Для проектов, которые требуют больших наборов данных доступа от внешней памяти, смоделируйте свой алгоритм с упрощенным Основным протоколом AXI4. Когда вы запускаете IP Core Generation рабочий процесс, HDL Coder™ генерирует ядро IP с Основными интерфейсами AXI4. Интерфейс AXI4 Master может передать между вашим проектом и контроллером внешней памяти IP при помощи Основного протокола AXI4. Используйте интерфейс AXI4 Master когда ваш:
Спроектируйте целевые приложения обработки видеоданных сверхкадра. Можно сохранить данные изображения во внешней памяти, такой как память DDR3 на борту, и затем считать или записать изображения в проект пакетным способом для высокоскоростной обработки.
Алгоритм должен получить доступ к данным оперативной памяти в не передающем потоком произвольном шаблоне.
Ядро IP DUT должно управлять другим дюйм/с с ведомым интерфейсом AXI4 в системе. Эта возможность особенно полезна в автономных устройствах FPGA.
Чтобы сопоставить порты DUT с Основными интерфейсами AXI4, используйте упрощенный Основной протокол AXI4. Вы не должны моделировать фактический Основной протокол AXI4, и вместо этого можно использовать упрощенный протокол. Когда вы запускаете IP Core Generation рабочий процесс, сгенерированный HDL-код содержит логику обертки, которая переводит между упрощенным протоколом и фактическим Основным протоколом AXI4. Упрощенный протокол требует, чтобы вы использовали меньше сигналов протокола, упрощает механизм квитирования между допустимыми и готовыми сигналами и поддерживает пакеты произвольных длин.
Используйте упрощенный Основной протокол записи AXI4 для транзакции записи и упрощенный Основной протокол чтения AXI4 для транзакции чтения. Этот рисунок показывает схему синхронизации для сигналов, что вы моделируете в интерфейсах ввода и вывода DUT для Основной транзакции записи AXI4.

DUT ожидает wr_ready стать высоким, чтобы инициировать запрос записи. Когда wr_ready становится высоким, DUT может отослать запрос записи. Запрос записи состоит из Data и Write Master to Slave bus сигналы. Эта шина состоит из wr_len, wr_addr, и wr_valid. wr_addr задает начальный адрес, в который DUT хочет записать. wr_len сигнал соответствует количеству элементов данных в этой транзакции записи. Data может отправляться настолько же долго как wr_valid высоко. Когда wr_ready становится низким, DUT должен прекратить отправлять данные в одном такте и Data сигнал становится недопустимым. Если DUT продолжает отправлять данные после того, как один такт, данные будут проигнорированы.
Выходные сигналы
Смоделируйте Data и Write Master to Slave bus сигналы в DUT интерфейс выхода.
Data: Данные, которые вы хотите передать, допустимый каждый цикл транзакции.
Write Master to Slave bus это состоит из:
wr_addr: Начальный адрес транзакции записи, которая производится в первом цикле транзакции. Адрес задан в байтах.
wr_len: Количество значений данных, которые вы хотите передать, произведенный в первом цикле транзакции. wr_len сигнал задан в словах. Это означает каждый модуль wr_len элемент полных данных. Например, когда wr_len 2, и битной шириной данных является 128 бит, два 128- битные элементы данных записаны.
wr_valid: Когда этот управляющий сигнал становится высоким, он указывает что Data сигнал, произведенный при выходе, допустим.
Входные сигналы
Смоделируйте Write Slave to Master bus это состоит из:
wr_complete (дополнительный сигнал): Управляющий сигнал, который, когда остается высоким для одного такта, указывает, что транзакция записи завершилась. Следующий пакет данных может быть отправлен после wr_complete утверждает. Раннее утверждение wr_complete делает среднюю задержку почти 3 такты между двумя пакетами, который делает операцию записи конвейерной и улучшает пропускную способность записи.
wr_ready: Этот сигнал соответствует противодавлению от ведомого IP оперативная или внешняя память. Когда этот управляющий сигнал идет высоко, он указывает, что данные могут быть отправлены. Когда wr_ready является низким, DUT должен прекратить отправлять данные в одном такте. Можно также использовать wr_ready сигнал определить, может ли DUT сразу отправить второй пакетный сигнал после первого пакетного сигнала, был отправлен. Несколько пакетных сигналов поддерживаются, что означает что wr_ready сигнал остается высоким, чтобы сразу принять второй пакет после того, как последний элемент первого пакета был принят. Используя wr_ready определить, когда запустить следующий пакет, может уменьшать среднюю задержку между двумя пакетами к меньше, чем 3 такты.
wr_bvalid (дополнительный сигнал): сигнал Ответа от ведомого ядра IP, что можно использовать для целей диагноза. wr_bvalid сигнал становится высоким после того, как межсоединение AXI4 примет каждую пакетную транзакцию. Если wr_len больше 256, Основной модуль записи AXI4 разделяет большой пакетный сигнал в пакеты 256 размеров. wr_bvalid становится высоким для каждого пакета 256 размеров.
wr_bresp (дополнительный сигнал): сигнал Ответа от ведомого ядра IP, что можно использовать для целей диагноза. Используйте этот сигнал с wr_bvalid сигнал.
Основной протокол AXI4 поддерживает максимальный пакетный размер 256. Когда у вас есть большой пакет размера, больше, чем 256, интерфейс AXI Master в сгенерированном ядре IP HDL делится, большие врываются в несколько меньших пакетов с размером 256. Поэтому даже для больших пакетов данных, вы видите улучшенную пропускную способность записи.
Этот рисунок показывает схему синхронизации для сигналов, что вы моделируете в интерфейсах ввода и вывода DUT для Основной транзакции чтения AXI4. Эти сигналы включают Data, Read Master to Slave Bus, и Read Slave to Master Bus.
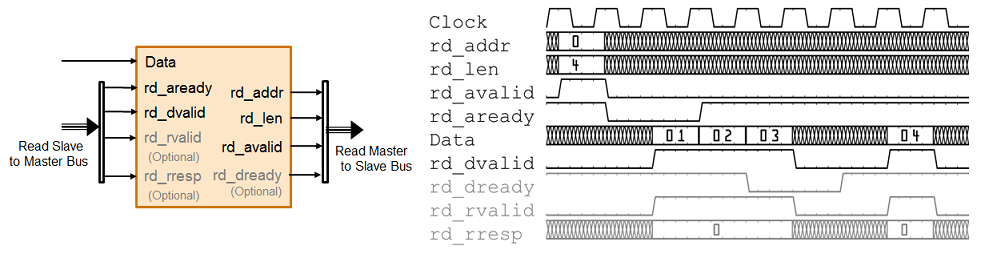
DUT ожидает rd_aready стать высоким, чтобы инициировать запрос чтения. Когда rd_aready высоко, DUT может отослать запрос чтения. Запрос чтения состоит из rd_addr, rd_len, и rd_avalid сигналы Read Master to Slave bus. Ведомый IP или внешняя память отвечают на запрос чтения путем отправки Data в каждом такте. rd_len сигнал соответствует количеству значений данных, чтобы читать. DUT может получить Data настолько же долго как rd_dvalid высоко.
Считайте запрос
Чтобы смоделировать запрос чтения, в DUT интерфейс выхода, моделируют Read Master to Slave bus это состоит из:
rd_addr: Начальный адрес для транзакции чтения, которая производится в первом цикле транзакции. Адрес задан в байтах.
rd_len: Количество значений данных, которые вы хотите считать, произведенный в первом цикле транзакции. rd_len сигнал задан в словах. Это означает каждый модуль rd_len элемент полных данных. Например, когда rd_len 2, и битной шириной данных является 128 бит, два 128- читаются битные элементы данных.
rd_avalid: Управляющий сигнал, который задает, допустим ли запрос чтения.
В интерфейсе входа DUT реализуйте rd_aready сигнал. Этот сигнал является частью Read Slave to Master bus и указывает, когда принять запросы чтения. Можно контролировать rd_aready сигнал определить, может ли DUT отправить последовательные пакетные запросы. Когда rd_aready становится высоким, это указывает, что DUT может отправить запрос чтения за следующий такт.
Считайте ответ
В интерфейсе входа DUT смоделируйте Data и Read Slave to Master bus сигналы.
Data: Данные, которые возвращены в запрос чтения.
Read Slave to Master bus это состоит из:
rd_dvalid: Управляющий сигнал, который указывает что Data возвращенный в запрос чтения допустимо.
rd_rvalid (дополнительный сигнал): сигнал ответа от ведомого ядра IP, что можно использовать для целей диагноза.
rd_rresp (дополнительный сигнал): сигнал Ответа от ведомого ядра IP, которое указывает на состояние транзакции чтения.
В DUT интерфейс выхода можно опционально реализовать rd_dready сигнал. Этот сигнал является частью Read Master to Slave bus и указывает, когда DUT может начать принимать данные. По умолчанию, если вы не сопоставляете этот сигнал с Ведущим интерфейсом чтения AXI4, сгенерированное ядро IP HDL связывает rd_dready к логике высоко.
Для ядер IP, которые вы генерируете, HDL Coder включает индексный регистр, чтобы поддержать авторскую разработку драйвера для обоих Основное чтение AXI4 и каналы записи. Индексный регистр добавляется к адресу, который задан DUT ADDR порт, чтобы сформировать Основной адрес AXI4. Эта возможность позволяет драйверу использовать способ адресации, который программирует адрес фиксированного регистра с базовым адресом буфера. Запрограммированный адрес вместе с DUT ADDR порт используется, чтобы индексировать буфер. По умолчанию регистры принимают значение нуля, если вы не используете их.
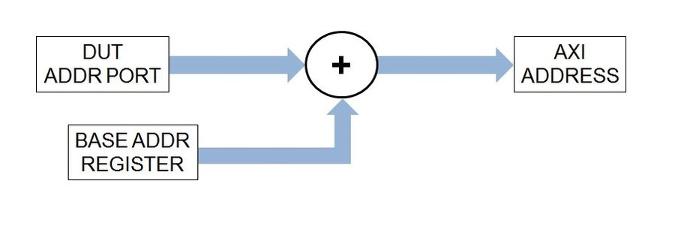
Когда вы запускаете IP Core Generation рабочий процесс или Simulink Real-Time FPGA I/O рабочий процесс, можно задать начальное значение для чтения основных данных AXI4 и записать индексные регистры. По умолчанию начальное значение является нулем. Задавать ненулевое значение:
В таблице интерфейса целевой платформы, когда вы сопоставляете порт входа DUT с портом данных Ведущего устройства AXI4 Рида или порт выхода DUT Ведущему устройству AXI4, Записывают данные интерфейс порта, кнопка Options появляется в столбце Interface Options.
Нажмите кнопку Options, и затем задайте DefaultReadBaseAddress или DefaultWriteBaseAddress.
Можно смоделировать алгоритм с Данными и Основными сигналами протокола AXI4 в портах DUT и затем сопоставить сигналы с Основными интерфейсами AXI4.

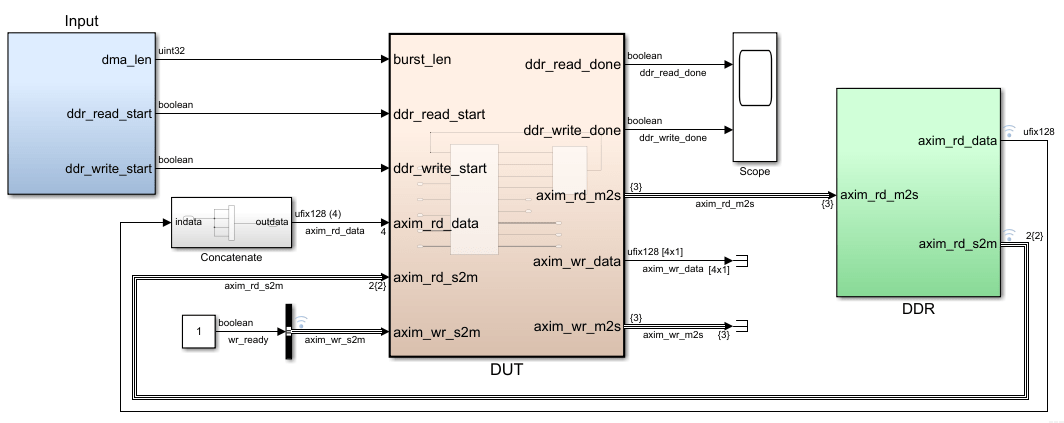
Чтобы изучить, как смоделировать ваш алгоритм DUT для отображения интерфейса AXI4 Master, откройте эту модель Simulink®. Подсистема DUT содержит простой алгоритм, который считывает данные из DDR и записывает данные обратно к различному адресу в памяти DDR.

Дважды кликните Подсистему DUT. Модели DDR_Access_Controller Subsystem Основные каналы чтения и записи AXI и имеют Простой Двухпортовый RAM, который вычисляет сигнал wr_data. Если вы дважды кликаете Подсистему DDR_Access_Controller, вы видите два блока Subsystem Обнаружения Ребра, которые генерируют эти два, запускают импульсы как вход к каждому блоку MATLAB function. Модели Edge Detection Subsystem и DDR Read Controller MATLAB Function транзакция чтения. Другие модели Edge Detection Subsystem и DDR Write Controller MATLAB Function транзакция записи. Можно изменить этот проект, чтобы смоделировать только транзакцию записи или транзакцию чтения при помощи одной Подсистемы Обнаружения Ребра и соответствующего блока MATLAB function.
Считайте канал
Контроллер Чтения DDR моделируется как конечный автомат с четырьмя состояниями: INIT, НЕАКТИВНЫЙ, READ_BURST_START и DATA_COUNT. Состояние INIT инициализирует сигналы чтения и входные сигналы RAM. Когда сигнал запуска идет высоко, конечный автомат переключается на Состояние ожидания, и затем ожидает rd_aready предупредите, чтобы стать высокими. Когда rd_aready становится высоким, переходы конечного автомата к состоянию READ_BURST_START и DUT начинает считывать данные. Конечный автомат затем безусловно переключается на DATA_COUNT, утверждают, и продолжает считывать данные до rd_avalid идет низко.
Запишите канал
Контроллер Записи DDR моделируется похожий на канал Рида как конечный автомат с четырьмя состояниями: НЕАКТИВНЫЙ, WRITE_BURST_START, DATA_COUNT и ACK_WAIT. DUT находится в Состоянии ожидания и затем переключается на состояние WRITE_BURST_START, где это ожидает wr_ready сигнал. Когда wr_ready становится высоким, конечный автомат переключается на DATA_COUNT, утверждают, и начинает записывать данные. Данные допустимы когда wr_valid высоко. DUT продолжает записывать данные когда wr_ready высоко. Как wr_ready становится низким, конечный автомат переключается на ACK_WAIT, утверждают, и затем ожидает готового сигнала инициировать следующую транзакцию записи.
Чтобы видеть упрощенный Основной протокол AXI4 в действительности, симулируйте модель. Если вам установили DSP System Toolbox™, можно просмотреть и анализировать результаты в Logic Analyzer.

Можно использовать рабочий процесс Генерации Ядра IP, чтобы сгенерировать ядро IP HDL с интерфейсом AXI4 Master. Если вам установили HDL Verifier™, и вы используете плату Xilinx Zynq ZC706, то можно интегрировать ядро IP в Систему По умолчанию с Внешним исходным проектом доступа к памяти DDR3.
Чтобы интегрировать ваше ядро IP HDL в большие исходные проекты и достигнуть более высокой пропускной способности, когда вы используете Ведущий порт AXI4, чтобы получить доступ к внешней памяти DDR, можно хотеть использовать большие битные ширины на Data порт. Шина интерфейса AXI4 Master поддерживает максимальную битную ширину 1024 биты.
Simulink® поддерживает типы данных с фиксированной точкой, которые имеют размер слова до 128 биты. Смоделировать ваши порты DUT с размерами слова, больше, чем 128 биты, используйте векторные типы данных. Если вы используете векторный порт, таким образом, что объединенная битная ширина всех элементов в векторе больше 1024 биты, задача Set Target Interface отображает ошибку.
Например, в hdlcoder_axi_master модель, чтобы расширить битную ширину axim_rd_data порт к 512 биты, измените ddr_data параметр в DDR к fi(([40:-1:1]),0,128,0) и затем конкатенируйте 128-битный вход четыре раза, чтобы сгенерировать выход 512 битов. Можно использовать блок Vector Concatenate, чтобы вывести объединенную битную ширину 512 битов. Чтобы симулировать модель, замените блок Simple Dual Port RAM в подсистеме DUT с Simple Dual port RAM System.
Можно затем сопоставить эти Порты данных DUT с AXI4 Master Read или AXI Master Write порты в таблице интерфейса Целевой платформы, сгенерируйте ядро IP HDL и интегрируйте ядро IP в свой Vivado® или исходные проекты Qsys. В сгенерированном HDL-коде для ядра IP DUT, Data порты сопоставлены с 512- битные интерфейсы. Несколько блоков FIFO сгенерированы, соответствуя каждому элементу векторного входа.
ENTITY DUT_ip IS
PORT( IPCORE_CLK : IN std_logic; -- ufix1
IPCORE_RESETN : IN std_logic; -- ufix1
AXI4_Master_Rd_RDATA : IN std_logic_vector(511 DOWNTO 0); -- ufix256
...
...
AXI4_Master_Wr_WDATA : OUT std_logic_vector(511 DOWNTO 0); -- ufix256
...
);
END DUT_ip;Этот рисунок иллюстрирует порядок, в котором векторные данные записаны в, и считайте форму.
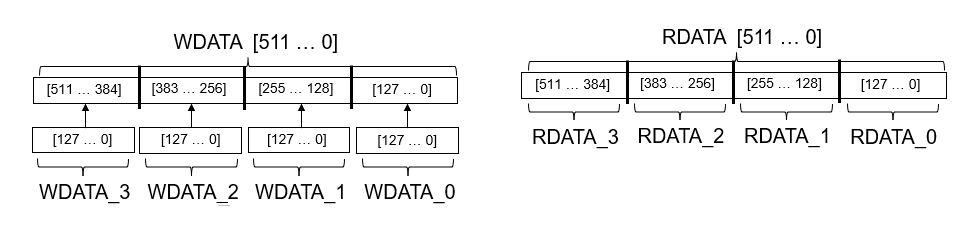
В HDL-коде для ядра IP DUT вы видите как AXI4_Master_Rd_RDATA и AXI4_master_Wr_WDATA интерфейсы сопоставлены с портами DUT и порядком, в котором данные записаны в интерфейс AXI4 Master, и затем читайте назад.
...
...
--------------------------------------------------------------------
AXI4 Master Read Sequence
--------------------------------------------------------------------
AXI4_Master_Rd_RDATA_0 <= AXI4_Master_Rd_RDATA_unsigned(127 DOWNTO 0);
AXI4_Master_Rd_RDATA_1 <= AXI4_Master_Rd_RDATA_unsigned_1(255 DOWNTO 128);
AXI4_Master_Rd_RDATA_2 <= AXI4_Master_Rd_RDATA_unsigned_7(383 DOWNTO 256);
AXI4_Master_Rd_RDATA_3 <= AXI4_Master_Rd_RDATA_unsigned_7(511 DOWNTO 384);
--------------------------------------------------------------------
AXI4 Master Write Sequence
--------------------------------------------------------------------
AXI4_Master_Wr_WDATA_tmp <= unsigned(AXI4_Master_Wr_WDATA_Vec_3) &
unsigned(AXI4_Master_Wr_WDATA_Vec_2) &
unsigned(AXI4_Master_Wr_WDATA_Vec_1) &
unsigned(AXI4_Master_Wr_WDATA_Vec_0);
AXI4_Master_Wr_WDATA <= std_logic_vector(AXI4_Master_Wr_WDATA_tmp);
...
...
Если вы используете нестандартную битную ширину для Ведущего устройства AXI4 Data порт, Data порт обновляется до стандартного битного контейнера ширины, который имеет больший размер. Стандартные битные ширины включают 32, 64, 128, 256, 512, и 1024 биты. Например, если вы используете вектор, который имеет четыре 35- битные элементы, получившаяся битная ширина 140 биты (35x4) сопоставлен с 256- битный интерфейс AXI4 Master. В Записи образовывают канал Data порт, биты 255 к 141 дополнены, обнуляет. При Чтении образовывают канал Data порт, биты 255 к 141 проигнорированы.
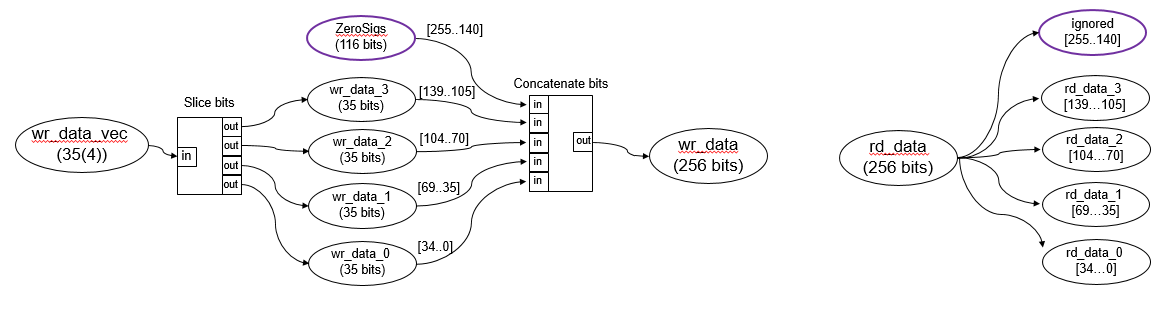
Используя нестандартные битные ширины может оказать влияние эффективности, потому что целая пропускная способность интерфейса AXI4 Master не используется. Чтобы избежать хитов эффективности, используйте стандартные ширины бита AXI.
Программное обеспечение HDL Coder поддерживает проекты с несколькими частотами дискретизации, когда вы запускаете рабочий процесс Генерации Ядра IP. Когда вы сопоставляете интерфейсные порты с Основными интерфейсами AXI4, чтобы использовать несколько частот дискретизации, гарантировать, что порты DUT, которые сопоставляют с этими интерфейсами AXI4, запущенными на самом быстром уровне проекта после генерации HDL-кода.
Чтобы узнать больше, смотрите Многоскоростную Генерацию Ядра IP.
Можно интегрировать сгенерированное ядро IP HDL с Основными интерфейсами AXI4 в эти исходные проекты HDL Coder:
Default System with External DDR3 Memory Access: Когда вашей целевой платформой является Xilinx Zynq ZC706 evaluation kit.
Default System with External DDR4 Memory Access: Когда вашей целевой платформой является Altera Arria10 SoC development kit.
Чтобы использовать эти исходные проекты, необходимо было установить HDL Verifier™. Этот рисунок показывает блок-схему высокого уровня архитектуры исходного проекта.
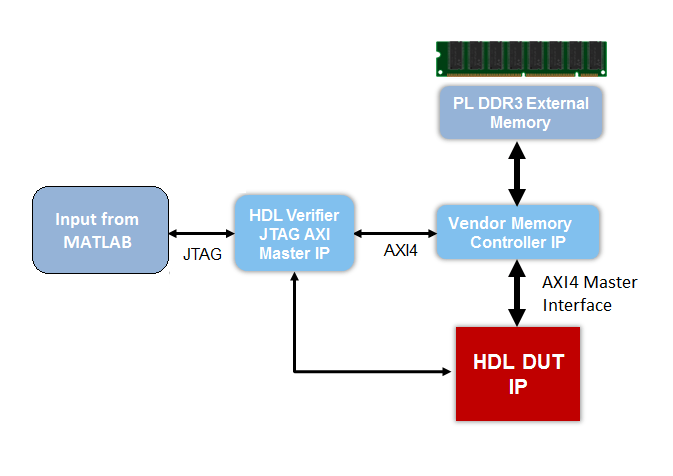
В этой архитектуре, HDL DUT IP блок соответствует ядру IP, которое сгенерировано от IP Core Generation рабочий процесс. Другие блоки в архитектуре представляют предопределенный исходный проект, который состоит из основанного на MATLAB® JTAG AXI Master IP это обеспечивается HDL Verifier. После того, как вы запускаете проект FPGA на плате, с помощью JTAG AXI Master IP, можно использовать входные данные в MATLAB, чтобы инициализировать встроенную внешнюю память DDR3. HDL DUT IP ядро читает входные данные из внешней памяти через интерфейс AXI4 Master. Ядро IP затем выполняет расчет алгоритма и пишет результат в память DDR3 через интерфейс AXI4 Master. JTAG AXI Master IP может считать результат памяти DDR3 и затем проверить результат в MATLAB.
Используя addAXI4MasterInterface метод hdlcoder.ReferenceDesign класс, можно интегрировать ядро IP с Основным Интерфейсом AXI4 в собственный исходный проект.
Synthesis tool: Должен быть Xilinx Vivado или Altera QUARTUS II. Xilinx ISE не поддерживается.
Target workflow: используйте IP Core Generation рабочий процесс. Чтобы запустить рабочий процесс, откройте HDL Workflow Advisor из своего алгоритма DUT в Simulink. MATLAB к рабочему процессу HDL не поддерживается.
Processor/FPGA synchronization: Должен быть Free running режим.
