.b{1}
b =
-4
Можно симулировать линейную сеть для конкретного входного вектора. Попробовать
p = [5;6];
Можно найти сетевой выход с функцией sim.
a = net(p)
a =
24
Подводя итоги, можно создать линейную сеть с linearlayer, настройте его элементы, как вы хотите и симулируете его с sim.
Как perceptron изучение управляет, наименьшее количество среднеквадратичной погрешности (LMS), алгоритм является примером контролируемого обучения, в котором правилу изучения предоставляют набор примеров желаемого сетевого поведения:
Здесь pq является входом к сети, и tq является соответствующий целевой выход. Когда каждый вход применяется к сети, сетевой выход сравнивается с целью. Ошибка вычисляется как различие между целевым выходом и сетевым выходом. Цель состоит в том, чтобы минимизировать среднее значение суммы этих ошибок.
LMS-алгоритм настраивает веса и смещения линейной сети, чтобы минимизировать эту среднеквадратичную погрешность.
К счастью, индекс эффективности среднеквадратичной погрешности для линейной сети является квадратичной функцией. Таким образом индекс эффективности будет или иметь один глобальный минимум, слабый минимум или никакой минимум, в зависимости от характеристик входных векторов. А именно, характеристики входных векторов определяют, существует ли уникальное решение.
Можно найти больше об этой теме в Главе 10 [HDB96].
В отличие от большинства других сетевых архитектур, линейные сети могут быть спроектированы непосредственно, если введенные/предназначаемые векторные пары известны. Можно получить определенные сетевые значения для весов и смещений, чтобы минимизировать среднеквадратичную погрешность при помощи функции newlind.
Предположим, что входные параметры и цели
P = [1 2 3]; T= [2.0 4.1 5.9];
Теперь можно спроектировать сеть.
net = newlind(P,T);
Можно симулировать сетевое поведение, чтобы проверять, что проект был сделан правильно.
Y = net(P)
Y =
2.0500 4.0000 5.9500
Обратите внимание на то, что сетевые выходные параметры вполне близко к желаемым целям.
Вы можете попробовать Ассоциацию Шаблона, Показывающую Ошибочную Поверхность. Это показывает ошибочные поверхности для конкретной проблемы, иллюстрирует проект и строит спроектированное решение.
Можно также использовать функцию newlind спроектировать линейные сети, имеющие задержки входа. Такие сети обсуждены в Линейных Сетях с Задержками. Во-первых, однако, задержки должны быть обсуждены.
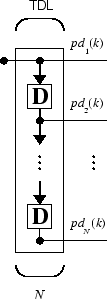
Вам нужен новый компонент, коснувшаяся линия задержки, чтобы полностью использовать линейную сеть. Такую линию задержки показывают ниже. Там входной сигнал входит слева и проходит через N-1 задержка. Выходом коснувшейся линии задержки (TDL) является N - размерный вектор, составленный из входного сигнала в текущее время, предыдущего входного сигнала, и т.д.
Можно объединить коснувшуюся линию задержки с линейной сетью, чтобы создать показанный линейный фильтр.
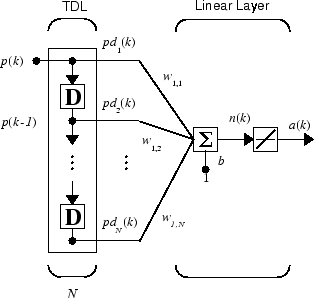
Выходом фильтра дают
Показанная сеть упомянута в поле цифровой обработки сигналов как фильтр конечной импульсной характеристики (FIR) [WiSt85]. Посмотрите на код, используемый, чтобы сгенерировать и симулировать такую сеть.
Предположим, что вы хотите линейный слой, который выводит последовательность T, учитывая последовательность P и две начальных входных задержки утверждают Pi.
P = {1 2 1 3 3 2};
Pi = {1 3};
T = {5 6 4 20 7 8};
Можно использовать newlind спроектировать сеть с задержками, чтобы дать соответствующие выходные параметры для входных параметров. Начальная буква задержки выходные параметры предоставляется в качестве третьего аргумента, как показано ниже.
net = newlind(P,T,Pi);
Можно получить выход спроектированной сети с
Y = net(P,Pi)
дать
Y = [2.7297] [10.5405] [5.0090] [14.9550] [10.7838] [5.9820]
Как вы видите, сетевые выходные параметры не точно равны целям, но они близки, и среднеквадратичная погрешность минимизирована.
LMS-алгоритм или алгоритм обучения Видроу-Хофф, основан на аппроксимированной процедуре наискорейшего спуска. Здесь снова, линейные сети обучены на примерах правильного поведения.
Widrow и Hoff имели понимание, что они могли оценить среднеквадратичную погрешность при помощи квадратичной невязки в каждой итерации. Если вы берете частную производную квадратичной невязки относительно весов и смещений в k th итерация, вы имеете
для j = 1,2, …, R и
Затем посмотрите на частную производную относительно ошибки.
или
Здесь pi (k) является ith элементом входного вектора в k-ой итерации.
Это может быть упрощено до
и
Наконец, измените матрицу веса, и смещение будет
2αe (k) p (k)
и
2αe (k)
Эти два уравнения формируют основание Видроу-Хофф (LMS) алгоритм обучения.
Эти результаты могут быть расширены к случаю нескольких нейронов и написаны в матричной форме как
Здесь ошибка e и смещение b являются векторами, и α является скоростью обучения. Если α является большим, изучение происходит быстро, но если это является слишком большим, это может привести к нестабильности, и ошибки могут даже увеличиться. Чтобы гарантировать устойчивое изучение, скорость обучения должна быть меньше обратной величины самого большого собственного значения корреляционной матрицы pTp входных векторов.
Вы можете хотеть считать часть Главы 10 [HDB96] для получения дополнительной информации о LMS-алгоритме и его сходимости.
К счастью, существует функция тулбокса, learnwh, это делает все вычисление для вас. Это вычисляет изменение в весах как
dw = lr*e*p'
и смещение изменяется как
db = lr*e
Постоянные 2, показанные несколько линий выше, были поглощены в скорость обучения кода lr. Функция maxlinlr вычисляет эту максимальную устойчивую скорость обучения lr как 0,999 * P'P.
Введите help learnwh и help maxlinlr для получения дополнительной информации об этих двух функциях.
Линейные сети могут быть обучены, чтобы выполнить линейную классификацию с функцией train. Эта функция применяет каждый вектор из набора входных векторов и вычисляет сетевой вес, и смещение постепенно увеличивается из-за каждых из входных параметров согласно learnp. Затем сеть настроена с суммой всех этих коррекций. Каждый проходит через входные векторы, называется эпохой. Это контрастирует с adapt который настраивает веса для каждого входного вектора, когда он представлен.
Наконец, train применяет входные параметры к новой сети, вычисляет выходные параметры, сравнивает их со связанными целями и вычисляет среднеквадратичную погрешность. Если ошибочной цели удовлетворяют, или если максимальное количество эпох достигнуто, обучение останавливается, и train возвращает новую сеть и учебную запись. В противном случае train проходит другую эпоху. К счастью, LMS-алгоритм сходится, когда эта процедура выполняется.
Простая проблема иллюстрирует эту процедуру. Считайте линейную сеть введенной ранее.
Предположим, что у вас есть следующая проблема классификации.
Здесь существует четыре входных вектора, и вы хотите сеть, которая производит выход, соответствующий каждому входному вектору, когда тот вектор представлен.
Использование train получить веса и смещения для сети, которая производит правильные цели для каждого входного вектора. Начальные веса и смещение для новой сети 0 по умолчанию. Установите ошибочную цель к 0,1, а не примите ее значение по умолчанию 0.
P = [2 1 -2 -1;2 -2 2 1]; T = [0 1 0 1]; net = linearlayer; net.trainParam.goal= 0.1; net = train(net,P,T);
Проблема запускается в течение 64 эпох, достигая среднеквадратичной погрешности 0,0999. Новые веса и смещение
weights = net.iw{1,1}
weights =
-0.0615 -0.2194
bias = net.b(1)
bias =
[0.5899]
Можно симулировать новую сеть как показано ниже.
A = net(P)
A =
0.0282 0.9672 0.2741 0.4320
Можно также вычислить ошибку.
err = T - sim(net,P) err = -0.0282 0.0328 -0.2741 0.5680
Обратите внимание на то, что цели не поняты точно. Проблема запустилась бы дольше в попытке добраться, совершенные результаты имели меньшую ошибочную цель, выбранный, но в этой проблеме не возможно получить цель 0. Сеть ограничивается в ее возможности. Смотрите Ограничения и Предостережения для примеров различных ограничений.
Этот пример программы, Обучение Линейный Нейрон, показывает обучение линейного нейрона и строит траекторию веса и ошибку во время обучения.
Вы можете также попытаться запустить пример программы
nnd10lc. Это решает классику и исторически интересную проблему, показывает, как сеть может быть обучена, чтобы классифицировать различные шаблоны и показывает, как обучивший сеть отвечает, когда шумные шаблоны представлены.
Линейные сети могут только изучить линейные соотношения между векторами ввода и вывода. Таким образом они не могут найти решения некоторых проблем. Однако, даже если идеальное решение не будет существовать, линейная сеть минимизирует сумму квадратичных невязок если скорость обучения lr достаточно мал. Сеть найдет столь близкое решение, как возможно, учитывая линейную природу архитектуры сети. Это свойство содержит, потому что ошибочная поверхность линейной сети является многомерной параболой. Поскольку параболы имеют только один минимум, алгоритм градиентного спуска (такой как правило LMS) должен произвести решение в том минимуме.
Линейные сети имеют различные другие ограничения. Некоторые из них обсуждены ниже.
Рассмотрите сверхрешительную систему. Предположим, что у вас есть сеть, которая будет обучена с четырьмя входными векторами с одним элементом и четырьмя целями. Идеальное решение wp + b = t для каждых из входных параметров не может существовать, поскольку существует четыре уравнения ограничения, и только один вес и одно смещение, чтобы настроить. Однако правило LMS все еще минимизирует ошибку. Вы можете попробовать Линейный Припадок Нелинейной проблемы, чтобы видеть, как это сделано.
Рассмотрите один линейный нейрон с одним входом. На этот раз, в Недоопределенной проблеме, обучите его только на одном входном векторе с одним элементом и его целевом векторе с одним элементом:
P = [1.0]; T = [0.5];
Обратите внимание на то, что, в то время как существует только одно ограничение, являющееся результатом одной пары входа/цели, существует две переменные, вес и смещение. Наличие большего количества переменных, чем ограничения приводит к недоопределенной проблеме с бесконечным числом решений. Можно попробовать Недоопределенную проблему исследовать эту тему.
Обычно это - прямое задание, чтобы определить, может ли линейная сеть решить задачу. Обычно, если линейная сеть имеет, по крайней мере, как много степеней свободы (S *R + S = количество весов и смещений) как ограничения (Q = пары векторов входа/цели), то сеть может решить задачу. Это верно кроме тех случаев, когда входные векторы линейно зависимы, и они применяются к сети без смещений. В этом случае, как показано с примером Линейно зависимая проблема, сеть не может решить задачу с нулевой ошибкой. Вы можете хотеть попробовать Линейно зависимую проблему.
Можно всегда обучать линейную сеть с правилом Видроу-Хофф найти минимальное ошибочное решение для его весов и смещений, пока скорость обучения мала достаточно. Пример Слишком Большая Скорость обучения показывает то, что происходит, когда нейрон с одним входом и смещением обучен со скоростью обучения, больше, чем рекомендуемый maxlinlr. Сеть обучена с двумя различными скоростями обучения, чтобы показать результаты использования слишком большой скорости обучения.