Потеря классификации для перекрестной подтвержденной модели классификации ядер
loss = kfoldLoss(CVMdl)ClassificationPartitionedKernel) CVMdl. Для каждого сгиба, kfoldLoss вычисляет потерю классификации для наблюдений сгиба валидации с помощью модели, обученной на наблюдениях учебного сгиба.
По умолчанию, kfoldLoss возвращает ошибку классификации.
loss = kfoldLoss(CVMdl,Name,Value)
Функции Classification loss измеряют прогнозирующую погрешность моделей классификации. Когда вы сравниваете тот же тип потери среди многих моделей, более низкая потеря указывает на лучшую прогнозную модель.
Предположим следующее:
L является средневзвешенной потерей классификации.
n является объемом выборки.
yj является наблюдаемой меткой класса. Программные коды это как –1 или 1, указывая на отрицательный или положительный класс (или первый или второй класс в ClassNames свойство), соответственно.
f (Xj) является классификационной оценкой положительного класса для наблюдения (строка) j данных о предикторе X.
mj = yj f (Xj) является классификационной оценкой для классификации наблюдения j в класс, соответствующий yj. Положительные значения mj указывают на правильную классификацию и не способствуют очень средней потере. Отрицательные величины mj указывают на неправильную классификацию и значительно способствуют средней потере.
Весом для наблюдения j является wj. Программное обеспечение нормирует веса наблюдения так, чтобы они суммировали к соответствующей предшествующей вероятности класса. Программное обеспечение также нормирует априорные вероятности так, чтобы они суммировали к 1. Поэтому
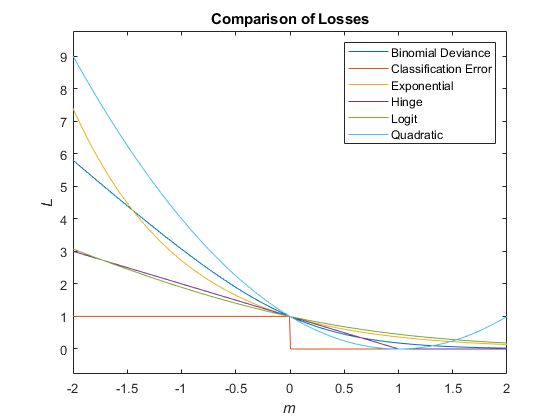
Эта таблица описывает поддерживаемые функции потерь, которые можно задать при помощи 'LossFun' аргумент значения имени.
| Функция потерь | Значение LossFun | Уравнение |
|---|---|---|
| Биномиальное отклонение | 'binodeviance' | |
| Экспоненциальная потеря | 'exponential' | |
| Неправильно классифицированный уровень в десятичном числе | 'classiferror' | метка класса, соответствующая классу с максимальным счетом. I {·} является функцией индикатора. |
| Потеря стержня | 'hinge' | |
| Потеря логита | 'logit' | |
| Минимальный ожидал стоимость misclassification | 'mincost' |
Программное обеспечение вычисляет взвешенную минимальную ожидаемую стоимость классификации с помощью этой процедуры для наблюдений j = 1..., n.
Взвешенное среднее минимального ожидало, что потеря стоимости misclassification Если вы используете матрицу стоимости по умолчанию (чье значение элемента 0 для правильной классификации и 1 для неправильной классификации), то |
| Квадратичная потеря | 'quadratic' |
Этот рисунок сравнивает функции потерь (кроме 'mincost') по счету m для одного наблюдения. Некоторые функции нормированы, чтобы пройти через точку (0,1).