

Потеря классификации перезамены для наивного классификатора Байеса
L = resubLoss(Mdl)L) или потеря классификации в выборке, для наивного классификатора Байеса Mdl использование обучающих данных сохранено в Mdl.X и соответствующие метки класса сохранены в Mdl.Y.
Потеря классификации (L) обобщение или качественная мера по перезамене. Его интерпретация зависит от схемы взвешивания и функции потерь; в целом лучшие классификаторы дают к меньшим значениям классификации потерь.
Функции Classification loss измеряют прогнозирующую погрешность моделей классификации. Когда вы сравниваете тот же тип потери среди многих моделей, более низкая потеря указывает на лучшую прогнозную модель.
Рассмотрите следующий сценарий.
L является средневзвешенной потерей классификации.
n является объемом выборки.
Для бинарной классификации:
yj является наблюдаемой меткой класса. Программные коды это как –1 или 1, указывая на отрицательный или положительный класс, соответственно.
f (Xj) является необработанной классификационной оценкой для наблюдения (строка) j данных о предикторе X.
mj = yj f (Xj) является классификационной оценкой для классификации наблюдения j в класс, соответствующий yj. Положительные значения mj указывают на правильную классификацию и не способствуют очень средней потере. Отрицательные величины mj указывают на неправильную классификацию и значительно способствуют средней потере.
Для алгоритмов, которые поддерживают классификацию мультиклассов (то есть, K ≥ 3):
yj* является вектором из K – 1 нуль, с 1 в положении, соответствующем истинному, наблюдаемому классу yj. Например, если истинный класс второго наблюдения является третьим классом и K = 4, то y 2* = [0 0 1 0] ′. Порядок классов соответствует порядку в ClassNames свойство входной модели.
f (Xj) является длиной вектор K из музыки класса к наблюдению j данных о предикторе X. Порядок баллов соответствует порядку классов в ClassNames свойство входной модели.
mj = yj* ′ f (Xj). Поэтому mj является скалярной классификационной оценкой, которую модель предсказывает для истинного, наблюдаемого класса.
Весом для наблюдения j является wj. Программное обеспечение нормирует веса наблюдения так, чтобы они суммировали к соответствующей предшествующей вероятности класса. Программное обеспечение также нормирует априорные вероятности, таким образом, они суммируют к 1. Поэтому
Учитывая этот сценарий, следующая таблица описывает поддерживаемые функции потерь, которые можно задать при помощи 'LossFun' аргумент пары "имя-значение".
| Функция потерь | Значение LossFun | Уравнение |
|---|---|---|
| Биномиальное отклонение | 'binodeviance' | |
| Экспоненциальная потеря | 'exponential' | |
| Ошибка классификации | 'classiferror' | Ошибка классификации является взвешенной частью неправильно классифицированных наблюдений где метка класса, соответствующая классу с максимальной апостериорной вероятностью. I {x} является функцией индикатора. |
| Потеря стержня | 'hinge' | |
| Потеря логита | 'logit' | |
| Минимальная стоимость | 'mincost' | Программное обеспечение вычисляет взвешенную минимальную стоимость с помощью этой процедуры для наблюдений j = 1..., n.
Взвешенная, средняя, минимальная потеря стоимости |
| Квадратичная потеря | 'quadratic' |
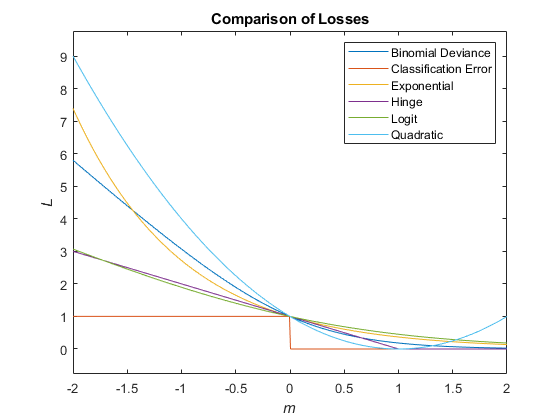
Этот рисунок сравнивает функции потерь (кроме 'mincost') для одного наблюдения по m. Некоторые функции нормированы, чтобы пройти [0,1].
ClassificationNaiveBayes | CompactClassificationNaiveBayes | fitcnb | loss | predict | resubPredict