Потеря классификации для классификатора нейронной сети
L = loss(Mdl,Tbl,ResponseVarName)Mdl использование данных о предикторе в таблице Tbl и класс помечает в ResponseVarName табличная переменная.
L возвращен как скалярное значение, которое представляет ошибку классификации по умолчанию.
L = loss(___,Name,Value)
Вычислите ошибку классификации наборов тестов классификатора нейронной сети.
Загрузите patients набор данных. Составьте таблицу от набора данных. Каждая строка соответствует одному пациенту, и каждый столбец соответствует диагностической переменной. Используйте Smoker переменная как переменная отклика и остальная часть переменных как предикторы.
load patients
tbl = table(Diastolic,Systolic,Gender,Height,Weight,Age,Smoker);Разделите данные на набор обучающих данных tblTrain и набор тестов tblTest при помощи стратифицированного раздела затяжки. Программное обеспечение резервирует приблизительно 30% наблюдений для набора тестовых данных и использует остальную часть наблюдений для обучающего набора данных.
rng("default") % For reproducibility of the partition c = cvpartition(tbl.Smoker,"Holdout",0.30); trainingIndices = training(c); testIndices = test(c); tblTrain = tbl(trainingIndices,:); tblTest = tbl(testIndices,:);
Обучите классификатор нейронной сети с помощью набора обучающих данных. Задайте Smoker столбец tblTrain как переменная отклика. Задайте, чтобы стандартизировать числовые предикторы.
Mdl = fitcnet(tblTrain,"Smoker", ... "Standardize",true);
Вычислите ошибку классификации наборов тестов. Ошибка классификации является типом потерь по умолчанию для классификаторов нейронной сети.
testError = loss(Mdl,tblTest,"Smoker")testError = 0.0671
testAccuracy = 1 - testError
testAccuracy = 0.9329
Модель нейронной сети правильно классифицирует приблизительно 93% наблюдений набора тестов.
Выполните выбор признаков путем сравнения полей классификации наборов тестов, ребер, ошибок и предсказаний. Сравните метрики набора тестов для модели, обученной с помощью всех предикторов для метрик набора тестов для модели, обученной только с помощью подмножества предикторов.
Загрузите файл примера fisheriris.csv, который содержит ирисовые данные включая длину чашелистика, ширину чашелистика, лепестковую длину, лепестковую ширину и тип разновидностей. Считайте файл в таблицу.
fishertable = readtable('fisheriris.csv');Разделите данные на набор обучающих данных trainTbl и набор тестов testTbl при помощи стратифицированного раздела затяжки. Программное обеспечение резервирует приблизительно 30% наблюдений для набора тестовых данных и использует остальную часть наблюдений для обучающего набора данных.
rng("default") c = cvpartition(fishertable.Species,"Holdout",0.3); trainTbl = fishertable(training(c),:); testTbl = fishertable(test(c),:);
Обучите один классификатор нейронной сети с помощью всех предикторов в наборе обучающих данных и обучите другой классификатор с помощью всех предикторов кроме PetalWidth. Для обеих моделей задайте Species как переменная отклика, и стандартизируют предикторы.
allMdl = fitcnet(trainTbl,"Species","Standardize",true); subsetMdl = fitcnet(trainTbl,"Species ~ SepalLength + SepalWidth + PetalLength", ... "Standardize",true);
Вычислите поля классификации наборов тестов для этих двух моделей. Поскольку набор тестов включает только 45 наблюдений, отобразите поля с помощью столбчатых графиков.
Для каждого наблюдения поле классификации является различием между классификационной оценкой для истинного класса и максимальным счетом к ложным классам. Поскольку классификаторы нейронной сети возвращают классификационные оценки, которые являются апостериорными вероятностями, граничные значения близко к 1 указывают на уверенные классификации, и отрицательные граничные значения указывают на misclassifications.
tiledlayout(2,1) % Top axes ax1 = nexttile; allMargins = margin(allMdl,testTbl); bar(ax1,allMargins) xlabel(ax1,"Observation") ylabel(ax1,"Margin") title(ax1,"All Predictors") % Bottom axes ax2 = nexttile; subsetMargins = margin(subsetMdl,testTbl); bar(ax2,subsetMargins) xlabel(ax2,"Observation") ylabel(ax2,"Margin") title(ax2,"Subset of Predictors")

Сравните ребро классификации наборов тестов или среднее значение полей классификации, этих двух моделей.
allEdge = edge(allMdl,testTbl)
allEdge = 0.8198
subsetEdge = edge(subsetMdl,testTbl)
subsetEdge = 0.9556
На основе полей классификации наборов тестов и ребер, модель, обученная на подмножестве предикторов, кажется, превосходит по характеристикам модель, обученную на всех предикторах.
Сравните ошибку классификации наборов тестов этих двух моделей.
allError = loss(allMdl,testTbl); allAccuracy = 1-allError
allAccuracy = 0.9111
subsetError = loss(subsetMdl,testTbl); subsetAccuracy = 1-subsetError
subsetAccuracy = 0.9778
Снова, модель обучила использование, которое только подмножество предикторов, кажется, выполняет лучше, чем модель, обученная с помощью всех предикторов.
Визуализируйте результаты классификации наборов тестов с помощью матриц беспорядка.
allLabels = predict(allMdl,testTbl);
figure
confusionchart(testTbl.Species,allLabels)
title("All Predictors")
subsetLabels = predict(subsetMdl,testTbl);
figure
confusionchart(testTbl.Species,subsetLabels)
title("Subset of Predictors")
Модель обучалась, использование всех предикторов неправильно классифицирует четыре из наблюдений набора тестов. Модель обучалась, использование подмножества предикторов неправильно классифицирует только одно из наблюдений набора тестов.
Учитывая эффективность набора тестов этих двух моделей, рассмотрите использование обученного использования модели всех предикторов кроме PetalWidth.
Функции Classification loss измеряют прогнозирующую погрешность моделей классификации. Когда вы сравниваете тот же тип потери среди многих моделей, более низкая потеря указывает на лучшую прогнозную модель.
Рассмотрите следующий сценарий.
L является средневзвешенной потерей классификации.
n является объемом выборки.
Для бинарной классификации:
yj является наблюдаемой меткой класса. Программные коды это как –1 или 1, указывая на отрицательный или положительный класс (или первый или второй класс в ClassNames свойство), соответственно.
f (Xj) является классификационной оценкой положительного класса для наблюдения (строка) j данных о предикторе X.
mj = yj f (Xj) является классификационной оценкой для классификации наблюдения j в класс, соответствующий yj. Положительные значения mj указывают на правильную классификацию и не способствуют очень средней потере. Отрицательные величины mj указывают на неправильную классификацию и значительно способствуют средней потере.
Для алгоритмов, которые поддерживают классификацию мультиклассов (то есть, K ≥ 3):
yj* является вектором из K – 1 нуль, с 1 в положении, соответствующем истинному, наблюдаемому классу yj. Например, если истинный класс второго наблюдения является третьим классом и K = 4, то y 2* = [0 0 1 0] ′. Порядок классов соответствует порядку в ClassNames свойство входной модели.
f (Xj) является длиной вектор K из музыки класса к наблюдению j данных о предикторе X. Порядок баллов соответствует порядку классов в ClassNames свойство входной модели.
mj = yj* ′ f (Xj). Поэтому mj является скалярной классификационной оценкой, которую модель предсказывает для истинного, наблюдаемого класса.
Весом для наблюдения j является wj. Программное обеспечение нормирует веса наблюдения так, чтобы они суммировали к соответствующей предшествующей вероятности класса. Программное обеспечение также нормирует априорные вероятности, таким образом, они суммируют к 1. Поэтому
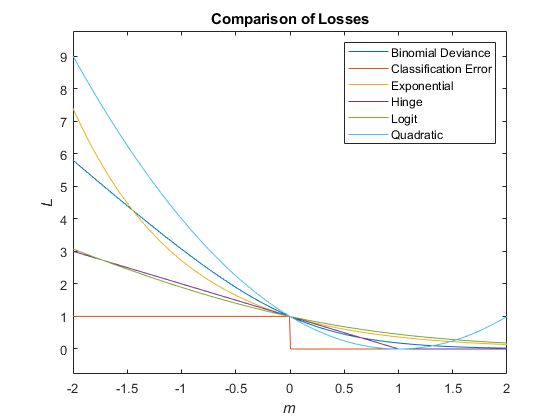
Учитывая этот сценарий, следующая таблица описывает поддерживаемые функции потерь, которые можно задать при помощи 'LossFun' аргумент пары "имя-значение".
| Функция потерь | Значение LossFun | Уравнение |
|---|---|---|
| Биномиальное отклонение | 'binodeviance' | |
| Неправильно классифицированный уровень в десятичном числе | 'classiferror' | метка класса, соответствующая классу с максимальным счетом. I {·} является функцией индикатора. |
| Потеря перекрестной энтропии | 'crossentropy' |
Взвешенная потеря перекрестной энтропии где веса нормированы, чтобы суммировать к n вместо 1. |
| Экспоненциальная потеря | 'exponential' | |
| Потеря стержня | 'hinge' | |
| Потеря логита | 'logit' | |
| Минимальный ожидал стоимость misclassification | 'mincost' |
Программное обеспечение вычисляет взвешенную минимальную ожидаемую стоимость классификации с помощью этой процедуры для наблюдений j = 1..., n.
Взвешенное среднее минимального ожидало, что потеря стоимости misclassification Если вы используете матрицу стоимости по умолчанию (чье значение элемента 0 для правильной классификации и 1 для неправильной классификации), то |
| Квадратичная потеря | 'quadratic' |
Этот рисунок сравнивает функции потерь (кроме 'crossentropy' и 'mincost') по счету m для одного наблюдения. Некоторые функции нормированы, чтобы пройти через точку (0,1).
ClassificationNeuralNetwork | CompactClassificationNeuralNetwork | edge | fitcnet | margin | predict
