SoC Blockset™ включает постанализ методом моделирования данных о диагностике памяти. Эти графики обеспечивают высокоуровневую диагностику эффективности системы памяти модели. Эти графики являются вычисленными измерениями от симуляции вашей модели. Это полагает, что тип данных, шаг расчета и тактовая частота вычисляют пропускную способность вашей модели памяти, и считает количество пакетов выполняемым на порт memory.
Чтобы включить сигнал, входящий в систему симуляция, выберите Hardware Implementation на диалоговом окне Configuration Parameters. Под Hardware Board Settings> Target Hardware Resources> FPGA design (debug), выберите желаемый Memory channel diagnostic level.
Этот рисунок показывает datapath от одного алгоритма FPGA до другого алгоритма FPGA через канал памяти.
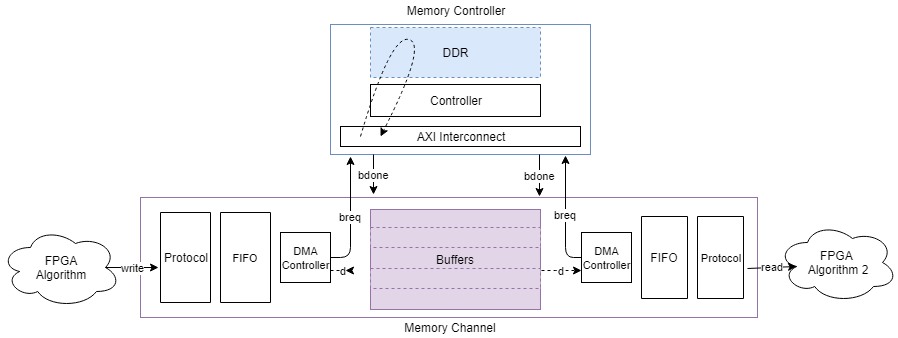
Можно просмотреть графики задержки канала для datapath (представленный A, B, C, и D в изображении) от маски блока Memory Channel. Вы можете пропускная способность представления memory, разорвать количество и измерения задержки управления (представленный 1, 2, 3, и 4 в изображении) от маски блока Memory Controller.
datapath с алгоритма FPGA на процессор подается через драйвер DMA и процессор задачи и проиллюстрирован в этом изображении.
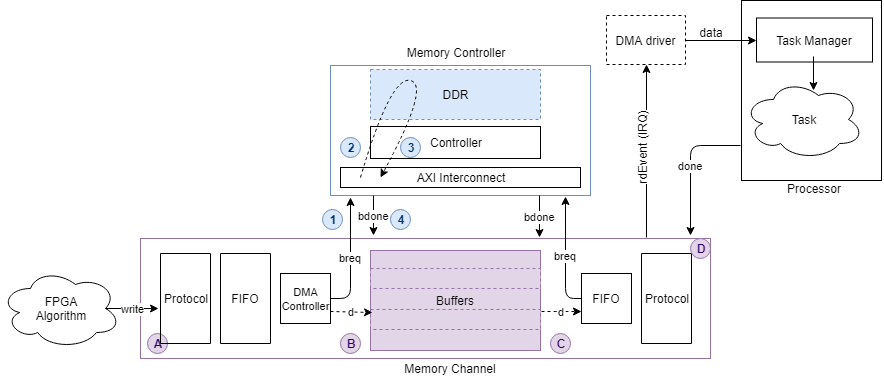
Информацией о задержке Канала памяти является доступная симуляция сообщения на канал. После симуляции вашей модели откройте маску блока Memory Channel. На вкладке Performance нажмите Launch performance plots. Это действие открывает новое окно с несколькими опциями управления, чтобы отобразить эти различные задержки:
Buffer write complete – Эта опция показывает время, которое требуется между изданием запроса записи к тому, когда буфер полностью записан. Это - путь между A и B на рисунке.
Buffer read complete – Эта опция показывает время, которое требуется между изданием запроса чтения к тому, когда буфер читается и доступен снова для записи. Это - путь между C и D на рисунке. Эта опция только доступна, если читатель является алгоритмом FPGA (не алгоритм процессора). Если читатель является алгоритмом процессора, на этот раз показывает нулем.
Buffer task execution complete – Эта опция показывает время, которое требуется между изданием запроса чтения к тому, когда буфер читается и доступен снова для записи. Это - путь между C и D на рисунке. Эта опция только доступна, если читатель является алгоритмом процессора (не алгоритм FPGA). Если читатель является алгоритмом FPGA, на этот раз показывает нулем.
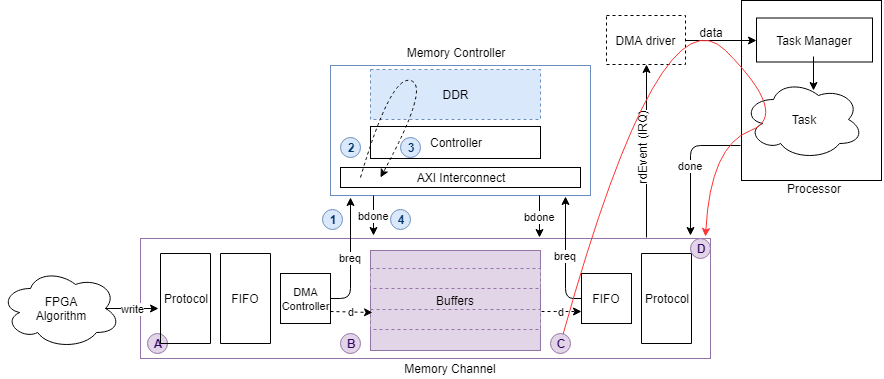
Buffer task execution complete показывает время, которое требуется для этих событий, чтобы произойти:
Буфер записи полон.
Канал выпустил запрос на прерывание (IRQ) к процессору.
Процедура обработки прерывания (ISR) выполняется.
Задача планируется.
Задача начала выполняться.
Задача считала данные.
Задача опционально обработала данные.
Задача отправляет done предупредите назад к каналу.
Этот после фигуры показывает путь к задержке для выполнения задачи, чтобы завершиться как Красная стрела от C до D.
Averaging Window (s) – Задайте время, в секундах, для ширины окна усреднения. График изображается в виде графика как скользящее среднее значение, с помощью окна времени с заданной шириной. Можно также задать minMax , или auto.
min – Используйте это значение, чтобы видеть данные без любого усреднения. Общий график задержки выравнивается с метками Instantaneous Total Latency.
max – Используйте это значение, чтобы видеть полное среднее значение для целой симуляции.
auto – Используйте это значение, чтобы видеть усреднение по количеству буферов в вашем канале.
Instantaneous Total Latency – Это показывает дискретные общие измерения задержки на буфер.
Если вы добавляете Buffer write complete в Buffer read complete или Buffer task execution complete, график отображает полную задержку от средства записи читателю. Это изображение показывает общий график задержки для Данных о Потоковой передаче от Оборудования до примера программного обеспечения.
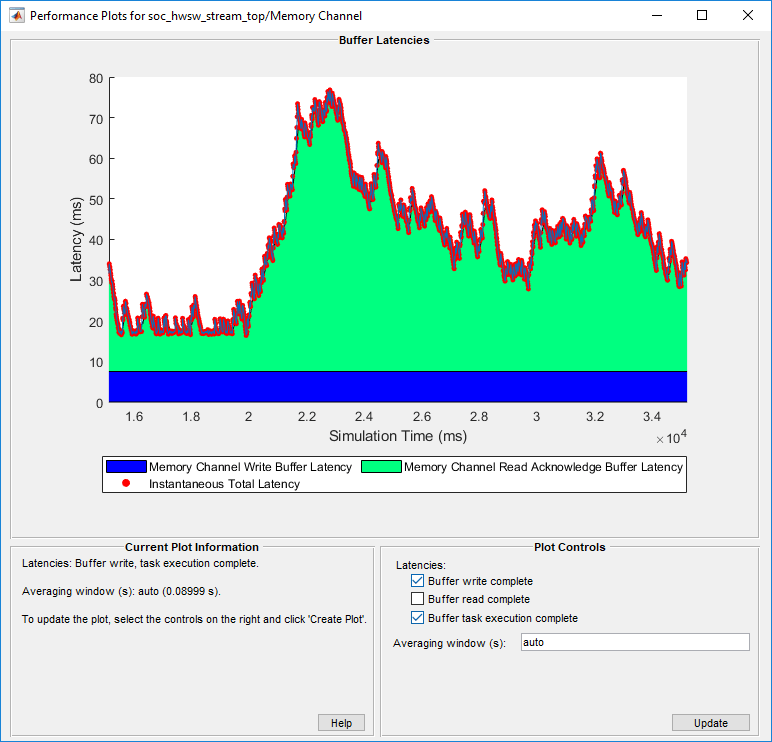
Обратите внимание на то, что задержки показывают по окну усреднения одной секунды. Мгновенная общая задержка показывает пик в задержке как 76,8267 мс. Используйте эту информацию, чтобы проверить модель по требованиям.
Информацией о задержке Контроллера памяти является доступная симуляция сообщения. После симуляции вашей модели откройте маску блока Memory Controller. На вкладке Performance нажмите Launch performance plots. Это действие открывает новое окно с несколькими опциями управления, чтобы отобразить показатели производительности.
Этот рисунок показывает datapath от одного алгоритма FPGA до другого алгоритма FPGA через канал памяти.
Во вкладке Latencies выберите ведущее устройство, для которого вы хотите изобразить задержки в виде графика. Выберите из любой из этих опций:
Burst request to first transfer complete – Эта опция показывает время, которое требуется с момента, блок Memory Channel выпускает запрос групповой записи к первой передаче данных. Эта задержка составляет арбитраж или взаимосвязанные задержки. Это - путь между 1 и 2 на рисунке.
Burst execution latency – Эта опция показывает время, которое требуется из первой передачи данных к тому, когда пакет записан в память. Это - путь между 2 и 3 на рисунке.
Burst last transfer to complete latency – Эта опция показывает время, которое требуется с момента, который пакет завершает к тому, когда блок Memory Controller выпускает burst-done предупредите с блоком Memory Channel. Это - путь между 3 и 4 на рисунке.
Averaging Window (s) – Задайте время, в секундах, для ширины окна усреднения. График изображается в виде графика как скользящее среднее значение, с помощью окна времени с заданной шириной. Можно также задать minMax , или auto.
min – Используйте это значение, чтобы видеть данные без любого усреднения. Общий график задержки выравнивается с метками Instantaneous Total Latency.
max – Используйте это значение, чтобы видеть полное среднее значение для целой симуляции.
auto – Используйте это значение, чтобы видеть усреднение более чем 1% пакетов во время симуляции.
Instantaneous Total Latency – Эта опция показывает дискретные общие измерения задержки на пакет.
Нажмите Create Plot, чтобы видеть задержку для выбранных ведущих устройств по длительности времени симуляции. Это изображение показывает общую задержку для Master 2 в Анализировать Пропускной способности Памяти Используя пример Генераторов Трафика.
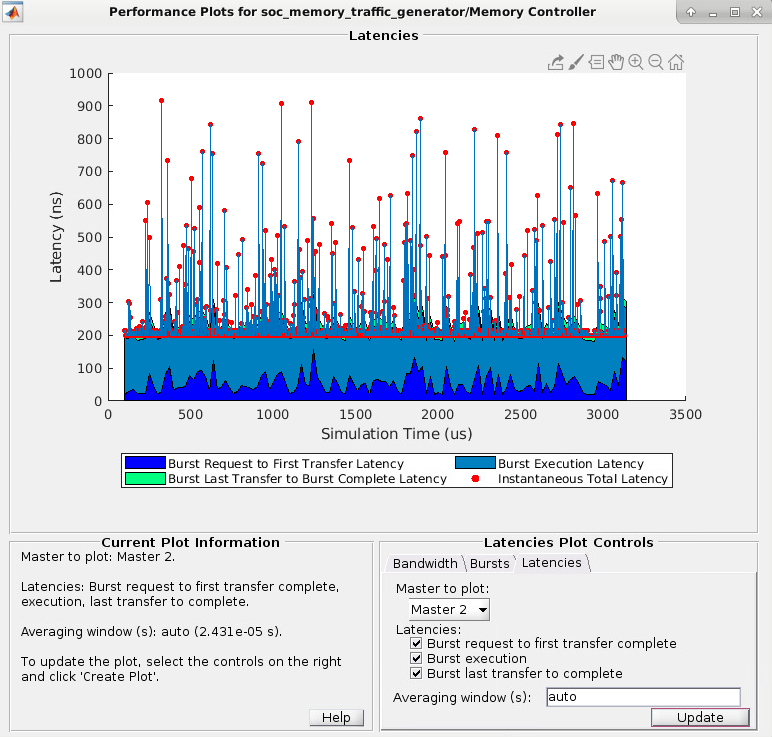
Примечание
Графики задержки контроллера памяти не доступны, когда ведущее устройство является процессором.
Можно затем увеличить масштаб, чтобы анализировать пиковую мгновенную задержку: 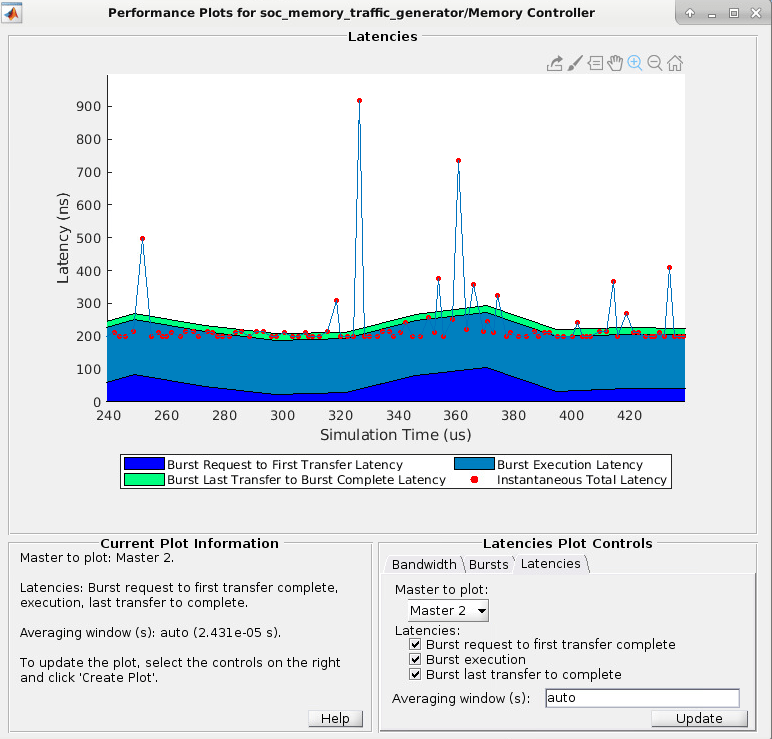
Во вкладке Bandwidth выберите ведущие устройства, для которых вы хотите изобразить пропускную способность в виде графика. Нажмите Create Plot, чтобы видеть пропускную способность, в мегабайтах в секунду, для выбранных ведущих устройств по длительности времени симуляции. Это изображение показывает пропускную способность для Анализировать Пропускной способности Памяти Используя пример Генераторов Трафика.
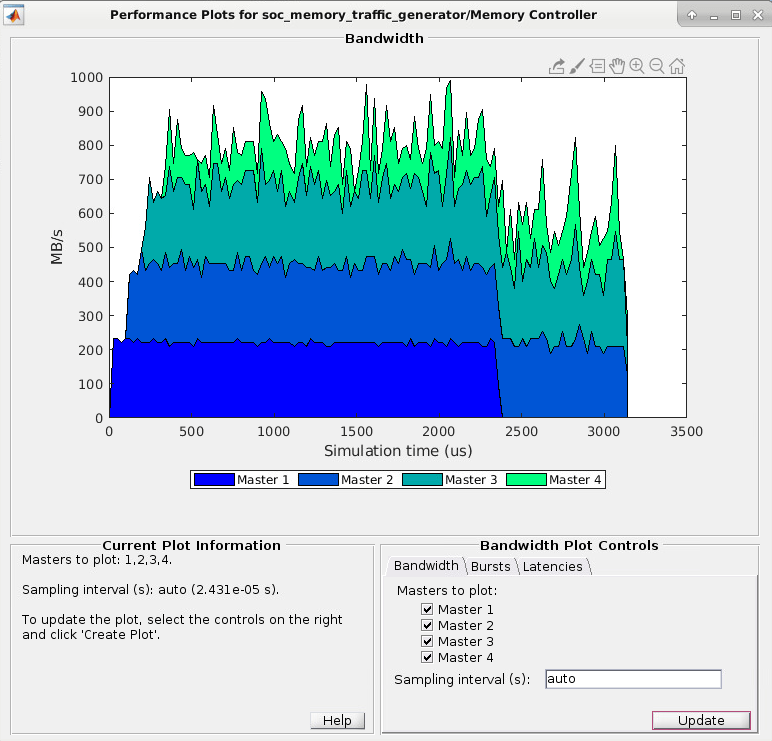
Примечание
Информация о пропускной способности не отображена, когда ведущее устройство является процессором.
Во вкладке Bursts выберите ведущие устройства, для которых вы хотите изобразить пакеты в виде графика. Нажмите Create Plot, чтобы видеть количество пакетов, выполняемых для выбранного ведущего устройства по длительности времени симуляции. Это изображение показывает, что пакет значит Анализировать Пропускную способность Памяти Используя пример Генераторов Трафика.
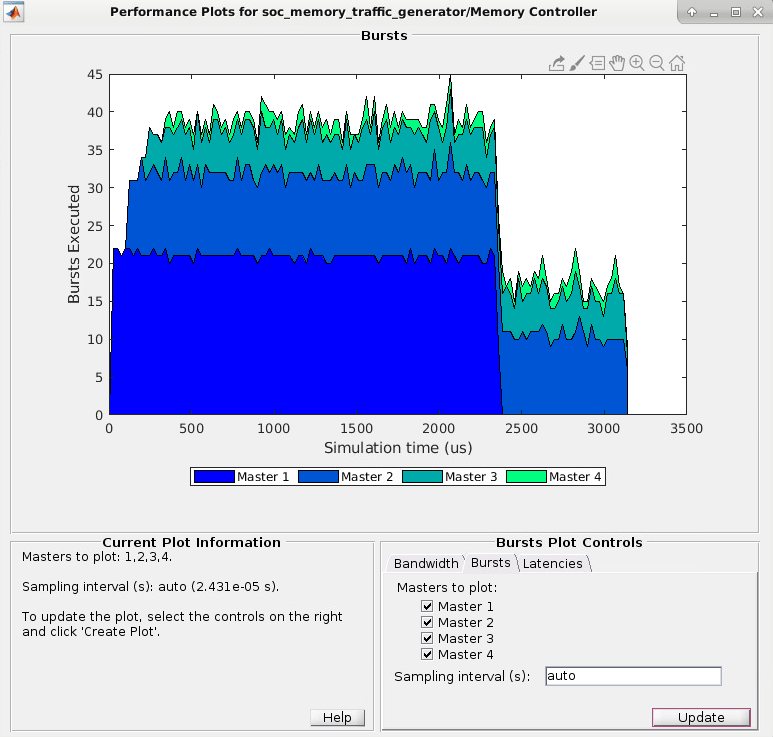
Примечание
Информация о пропускной способности не отображена, когда ведущее устройство является процессором.
Memory Channel | Memory Controller
