Обучение с подкреплением является направленным на достижение цели вычислительным подходом, где компьютер учится выполнять задачу путем взаимодействия с неизвестной динамической средой. Этот подход изучения позволяет компьютеру сделать ряд решений максимизировать совокупное вознаграждение за задачу без человеческого вмешательства и не будучи явным образом запрограммированным, чтобы достигнуть задачи. Следующая схема показывает общее представление сценария обучения с подкреплением.
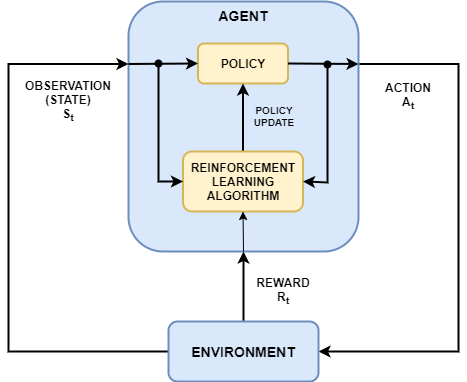
Цель обучения с подкреплением состоит в том, чтобы обучить политику агента выполнить задачу в неизвестной среде. Агент получает наблюдения и вознаграждение от окружения и посылает туда действия. Вознаграждение является мерой того, насколько успешно действие относительно выполнения цели задачи.
Чтобы создать и обучить агентов обучения с подкреплением, можно использовать пакет Reinforcement Learning Toolbox™. Как правило, политики агента представлены с помощью глубоких нейронных сетей, которые можно создать программное обеспечение Deep Learning Toolbox™ использования.
Обучение с подкреплением полезно для многих, управляют и приложения планирования. Следующие примеры показывают, как обучить агентов обучения с подкреплением робототехнике и автоматизировали ведущие задачи.
Общий процесс настройки агента, используя обучение с подкреплением, включает следующие шаги.
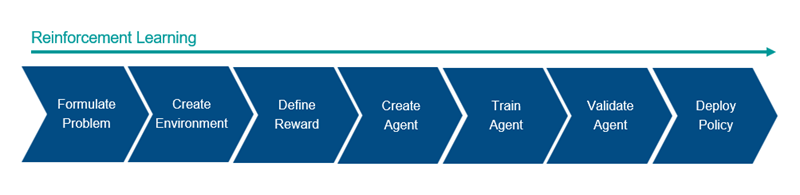
Сформулируйте проблему — Описывают задачу для обучения агента, включая то, как агент взаимодействует со средой и любыми первичными и вторичными целями, которых должен достигнуть агент.
Создайте среду — Задают среду, в которой агент действует, включая интерфейс между агентом и средой и динамической моделью среды.
Задайте вознаграждение — Определяют сигнал вознаграждения, который использует для измерения своей успешности выполнения целей задачи агент и как вычислить этот сигнал средой.
Создайте агента — Создают агента, который включает определение представления политики и конфигурирование алгоритма обучения агента.
Обучайтесь агент — Настраивают представление политики агента с помощью заданной среды, вознаграждения и алгоритма обучения агента.
Подтвердите агента — Вычисляют производительность обученного агента путем симуляции агента и среды вместе.
Развернитесь политика — Развертывают обученное использование представления политики, например, сгенерированный код графического процессора.
Настройка агента с помощью обучения с подкреплением является итеративным процессом. Решения и результаты на более поздних этапах могут потребовать, чтобы вы возвратились к более ранней стадии в рабочем процессе обучения. Например, если учебный процесс не сходится к оптимальной политике в разумном количестве времени, вам придется обновить любое из следующих прежде, чем переобучить агента:
Настройки обучения
Конфигурацию алгоритма обучения
Представление политики
Определение сигнала вознаграждения
Сигналы действия и наблюдения
Динамику среды
В сценарии обучения с подкреплением, где вы обучаете агента выполнять задачу, среда моделирует динамику, с которой взаимодействует агент. Среда:
Получает действия от агента.
Формирует выходные наблюдения в ответ на действия.
Генерирует вознаграждение, измеряющее, насколько хорошо действие способствует достижению задачи.
Создание модели среды включает определение следующего:
Сигналы действия и наблюдения, которые агент использует для взаимодействия со средой.
Сигнал вознаграждения, который использует для измерения измерения своего успеха агент. Для получения дополнительной информации смотрите, Задают Сигналы вознаграждения (Reinforcement Learning Toolbox).
Динамическое поведение среды.
Можно создать среду или в MATLAB® или в Simulink®. Для получения дополнительной информации смотрите, Создают Среды Обучения с подкреплением MATLAB (Reinforcement Learning Toolbox) и Создают Среды Обучения с подкреплением Simulink (Reinforcement Learning Toolbox).
Агент обучения с подкреплением содержит два компонента: политика и алгоритм обучения.
Политика является отображением, которое выбирает действия на основе наблюдений средой. Как правило, политика представляет собой аппроксимирующую функцию с настраиваемыми параметрами, например, глубокую нейронную сеть.
Алгоритм обучения постоянно обновляет параметры политики на основе действия, наблюдений и вознаграждения. Цель алгоритма обучения состоит в том, чтобы найти оптимальную политику, которая максимизирует совокупное вознаграждение, полученное во время задачи.
Агентов отличают их алгоритмы обучения и представления политики. Агенты могут действовать в дискретных пространствах действий, непрерывных пространствах действий или обоих. В дискретном пространстве действий агент выбирает действия из конечного множества возможных действий. В непрерывном пространстве действий агент выбирает действие из непрерывной области значений возможных значений действия. Программное обеспечение Reinforcement Learning Toolbox поддерживает следующие типы агентов.
| Агент | Пространство действий |
|---|---|
| Агенты Q-обучения (Reinforcement Learning Toolbox) | Дискретный |
| Глубокие агенты Q-сети (Reinforcement Learning Toolbox) | Дискретный |
| Агенты SARSA (Reinforcement Learning Toolbox) | Дискретный |
| Агенты градиента политики (Reinforcement Learning Toolbox) | Дискретный или непрерывный |
| Агенты критика агента (Reinforcement Learning Toolbox) | Дискретный или непрерывный |
| Ближайшие агенты оптимизации политики (Reinforcement Learning Toolbox) | Дискретный или непрерывный |
| Глубоко детерминированные агенты градиента политики (Reinforcement Learning Toolbox) | Непрерывный |
| Задержанный близнецами глубоко детерминированные агенты градиента политики (Reinforcement Learning Toolbox) | Непрерывный |
| Мягкие агенты критика агента (Reinforcement Learning Toolbox) | Непрерывный |
Для получения дополнительной информации смотрите Агентов Обучения с подкреплением (Reinforcement Learning Toolbox).
В зависимости от типа агента вы используете, его политика и алгоритм обучения требуют одного или нескольких политика и представления функции ценности, которые можно реализовать глубокие нейронные сети использования.
Reinforcement Learning Toolbox поддерживает следующие типы представлений политики и функции ценности.
V (S |θV) — Критики, которые оценивают ожидаемое совокупное долгосрочное вознаграждение (функция ценности) на основе заданного наблюдения S.
Q (S, A |θQ) — Критики, которые оценивают функцию ценности для данного дискретного действия A и заданное наблюдение S.
Qi (S, Ai |θQ) — Мультивыходные критики, которые оценивают функцию ценности для всех возможных дискретных действий Ai и заданное наблюдение S.
μ (S |θμ) — Агенты, которые выбирают действие на основе заданного наблюдения S. Агенты могут выбрать действия с помощью или детерминированных или стохастических методов.
Во время обучения агент обновляет параметры этих представлений (θV, θQ и θμ).
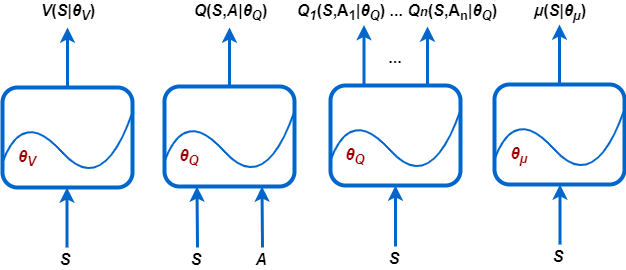
Можно создать большинство агентов Reinforcement Learning Toolbox с политикой по умолчанию и представлениями функции ценности. Агенты задают входные и выходные слои этих глубоких нейронных сетей на основе действия и спецификаций наблюдений средой.
В качестве альтернативы можно создать представления актёра и критика для агента с помощью функциональности Deep Learning Toolbox, такие как приложение Deep Network Designer. В этом случае гарантируйте, что размерности ввода и вывода представлений актёра и критика совпадают с соответствующим действием и спецификациями наблюдений среды. Для примера, который создает представление критика с помощью Deep Network Designer, смотрите, Создают Агента Используя Deep Network Designer и Обучаются Используя Наблюдения Изображений.
Глубокие нейронные сети состоят из серии взаимосвязанных слоев. Для полного списка доступных слоев смотрите Список слоев глубокого обучения.
Все агенты, кроме агентов Q-обучения и SARSA, поддерживают рекуррентные нейронные сети (RNNs). Эти сети имеют вход sequenceInputLayer и по крайней мере один слой, который скрыл информацию состояния, такой как lstmLayer. Эти сети могут быть особенно полезными, когда среда имеет состояния, которые не находятся в векторе наблюдения.
Для получения дополнительной информации о создании агентов и их функции присваиваемого значения и представлений политики, смотрите соответствующие страницы агента в предыдущей таблице.
Программное обеспечение Reinforcement Learning Toolbox обеспечивает дополнительные слои, которые можно использовать при создании представлений глубокой нейронной сети.
| Слой | Описание |
|---|---|
scalingLayer (Reinforcement Learning Toolbox) | Применяет линейную шкалу и смещение к входному массиву. Этот слой полезен для масштабирования и перемещения выходных параметров нелинейных слоев, такой как tanhLayer и sigmoidLayer. |
quadraticLayer (Reinforcement Learning Toolbox) | Создает вектор из квадратичных одночленов, созданных из элементов входного массива. Этот слой полезен, когда вам нужен выход, который является некоторой квадратичной функцией его входных параметров, такой что касается контроллера LQR. |
softplusLayer (Reinforcement Learning Toolbox) | Реализует softplus активацию Y = журнал (1 + eX), который гарантирует, что выход всегда положителен. Это - сглаживавшая версия исправленного линейного модуля (ReLU). |
Для получения дополнительной информации о создании политики и представлений функции ценности, смотрите, Создают политику и Представления Функции ценности (Reinforcement Learning Toolbox).
Можно также импортировать предварительно обученные глубокие нейронные сети или архитектуры слоя глубокой нейронной сети с помощью функциональности импорта сети Deep Learning Toolbox. Для получения дополнительной информации смотрите политику Импорта и Представления Функции ценности (Reinforcement Learning Toolbox).
Если вы создаете среду и агента обучения с подкреплением, можно обучить агента в среде с помощью train (Reinforcement Learning Toolbox) функция. Чтобы сконфигурировать ваше обучение, используйте rlTrainingOptions Объект (Reinforcement Learning Toolbox). Для получения дополнительной информации смотрите, Обучают Агентов Обучения с подкреплением (Reinforcement Learning Toolbox)
Если у вас есть программное обеспечение Parallel Computing Toolbox™, можно ускорить обучение и симуляцию при помощи многоядерных процессоров или графических процессоров. Для получения дополнительной информации смотрите, Обучают Агентов Используя Параллельные вычисления и графические процессоры (Reinforcement Learning Toolbox).
Если вы обучаете агента обучения с подкреплением, можно сгенерировать код, чтобы развернуть оптимальную политику. Можно сгенерировать:
Код CUDA® с помощью GPU Coder™
Код C/C++ с помощью MATLAB Coder™
Чтобы создать функцию оценки политики, которая выбирает действие на основе заданного наблюдения, используйте generatePolicyFunction (Reinforcement Learning Toolbox) команда. Эта команда генерирует скрипт MATLAB, который содержит функцию оценки политики и MAT-файл, который содержит оптимальные данные о политике.
Можно сгенерировать код, чтобы развернуть эту функцию политики использование GPU Coder или MATLAB Coder.
Для получения дополнительной информации смотрите, Развертывают Обученные политики Обучения с подкреплением (Reinforcement Learning Toolbox).
