Симулируйте модель SimBiology, добавив изменения путем выборки ошибочной модели
[ynew,parameterEstimates]
= random(resultsObj)
[ynew,parameterEstimates]
= random(resultsObj,data,dosing)
[ возвращает результаты симуляции ynew,parameterEstimates]
= random(resultsObj)ynew с добавленным шумом с помощью ошибочной информации о модели задан resultsObj.ErrorModelInfo свойство и оцененные значения параметров parameterEstimates.
[ использует заданный ynew,parameterEstimates]
= random(resultsObj,data,dosing)data и dosing информация.
Примечание
Шум только добавляется к состояниям, которые являются ответами, которые являются состояниями, включенными в responseMap входной параметр, когда вы вызвали sbiofit. Если существует отдельная ошибочная модель для каждого ответа, шум добавляется к каждому ответу отдельно с помощью соответствующей ошибочной модели.
Этот пример использует дрожжи гетеротримерные данные модели белка G и экспериментальные данные, о которых сообщают [1]. Для получения дополнительной информации о модели, смотрите раздел Background в Сканировании Параметра, Оценке Параметра и Анализе чувствительности в Дрожжах Гетеротримерный Цикл Белка G.
Загрузите модель белка G.
sbioloadproject gproteinВведите экспериментальные данные, содержащие курс времени для части активного белка G, как сообщается в ссылочной газете [1].
time = [0 10 30 60 110 210 300 450 600]'; GaFracExpt = [0 0.35 0.4 0.36 0.39 0.33 0.24 0.17 0.2]';
Создайте groupedData основанный на объектах на экспериментальных данных.
tbl = table(time,GaFracExpt); grpData = groupedData(tbl);
Сопоставьте соответствующий компонент модели с экспериментальными данными. Другими словами, укажите, которому разновидность в модели соответствует который переменная отклика в данных. В этом примере сопоставьте параметр модели GaFrac к переменной GaFracExpt экспериментальных данных от grpData.
responseMap = 'GaFrac = GaFracExpt'; Используйте estimatedInfo объект задать параметр модели kGd в качестве параметра быть оцененным.
estimatedParam = estimatedInfo('kGd');Выполните оценку параметра. Используйте аргумент пары "имя-значение" 'ErrorModel' задавать ошибочную модель, которая добавляет ошибку в данные моделирования.
fitResult = sbiofit(m1,grpData,responseMap,estimatedParam,'ErrorModel','proportional');
Просмотрите предполагаемое значение параметров kGd.
fitResult.ParameterEstimates
ans =
Name Estimate StandardError
_____ ________ _____________
'kGd' 0.11 0.00064116 Используйте random метод, чтобы получить данные моделирования с добавленным шумом с помощью пропорциональной ошибочной модели, которая была задана sbiofit. Обратите внимание на то, что шум добавляется только к состоянию ответа, которое является GaFrac параметр.
[ynew,paramEstim] = random(fitResult);
Выберите данные моделирования для GaFrac параметр.
GaFracNew = select(ynew,{'Name','GaFrac'});Постройте результаты симуляции.
plot(GaFracNew.Time,GaFracNew.Data)
hold on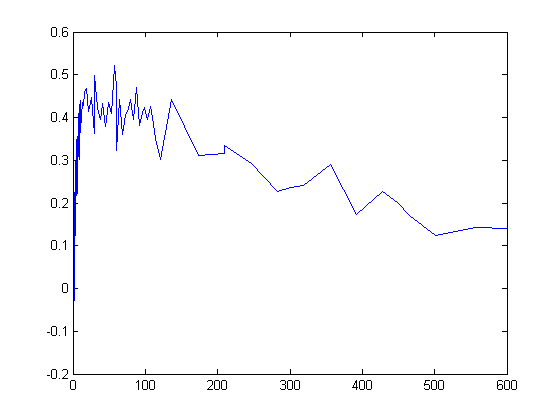
Отобразите экспериментальные данные на графике, чтобы сравнить его с симулированными данными.
plot(time,GaFracExpt,'Color','k','Marker','o') legend('GaFracNew','GaFracExpt')
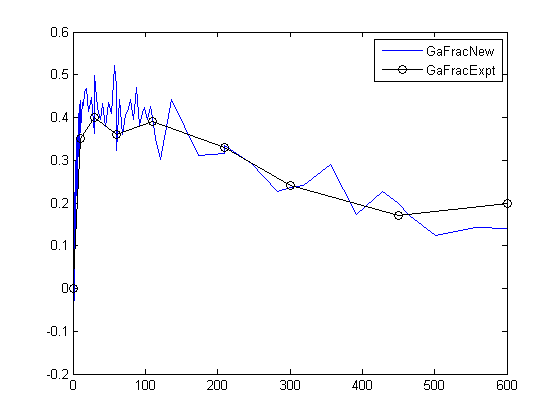
[1] И, T-M., Kitano, H. и Саймон, M. (2003). Количественная характеристика дрожжей гетеротримерный цикл белка G. PNAS. 100, 10764–10769.
