Можно ускорить оценку параметра с помощью параллельных вычислений на многоядерных процессорах или многопроцессорных сетях. Используйте параллельные вычисления с Parameter Estimator и sdo.optimize оценить параметры с помощью fmincon, lsqonlin, и patternsearch методы. Параллельные вычисления не поддерживаются для fminsearch (Simplex search) метод.
Когда вы оцениваете параметры модели с помощью параллельных вычислений, программное обеспечение использует доступный параллельный пул. Если ни один не доступен, и вы выбираете Automatically create a parallel pool в своих настройках Parallel Computing Toolbox™, программное обеспечение запускает параллельный пул с помощью настроек в тех настройках. Чтобы открыть параллельный пул, который использует определенный кластерный профиль, используйте:
parpool(MyProfile);
MyProfile имя кластерного профиля.
Для получения информации относительно создания кластерного профиля, смотрите, Добавляют и Изменяют Кластерные Профили (Parallel Computing Toolbox).
Model dependencies является любыми моделями, на которые ссылаются, данные, такими как переменные модели, S-функции и дополнительные файлы, необходимые, чтобы запустить модель. Прежде, чем запустить оптимизацию, проверьте, что зависимости моделей завершены. В противном случае можно получить неожиданные результаты.
Когда вы используете параллельные вычисления, программное обеспечение Simulink® Design Optimization™ помогает вам идентифицировать зависимости моделей. Для этого программное обеспечение использует Зависимость Анализатор. Анализ зависимостей не может найти все файлы требуемыми вашей моделью. Чтобы узнать больше, смотрите Зависимость Осциллограф Анализатора и Ограничения. Если ваша модель имеет зависимости, которые не обнаружены или недоступны параллельными рабочими пула, то добавьте их в список зависимостей моделей.
Зависимости сделаны доступными для параллельных рабочих пула путем определения одного из следующего:
Зависимости от файла: файлы зависимости моделей копируются в параллельных рабочих пула.
Зависимости от пути: пути к зависимостям моделей добавляются к путям параллельных рабочих пула. Если вы работаете в многоплатформенном сценарии, гарантируете, что пути совместимы через платформы.
Используя файл зависимости рекомендуются, однако, в некоторых случаях может быть лучше выбрать зависимости от пути. Например, если параллельные вычисления настраиваются на локальном многоядерном компьютере, использование зависимостей от пути предпочтено, когда использование зависимостей от файла создает несколько копий зависимых файлов на локальном компьютере.
Для получения дополнительной информации см.:
Оценить параметры модели с помощью параллельных вычислений в Parameter Estimator:
Убедитесь, что программное обеспечение может получить доступ к рабочим пула параллели, которые используют соответствующий кластерный профиль.
Для получения дополнительной информации смотрите, Конфигурируют Вашу Систему для Параллельных вычислений.
Откройте Parameter Estimator для модели Simulink.
Сконфигурируйте данные об оценке, параметры оценки и состояния, и, опционально, настройки оценки.
Для получения дополнительной информации смотрите, Задают Данные об Оценке, Задают Параметры для Оценки и Задают Опции Оценки.
На вкладке Parameter Estimation нажмите ![]() More Options, чтобы открыть диалоговое окно Estimation Options.
More Options, чтобы открыть диалоговое окно Estimation Options.
Выберите вкладку Parallel Options.
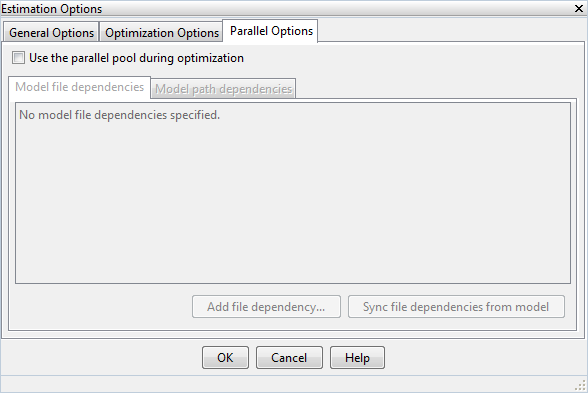
Установите флажок Use the parallel pool during optimization.
Эта опция проверяет на зависимости в вашей модели Simulink. Зависимости от файла отображены в поле списка Model file dependencies и соответствующем пути к файлам в Model path dependencies. Файлы, перечисленные в Model file dependencies, копируются в удаленных рабочих.
Примечание
Автоматическая проверка зависимостей не может обнаружить все зависимости в вашей модели.
Для получения дополнительной информации смотрите Зависимости моделей. В этом случае добавьте необнаруженные зависимости вручную.
Добавьте любые зависимости от файла, которые не обнаруживает автоматическая проверка.
Задайте файлы в поле списка Model file dependencies, разделенном точками с запятой или на отдельных линиях.

В качестве альтернативы нажмите Add file dependency, чтобы открыть диалоговое окно и выбрать файл, чтобы добавить.
Примечание
Если вы не хотите копировать файлы в удаленных рабочих, удалите все записи в поле списка Model file dependencies. Заполните поле списка Model path dependencies путем нажатия на Sync path dependencies from model и добавьте любые необнаруженные зависимости от пути. Кроме того, в поле списка, обновите пути на локальных дисках сделать их доступными для удаленных рабочих. Например, измените C:\ к \\\\hostname\\C$\\.
Если вы изменяете модель Simulink, повторно синхронизируете зависимости, чтобы гарантировать, что обнаруживаются любые новые зависимости. Нажмите Sync file dependencies from model во вкладке Parallel Options, чтобы повторно выполнить автоматическую проверку зависимости на вашу модель.
Это действие обновляет поле списка Model file dependencies с любой новой зависимостью от файла, найденной в модели.
Нажмите OK.
Во вкладке Parameter Estimation нажмите Estimate, чтобы оценить параметры модели с помощью параллельных вычислений.
Для получения информации о поиске и устранении неисправностей проблем, связанных с оценкой с помощью параллельных вычислений, смотрите Поиск и устранение проблем.
Использовать параллельные вычисления для оценки параметра в командной строке:
Убедитесь, что программное обеспечение может получить доступ к рабочим пула параллели, которые используют соответствующий кластерный профиль.
Для получения дополнительной информации смотрите, Конфигурируют Вашу Систему для Параллельных вычислений.
Откройте модель.
Сконфигурируйте эксперимент оценки. Например, смотрите Оценочные Значения Параметра модели (Код).
Включите параллельные вычисления с помощью набора опции оптимизации, opt.
opt = sdo.OptimizeOptions; opt.UseParallel = true;
Найдите зависимости моделей.
[dirs,files] = sdo.getModelDependencies(modelname)
Примечание
sdo.getModelDependencies может не обнаружить все зависимости в вашей модели. Для получения дополнительной информации смотрите Зависимости моделей. В этом случае добавьте необнаруженные зависимости вручную.
Измените files включать любые зависимости от файла что sdo.getModelDependencies не обнаруживает.
files = vertcat(files,'C:\matlab\work\filename.m')Примечание
Если вы не хотите копировать файлы в удаленных рабочих, используйте зависимости от пути. Добавьте любые необнаруженные зависимости от пути в dirs и обновите пути на локальных дисках сделать их доступными для удаленных рабочих. Смотрите sdo.getModelDependencies для получения дополнительной информации.
Добавьте зависимости от файла для оптимизации.
opt.ParallelFileDependencies = files;
Запустите оптимизацию.
[pOpt,opt_info] = sdo.optimize(opt_fcn,param,opt);
Для получения информации о поиске и устранении неисправностей проблем, связанных с оценкой с помощью параллельных вычислений, смотрите Поиск и устранение проблем.
Различная числовая точность на машинах клиента и рабочего может произвести незначительно различные результаты симуляции. Таким образом метод оптимизации может выбрать различное решение путь и привести к различному результату.
Когда вы используете параллельные вычисления с Pattern search метод, поиск является более всесторонним и может привести к различному решению. Чтобы узнать больше, смотрите Параллельные вычисления с методом поиска Шаблона.
Когда вы оцениваете несколько параметров или когда модель не занимает много времени симулировать, вы не видите ускорение во время оценки. В таких случаях издержки, сопоставленные с созданием и распределением параллельных задач, перевешивают преимущества выполнения оценки параллельно.
Используя Pattern search метод с параллельными вычислениями не может ускорить время оптимизации. Ни с чем не сравнимое вычисление, метод останавливает поиск в каждой итерации, как только это находит решение лучше, чем текущее решение. Поиск варианта решения является более всесторонним, когда вы используете параллельные вычисления. Несмотря на то, что количество итераций может быть больше, оптимизация, не используя параллельные вычисления может быть быстрее.
Чтобы узнать больше об ожидаемом ускорении, смотрите Параллельные вычисления с методом поиска Шаблона.
Диагностировать проблему:
Запустите оптимизацию для нескольких итераций ни с чем не сравнимое вычисление, чтобы видеть, прогрессирует ли оптимизация.
Проверяйте, есть ли у удаленных рабочих доступ ко всем зависимостям моделей. Зависимости моделей включают переменные данных и файлы, требуемые моделью запускаться.
Чтобы узнать больше, смотрите Зависимости моделей.
Когда вы используете параллельные вычисления с Pattern search метод, программное обеспечение должно ожидать, пока текущая итерация оптимизации не завершается, прежде чем это уведомит рабочих, чтобы остановиться. Оптимизация не завершает работу сразу, когда вы нажимаете Stop, и, вместо этого, кажется, продолжает запускаться.
sdo.getModelDependencies | sdo.optimize | sdo.OptimizeOptions | parpool (Parallel Computing Toolbox)
