

Класс: RegressionGP
Перекрестный подтвердите Гауссову модель регрессии процесса
cvMdl = crossval(gprMdl)
cvmdl = crossval(gprMdl,Name,Value)
cvMdl = crossval(gprMdl)cvMdl, созданный из модели Gaussian process regression (GPR), gprMdl, использование 10-кратной перекрестной проверки.
cvmdl RegressionPartitionedModel объект и gprMdl RegressionGP (полный) объект.
cvmdl = crossval(gprMdl,Name,Value)cvmdl, с дополнительными опциями, заданными одним или несколькими Name,Value парные аргументы. Например, можно задать количество сгибов или часть данных, чтобы использовать для тестирования.
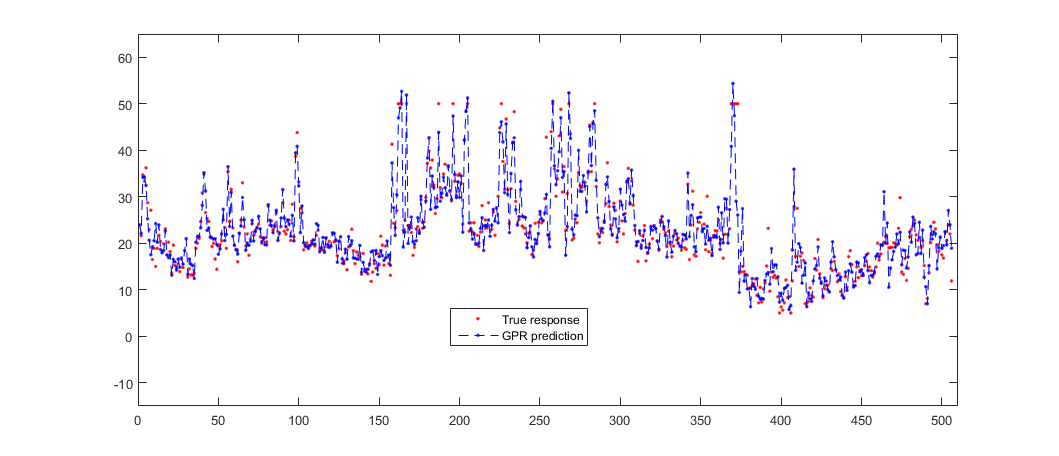
Загрузите данные о корпусе [1] от Репозитория Машинного обучения UCI [4].
Набор данных имеет 506 наблюдений. Первые 13 столбцов содержат значения предиктора, и последний столбец содержит значения отклика. Цель состоит в том, чтобы предсказать среднее значение занятых владельцами домов в пригородном Бостоне как функция 13 предикторов.
Загрузите данные и задайте вектор отклика и матрицу предиктора.
load('housing.data');
X = housing(:,1:13);
y = housing(:,end);
Подбирайте модель GPR с помощью экспоненциальной функции ядра в квадрате с отдельной шкалой расстояний для каждого предиктора. Стандартизируйте переменные предикторы.
gprMdl = fitrgp(X,y,'KernelFunction','ardsquaredexponential','Standardize',1);
Создайте раздел перекрестной проверки для данных с помощью предиктора 4 как сгруппированная переменная.
rng('default') % For reproducibility cvp = cvpartition(X(:,4),'kfold',10);
Создайте 10-кратную перекрестную подтвержденную модель с помощью разделенных данных в cvp.
cvgprMdl = crossval(gprMdl,'CVPartition',cvp);
Вычислите потерю регрессии для, окутывают модели использования наблюдений, обученные на наблюдениях из сгиба.
L = kfoldLoss(cvgprMdl)
L =
9.5299Предскажите, что ответ для окутывает наблюдения, i.e. наблюдения, не используемые для обучения.
ypred = kfoldPredict(cvgprMdl);
Для каждого сгиба, kfoldPredict предсказывает ответы для наблюдений в том сгибе с помощью моделей, обученных на наблюдениях из сгиба.
Постройте фактические ответы и данные о предсказании.
plot(y,'r.'); hold on; plot(ypred,'b--.'); axis([0 510 -15 65]); legend('True response','GPR prediction','Location','Best'); hold off;
Загрузите данные о морском ушке [2], [3], от Репозитория Машинного обучения UCI [4] и сохраните его в вашем текущем каталоге с именем abalone.data.
Считайте данные в table.
tbl = readtable('abalone.data','Filetype','text','ReadVariableNames',false);
Набор данных имеет 4 177 наблюдений. Цель состоит в том, чтобы предсказать возраст морского ушка от 8 физических измерений.
Подбирайте модель GPR с помощью подмножества регрессоров (sr) метод для оценки параметра и полностью независимого условного выражения (fic) метод для предсказания. Стандартизируйте предикторы и используйте экспоненциальную функцию ядра в квадрате с отдельной шкалой расстояний для каждого предиктора.
gprMdl = fitrgp(tbl,tbl(:,end),'KernelFunction','ardsquaredexponential',... 'FitMethod','sr','PredictMethod','fic','Standardize',1);
Перекрестный подтвердите модель с помощью 4-кратной перекрестной проверки. Это делит данные в 4 набора. Для каждого набора, fitrgp использование, которое устанавливает (25% данных) как тестовые данные и обучает модель на остающихся 3 наборах (75% данных).
rng('default') % For reproducibility cvgprMdl = crossval(gprMdl,'KFold',4);
Вычислите потерю по отдельным сгибам.
L = kfoldLoss(cvgprMdl,'mode','individual')
L =
4.3669
4.6896
4.0565
4.3162Вычислите среднее значение перекрестная подтвержденная потеря на по всем сгибам. Значением по умолчанию является среднеквадратическая ошибка.
L2 = kfoldLoss(cvgprMdl)
L2 =
4.3573
Это равно средней потере по отдельным сгибам.
mse = mean(L)
mse =
4.3573
Можно только использовать один из аргументов пары "имя-значение" за один раз.
Вы не можете вычислить интервалы предсказания для перекрестной подтвержденной модели.
В качестве альтернативы можно обучить перекрестную подтвержденную модель с помощью связанных аргументов пары "имя-значение" в fitrgp.
Если вы предоставляете пользовательский 'ActiveSet' в вызове fitrgp, затем вы не можете пересечься, подтверждают модель GPR.
[1] Харрисон, D. и D.L., Рубинфельд. "Гедонистические цены и спрос на чистый воздух". J. Окружить. Экономика & управление. Vol.5, 1978, стр 81-102.
[2] Уорик J. N. Т. Л. Селлерс, С. Р. Тэлбот, А. Дж. Которн и В. Б. Форд. "Биология Населения Морского ушка (_Haliotis_ разновидности) на Тасмании. I. Морское ушко Blacklip (_H. rubra _) от Северного Побережья и Островов Пролива Басса". Морское Деление Рыболовства, Технический отчет № 48 (ISSN 1034-3288), 1994.
[3] С. Во. "Расширяя и тестируя Каскадной Корреляции в сравнении с эталоном", диссертация. Кафедра информатики, университет Тасмании, 1995.
[4] Личмен, M. Репозиторий Машинного обучения UCI, Ирвин, CA: Калифорнийский университет, Школа Информатики и вычислительной техники, 2013. http://archive.ics.uci.edu/ml.
fitrgp | kfoldLoss | kfoldPredict | RegressionGP | RegressionPartitionedModel