Datastore является объектом для чтения одного файла или набора файлов или данных. Datastore действует как репозиторий для данных, которые имеют ту же структуру и форматирование. Например, каждый файл в datastore должен содержать данные того же типа (такой как числовые или текст) появляющийся в том же порядке, и разделенный тем же разделителем.
Datastore полезен когда:
Каждый файл в наборе может быть слишком большим, чтобы уместиться в памяти. Datastore позволяет вам читать и анализировать данные из каждого файла в меньших фрагментах, которые действительно умещаются в памяти.
Файлы в наборе имеют произвольные имена. Datastore действует как репозиторий для файлов в одной или нескольких папках. Файлы не требуются, чтобы иметь последовательные имена.
Можно создать datastore на основе типа данных или приложения. Различные типы хранилищ данных содержат свойства, подходящие для типа данных, которые они поддерживают. Например, см. следующую таблицу для списка хранилищ данных MATLAB®. Для полного списка хранилищ данных смотрите, Выбирают Datastore for File Format или Application.
| Тип файла или данных | Тип хранилища данных |
|---|---|
| Текстовые файлы, содержащие данные в столбцах, включая файлы CSV. | TabularTextDatastore |
Файлы изображений, включая форматы, которые поддерживаются imread такой как JPEG и PNG. | ImageDatastore |
Файлы электронной таблицы с поддерживаемым форматом Excel®, такие как .xlsx. | SpreadsheetDatastore |
Данные о паре "ключ-значение", которые являются входными параметрами к или выходными параметрами mapreduce. | KeyValueDatastore |
| Файлы Parquet, содержащие данные в столбцах. | ParquetDatastore |
| Пользовательские форматы файлов. Требует обеспеченной функции для чтения данных. | FileDatastore |
Datastore для выгрузки tall массивы. | TallDatastore |
Используйте tabularTextDatastore функция, чтобы создать datastore из файла примера airlinesmall.csv, который содержит информацию об отъезде и прибытии об отдельных полетах. Результатом является TabularTextDatastore объект.
ds = tabularTextDatastore('airlinesmall.csv')ds =
TabularTextDatastore with properties:
Files: {
' ...\matlab\toolbox\matlab\demos\airlinesmall.csv'
}
Folders: {
' ...\matlab\toolbox\matlab\demos'
}
FileEncoding: 'UTF-8'
AlternateFileSystemRoots: {}
PreserveVariableNames: false
ReadVariableNames: true
VariableNames: {'Year', 'Month', 'DayofMonth' ... and 26 more}
DatetimeLocale: en_US
Text Format Properties:
NumHeaderLines: 0
Delimiter: ','
RowDelimiter: '\r\n'
TreatAsMissing: ''
MissingValue: NaN
Advanced Text Format Properties:
TextscanFormats: {'%f', '%f', '%f' ... and 26 more}
TextType: 'char'
ExponentCharacters: 'eEdD'
CommentStyle: ''
Whitespace: ' \b\t'
MultipleDelimitersAsOne: false
Properties that control the table returned by preview, read, readall:
SelectedVariableNames: {'Year', 'Month', 'DayofMonth' ... and 26 more}
SelectedFormats: {'%f', '%f', '%f' ... and 26 more}
ReadSize: 20000 rows
OutputType: 'table'
RowTimes: []
Write-specific Properties:
SupportedOutputFormats: ["txt" "csv" "xlsx" "xls" "parquet" "parq"]
DefaultOutputFormat: "txt"После создания datastore можно предварительно просмотреть данные, не имея необходимость загружать все это в память. Можно задать переменные (столбцы) интереса с помощью SelectedVariableNames свойство предварительно просмотреть или только для чтения те переменные.
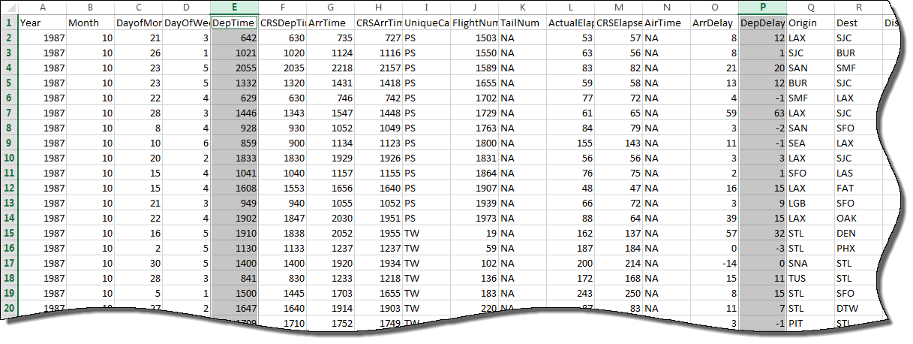
ds.SelectedVariableNames = {'DepTime','DepDelay'};
preview(ds)ans =
8×2 table
DepTime DepDelay
_______ ________
642 12
1021 1
2055 20
1332 12
629 -1
1446 63
928 -2
859 -1 Можно задать значения в данных, которые представляют отсутствующие значения. В airlinesmall.csv, отсутствующие значения представлены NA.
ds.TreatAsMissing = 'NA';Если все данные в datastore для переменных интереса умещаются в памяти, можно считать его с помощью readall функция.
T = readall(ds);
В противном случае считайте данные в меньших подмножествах, которые действительно умещаются в памяти, с помощью read функция. По умолчанию, read функционируйте чтения от TabularTextDatastore 20 000 строк за один раз. Однако можно изменить это значение путем присвоения нового значения ReadSize свойство.
ds.ReadSize = 15000;
Сбросьте datastore к начальному состоянию перед перечитыванием, с помощью reset функция. Путем вызова read функция в while цикл, можно выполнить промежуточные вычисления на каждом подмножестве данных, и затем агрегировать промежуточные результаты в конце. Этот код вычисляет максимальное значение DepDelay переменная.
reset(ds) X = []; while hasdata(ds) T = read(ds); X(end+1) = max(T.DepDelay); end maxDelay = max(X)
maxDelay =
1438Если данные в каждом отдельном файле умещаются в памяти, можно указать что каждый вызов read должен считать один полный файл, а не определенное количество строк.
reset(ds) ds.ReadSize = 'file'; X = []; while hasdata(ds) T = read(ds); X(end+1) = max(T.DepDelay); end maxDelay = max(X);
В дополнение к чтению подмножеств данных в datastore можно применить map и reduce функции к использованию datastore mapreduce или создайте использование длинного массива tall. Для получения дополнительной информации смотрите Начало работы с MapReduce и Длинные массивы для Данных, которые не помещаются в память.
fileDatastore | imageDatastore | KeyValueDatastore | mapreduce | spreadsheetDatastore | tabularTextDatastore | tall
