Потеря модели пошагового обучения на пакете данных
loss возвращает регрессию или потерю классификации сконфигурированной модели пошагового обучения для линейной регрессии (incrementalRegressionLinear объект) или линейная, бинарная классификация (incrementalClassificationLinear объект.
Измерять производительность модели на потоке данных и хранить результаты в выходной модели, вызове updateMetrics или updateMetricsAndFit вместо этого.
Можно измерить уровень инкрементной модели при потоковой передаче данных тремя способами:
Совокупные метрики измеряют уровень начиная с запуска пошагового обучения.
Метрики окна измеряют уровень на заданном окне наблюдений. Метрики обновляют каждый раз процессы модели заданное окно.
loss функция измеряет уровень только на заданном пакете данных.
Загрузите набор данных деятельности человека. Случайным образом переставьте данные.
load humanactivity n = numel(actid); rng(1); % For reproducibility idx = randsample(n,n); X = feat(idx,:); Y = actid(idx);
Для получения дополнительной информации на наборе данных, отобразите Description.
Ответы могут быть одним из пяти классов. Разделите пополам ответ путем идентификации, перемещается ли предмет (actid > 2).
Y = Y > 2;
Создайте инкрементную линейную модель SVM для бинарной классификации. Главный это для loss путем определения имен классов предшествующее распределение класса является универсальным, произвольным коэффициентом и значениями смещения. Задайте метрический размер окна 1 000 наблюдений.
p = size(X,2); Beta = randn(p,1); Bias = randn(1); Mdl = incrementalClassificationLinear('Beta',Beta,'Bias',Bias,... 'ClassNames',unique(Y),'Prior','uniform','MetricsWindowSize',1000);
Mdl incrementalClassificationLinear модель. Все его свойства только для чтения. Как альтернатива определению произвольных значений, можно принять любые из следующих мер к началу модель:
Обучите модель SVM с помощью fitcsvm или fitclinear на подмножестве данных (если такие данные доступны), и затем преобразуют модель в инкрементного ученика при помощи incrementalLearner.
Инкрементно подходящий Mdl к данным при помощи fit.
Симулируйте поток данных и выполните следующие действия с каждым входящим фрагментом 50 наблюдений.
Вызовите updateMetrics измерять совокупный уровень и эффективность в окне наблюдений. Перезапишите предыдущую инкрементную модель с новой, чтобы отследить показатели производительности.
Вызовите loss измерять производительность модели на входящем фрагменте.
Вызовите fit подбирать модель к входящему фрагменту. Перезапишите предыдущую инкрементную модель с новой, адаптированной к входящему наблюдению.
Сохраните все показатели производительности, чтобы контролировать их эволюцию во время пошагового обучения.
% Preallocation numObsPerChunk = 50; nchunk = floor(n/numObsPerChunk); ce = array2table(zeros(nchunk,3),'VariableNames',["Cumulative" "Window" "Loss"]); % Incremental learning for j = 1:nchunk ibegin = min(n,numObsPerChunk*(j-1) + 1); iend = min(n,numObsPerChunk*j); idx = ibegin:iend; Mdl = updateMetrics(Mdl,X(idx,:),Y(idx)); ce{j,["Cumulative" "Window"]} = Mdl.Metrics{"ClassificationError",:}; ce{j,"Loss"} = loss(Mdl,X(idx,:),Y(idx)); Mdl = fit(Mdl,X(idx,:),Y(idx)); end
Mdl incrementalClassificationLinear объект модели, который испытал все данные в потоке. Во время пошагового обучения и после того, как модель подогревается, updateMetrics проверяет эффективность модели на входящем наблюдении, затем подбирает модель к тому наблюдению. loss агностик метрического периода прогрева, таким образом, он измеряет ошибку классификации для всех итераций.
Чтобы видеть, как показатели производительности, развитые во время обучения, постройте их на отдельных подграфиках.
figure; h = plot(ce.Variables); xlim([0 nchunk]); ylim([0 0.05]) ylabel('Classification Error') xline(Mdl.MetricsWarmupPeriod/numObsPerChunk,'r-.'); legend(h,ce.Properties.VariableNames) xlabel('Iteration')

В метрический период прогрева (перед красной линией), желтая линия представляет ошибку классификации на каждом входящем фрагменте данных. После метрического периода прогрева, Mdl отслеживает совокупный и метрики окна. Совокупные и пакетные потери сходятся как fit подбирает инкрементную модель к входящим данным.
Подбирайте модель пошагового обучения для регрессии к потоковой передаче данных и вычислите среднее абсолютное отклонение (MAD) на входящих данных о пакетах.
Загрузите набор данных манипулятора.
load robotarm
n = numel(ytrain);
p = size(Xtrain,2);Для получения дополнительной информации на наборе данных, отобразите Description.
Создайте инкрементную линейную модель для регрессии. Сконфигурируйте модель можно следующим образом:
Задайте метрический период прогрева 1 000 наблюдений.
Задайте метрический размер окна 500 наблюдений.
Отследите среднее абсолютное отклонение (MAD), чтобы измерить уровень модели. Создайте анонимную функцию, которая измеряет абсолютную погрешность каждого нового наблюдения. Создайте массив структур, содержащий имя MeanAbsoluteError и его соответствующая функция.
Главный модель, чтобы предсказать ответы путем указывания, что все коэффициенты регрессии и смещение 0.
maefcn = @(z,zfit,w)(abs(z - zfit)); maemetric = struct("MeanAbsoluteError",maefcn); Mdl = incrementalRegressionLinear('MetricsWarmupPeriod',1000,'MetricsWindowSize',500,... 'Metrics',maemetric,'Beta',zeros(p,1),'Bias',0,'EstimationPeriod',0)
Mdl =
incrementalRegressionLinear
IsWarm: 0
Metrics: [2×2 table]
ResponseTransform: 'none'
Beta: [32×1 double]
Bias: 0
Learner: 'svm'
Properties, Methods
Mdl incrementalRegressionLinear объект модели сконфигурирован для пошагового обучения.
Симулируйте поток данных и выполните пошаговое обучение. В каждой итерации:
Обработайте фрагмент 50 наблюдений.
Вызовите updateMetrics вычислить совокупный и метрики окна на входящем фрагменте данных. Перезапишите предыдущую инкрементную модель с новой, адаптированной, чтобы перезаписать предыдущие метрики.
Вызовите loss вычислить MAD на входящем фрагменте данных. Принимая во внимание, что совокупные метрики и метрики окна требуют, чтобы пользовательские потери возвратили потерю для каждого наблюдения, loss требует потери на целом фрагменте. Вычислите среднее значение абсолютного отклонения.
Вызовите fit подбирать инкрементную модель к входящему фрагменту данных.
Сохраните совокупное, окно, и разделите метрики на блоки, чтобы контролировать их эволюцию во время пошагового обучения.
% Preallocation numObsPerChunk = 50; nchunk = floor(n/numObsPerChunk); mae = array2table(zeros(nchunk,3),'VariableNames',["Cumulative" "Window" "Chunk"]); % Incremental fitting for j = 1:nchunk ibegin = min(n,numObsPerChunk*(j-1) + 1); iend = min(n,numObsPerChunk*j); idx = ibegin:iend; Mdl = updateMetrics(Mdl,Xtrain(idx,:),ytrain(idx)); mae{j,1:2} = Mdl.Metrics{"MeanAbsoluteError",:}; mae{j,3} = loss(Mdl,Xtrain(idx,:),ytrain(idx),'LossFun',@(x,y,w)mean(maefcn(x,y,w))); Mdl = fit(Mdl,Xtrain(idx,:),ytrain(idx)); end
IncrementalMdl incrementalRegressionLinear объект модели, который испытал все данные в потоке. Во время пошагового обучения и после того, как модель подогревается, updateMetricsAndFit проверяет эффективность модели на входящем наблюдении, затем подбирает модель к тому наблюдению.
Постройте показатели производительности, чтобы видеть, как они развились во время пошагового обучения.
figure; h = plot(mae.Variables); ylabel('Mean Absolute Deviation') xline(Mdl.MetricsWarmupPeriod/numObsPerChunk,'r-.'); xlabel('Iteration') legend(h,mae.Properties.VariableNames)

График предполагает что:
updateMetrics вычисляет показатели производительности только после метрического периода прогрева
updateMetrics Вычисляет совокупные метрики во время каждой итерации
updateMetrics вычисляет метрики окна после обработки 500 наблюдений
Поскольку Mdl было запущено, чтобы предсказать наблюдения с начала пошагового обучения, loss может вычислить MAD на каждом входящем фрагменте данных.
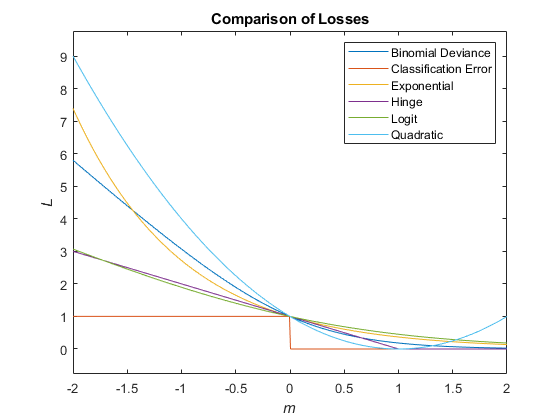
Функции Classification loss измеряют прогнозирующую погрешность моделей классификации. Когда вы сравниваете тот же тип потери среди многих моделей, более низкая потеря указывает на лучшую прогнозную модель.
Рассмотрите следующий сценарий.
L является средневзвешенной потерей классификации.
n является объемом выборки.
Для бинарной классификации:
yj является наблюдаемой меткой класса. Программные коды это как –1 или 1, указывая на отрицательный или положительный класс, соответственно.
f (Xj) является необработанной классификационной оценкой для наблюдения (строка) j данных о предикторе X.
mj = yj f (Xj) является классификационной оценкой для классификации наблюдения j в класс, соответствующий yj. Положительные значения mj указывают на правильную классификацию и не способствуют очень средней потере. Отрицательные величины mj указывают на неправильную классификацию и значительно способствуют средней потере.
Весом для наблюдения j является wj.
Учитывая этот сценарий, следующая таблица описывает поддерживаемые функции потерь, которые можно задать при помощи 'LossFun' аргумент пары "имя-значение".
| Функция потерь | Значение LossFun | Уравнение |
|---|---|---|
| Биномиальное отклонение | "binodeviance" | |
| Экспоненциальная потеря | "exponential" | |
| Ошибка классификации | "classiferror" | Это - взвешенная часть неправильно классифицированных наблюдений где метка класса, соответствующая классу с максимальной апостериорной вероятностью. I {x} является функцией индикатора. |
| Потеря стержня | "hinge" | |
| Потеря логита | "logit" | |
| Квадратичная потеря | "quadratic" |
Этот рисунок сравнивает функции потерь для одного наблюдения по m. Некоторые функции нормированы, чтобы пройти [0,1].