Обучите модель регрессии нейронной сети
Использование fitrnet обучать feedforward, полностью соединенную нейронную сеть для регрессии. Первый полносвязный слой нейронной сети имеет связь от сетевого входа (данные о предикторе), и каждый последующий слой имеет связь от предыдущего слоя. Каждый полносвязный слой умножает вход на матрицу веса и затем добавляет вектор смещения. Функция активации следует за каждым полносвязным слоем, исключая последнее. Итоговый полносвязный слой производит выход сети, а именно, предсказанные значения отклика. Для получения дополнительной информации смотрите Структуру Нейронной сети.
Mdl = fitrnet(Tbl,ResponseVarName)Mdl регрессии нейронной сети обученное использование предикторов в таблице Tbl и значения отклика в ResponseVarName табличная переменная.
Mdl = fitrnet(___,Name,Value)LayerSizes и Activations аргументы значения имени.
Обучите модель регрессии нейронной сети и оцените эффективность модели на наборе тестов.
Загрузите carbig набор данных, который содержит измерения автомобилей, сделанных в 1970-х и в начале 1980-х. Составьте таблицу, содержащую переменные предикторы Acceleration, Displacement, и так далее, а также переменная отклика MPG.
load carbig cars = table(Acceleration,Displacement,Horsepower, ... Model_Year,Origin,Weight,MPG);
Разделите данные в наборы обучающих данных и наборы тестов. Используйте приблизительно 80% наблюдений, чтобы обучить модель нейронной сети, и 20% наблюдений проверять производительность обученной модели на новых данных. Используйте cvpartition разделить данные.
rng("default") % For reproducibility of the data partition c = cvpartition(length(MPG),"Holdout",0.20); trainingIdx = training(c); % Training set indices carsTrain = cars(trainingIdx,:); testIdx = test(c); % Test set indices carsTest = cars(testIdx,:);
Обучите модель регрессии нейронной сети путем передачи carsTrain обучающие данные к fitrnet функция. Для лучших результатов задайте, чтобы стандартизировать данные о предикторе.
Mdl = fitrnet(carsTrain,"MPG","Standardize",true)
Mdl =
RegressionNeuralNetwork
PredictorNames: {'Acceleration' 'Displacement' 'Horsepower' 'Model_Year' 'Origin' 'Weight'}
ResponseName: 'MPG'
CategoricalPredictors: 5
ResponseTransform: 'none'
NumObservations: 314
LayerSizes: 10
Activations: 'relu'
OutputLayerActivation: 'linear'
Solver: 'LBFGS'
ConvergenceInfo: [1×1 struct]
TrainingHistory: [1000×7 table]
Properties, Methods
Mdl обученный RegressionNeuralNetwork модель. Можно использовать запись через точку, чтобы получить доступ к свойствам Mdl. Например, можно задать Mdl.TrainingHistory получить больше информации об учебной истории модели нейронной сети.
Оцените эффективность модели регрессии на наборе тестов путем вычисления тестовой среднеквадратической ошибки (MSE). Меньшие значения MSE указывают на лучшую эффективность.
testMSE = loss(Mdl,carsTest,"MPG")testMSE = 16.6154
Задайте структуру модели регрессии нейронной сети, включая размер полносвязных слоев.
Загрузите carbig набор данных, который содержит измерения автомобилей, сделанных в 1970-х и в начале 1980-х. Создайте матричный X содержа переменные предикторы Acceleration, Cylinders, и так далее. Сохраните переменную отклика MPG в переменной Y.
load carbig
X = [Acceleration Cylinders Displacement Weight];
Y = MPG;Разделите данные в обучающие данные (XTrain и YTrain) и тестовые данные (XTest и YTest). Зарезервируйте приблизительно 20% наблюдений для тестирования и используйте остальную часть наблюдений для обучения.
rng("default") % For reproducibility of the partition c = cvpartition(length(Y),"Holdout",0.20); trainingIdx = training(c); % Indices for the training set XTrain = X(trainingIdx,:); YTrain = Y(trainingIdx); testIdx = test(c); % Indices for the test set XTest = X(testIdx,:); YTest = Y(testIdx);
Обучите модель регрессии нейронной сети. Задайте, чтобы стандартизировать данные о предикторе и иметь 30 выходных параметров в первом полносвязном слое и 10 выходных параметров во втором полносвязном слое. По умолчанию оба слоя используют исправленный линейный модуль (ReLU) функция активации. Можно изменить функции активации для полносвязных слоев при помощи Activations аргумент значения имени.
Mdl = fitrnet(XTrain,YTrain,"Standardize",true, ... "LayerSizes",[30 10])
Mdl =
RegressionNeuralNetwork
ResponseName: 'Y'
CategoricalPredictors: []
ResponseTransform: 'none'
NumObservations: 318
LayerSizes: [30 10]
Activations: 'relu'
OutputLayerActivation: 'linear'
Solver: 'LBFGS'
ConvergenceInfo: [1×1 struct]
TrainingHistory: [1000×7 table]
Properties, Methods
Доступ к весам и смещениям для полносвязных слоев обученной модели при помощи LayerWeights и LayerBiases свойства Mdl. Первые два элемента каждого свойства соответствуют значениям для первых двух полносвязных слоев, и третий элемент соответствует значениям для итогового полносвязного слоя для регрессии. Например, отобразите веса и смещения для первого полносвязного слоя.
Mdl.LayerWeights{1}ans = 30×4
-1.0617 0.1287 0.0797 0.4648
-0.6497 -1.4565 -2.6026 2.6962
-0.6420 0.2744 -0.0234 -0.0252
-1.9727 -0.4665 -0.5833 0.9371
-0.4373 0.1607 0.3930 0.7859
0.5091 -0.0032 -0.6503 -1.6694
0.0123 -0.2624 -2.2928 -1.0965
-0.1386 1.2747 0.4085 0.5395
-0.1755 1.5641 -3.1896 -1.1336
0.4401 0.4942 1.8957 -1.1617
⋮
Mdl.LayerBiases{1}ans = 30×1
-1.3086
-1.6205
-0.7815
1.5382
-0.5256
1.2394
-2.3078
-1.0709
-1.8898
1.9443
⋮
Итоговый полносвязный слой имеет тот выход. Количество слоя выходные параметры соответствует первой размерности весов слоя и смещений слоя.
size(Mdl.LayerWeights{end})ans = 1×2
1 10
size(Mdl.LayerBiases{end})ans = 1×2
1 1
Чтобы оценить эффективность обученной модели, вычислите среднеквадратическую ошибку (MSE) набора тестов для Mdl. Меньшие значения MSE указывают на лучшую эффективность.
testMSE = loss(Mdl,XTest,YTest)
testMSE = 17.2022
Сравните предсказанные значения отклика набора тестов с истинными значениями отклика. Постройте предсказанные мили на галлон (MPG) вдоль вертикальной оси и истинный MPG вдоль горизонтальной оси. Точки на ссылочной линии указывают на правильные предсказания. Хорошая модель производит предсказания, которые рассеиваются около линии.
testPredictions = predict(Mdl,XTest); plot(YTest,testPredictions,".") hold on plot(YTest,YTest) hold off xlabel("True MPG") ylabel("Predicted MPG")

В каждой итерации учебного процесса вычислите потерю валидации нейронной сети. Остановите учебный процесс рано, если потеря валидации достигает разумного минимума.
Загрузите patients набор данных. Составьте таблицу от набора данных. Каждая строка соответствует одному пациенту, и каждый столбец соответствует диагностической переменной. Используйте Systolic переменная как переменная отклика и остальная часть переменных как предикторы.
load patients
tbl = table(Age,Diastolic,Gender,Height,Smoker,Weight,Systolic);Разделите данные на набор обучающих данных tblTrain и валидация установила tblValidation. Программное обеспечение резервирует приблизительно 30% наблюдений для набора данных валидации и использует остальную часть наблюдений для обучающего набора данных.
rng("default") % For reproducibility of the partition c = cvpartition(size(tbl,1),"Holdout",0.30); trainingIndices = training(c); validationIndices = test(c); tblTrain = tbl(trainingIndices,:); tblValidation = tbl(validationIndices,:);
Обучите модель регрессии нейронной сети при помощи набора обучающих данных. Задайте Systolic столбец tblTrain как переменная отклика. Оцените модель в каждой итерации при помощи набора валидации. Задайте, чтобы отобразить учебную информацию в каждой итерации при помощи Verbose аргумент значения имени. По умолчанию учебный процесс заканчивается рано, если потеря валидации больше или равна минимальной потере валидации, вычисленной до сих пор, шесть раз подряд. Чтобы изменить число раз, потере валидации позволяют быть больше или быть равной минимуму, задать ValidationPatience аргумент значения имени.
Mdl = fitrnet(tblTrain,"Systolic", ... "ValidationData",tblValidation, ... "Verbose",1);
|==========================================================================================| | Iteration | Train Loss | Gradient | Step | Iteration | Validation | Validation | | | | | | Time (sec) | Loss | Checks | |==========================================================================================| | 1| 516.021993| 3220.880047| 0.644473| 0.005193| 568.289202| 0| | 2| 313.056754| 229.931405| 0.067026| 0.002658| 304.023695| 0| | 3| 308.461807| 277.166516| 0.011122| 0.001363| 296.935608| 0| | 4| 262.492770| 844.627934| 0.143022| 0.000531| 240.559640| 0| | 5| 169.558740| 1131.714363| 0.336463| 0.000652| 152.531663| 0| | 6| 89.134368| 362.084104| 0.382677| 0.001059| 83.147478| 0| | 7| 83.309729| 994.830303| 0.199923| 0.000515| 76.634122| 0| | 8| 70.731524| 327.637362| 0.041366| 0.000361| 66.421750| 0| | 9| 66.650091| 124.369963| 0.125232| 0.000380| 65.914063| 0| | 10| 66.404753| 36.699328| 0.016768| 0.000363| 65.357335| 0| |==========================================================================================| | Iteration | Train Loss | Gradient | Step | Iteration | Validation | Validation | | | | | | Time (sec) | Loss | Checks | |==========================================================================================| | 11| 66.357143| 46.712988| 0.009405| 0.001130| 65.306106| 0| | 12| 66.268225| 54.079264| 0.007953| 0.001023| 65.234391| 0| | 13| 65.788550| 99.453225| 0.030942| 0.000436| 64.869708| 0| | 14| 64.821095| 186.344649| 0.048078| 0.000295| 64.191533| 0| | 15| 62.353896| 319.273873| 0.107160| 0.000290| 62.618374| 0| | 16| 57.836593| 447.826470| 0.184985| 0.000287| 60.087065| 0| | 17| 51.188884| 524.631067| 0.253062| 0.000287| 56.646294| 0| | 18| 41.755601| 189.072516| 0.318515| 0.000286| 49.046823| 0| | 19| 37.539854| 78.602559| 0.382284| 0.000290| 44.633562| 0| | 20| 36.845322| 151.837884| 0.211286| 0.000286| 47.291367| 1| |==========================================================================================| | Iteration | Train Loss | Gradient | Step | Iteration | Validation | Validation | | | | | | Time (sec) | Loss | Checks | |==========================================================================================| | 21| 36.218289| 62.826818| 0.142748| 0.000362| 46.139104| 2| | 22| 35.776921| 53.606315| 0.215188| 0.000321| 46.170460| 3| | 23| 35.729085| 24.400342| 0.060096| 0.001023| 45.318023| 4| | 24| 35.622031| 9.602277| 0.121153| 0.000289| 45.791861| 5| | 25| 35.573317| 10.735070| 0.126854| 0.000291| 46.062826| 6| |==========================================================================================|
Создайте график, который сравнивает учебную среднеквадратическую ошибку (MSE) и валидацию MSE в каждой итерации. По умолчанию, fitrnet хранит информацию потери в TrainingHistory свойство объекта Mdl. Можно получить доступ к этой информации при помощи записи через точку.
iteration = Mdl.TrainingHistory.Iteration; trainLosses = Mdl.TrainingHistory.TrainingLoss; valLosses = Mdl.TrainingHistory.ValidationLoss; plot(iteration,trainLosses,iteration,valLosses) legend(["Training","Validation"]) xlabel("Iteration") ylabel("Mean Squared Error")

Проверяйте итерацию, которая соответствует минимальной валидации MSE. Финал возвратил модель Mdl модель, обученная в этой итерации.
[~,minIdx] = min(valLosses); iteration(minIdx)
ans = 19
Оцените потерю перекрестной проверки моделей нейронной сети с различными сильными местами регуляризации и выберите силу регуляризации, соответствующую лучшей модели выполнения.
Загрузите carbig набор данных, который содержит измерения автомобилей, сделанных в 1970-х и в начале 1980-х. Составьте таблицу, содержащую переменные предикторы Acceleration, Displacement, и так далее, а также переменная отклика MPG. Удалите наблюдения из таблицы с отсутствующими значениями.
load carbig tbl = table(Acceleration,Displacement,Horsepower, ... Model_Year,Origin,Weight,MPG); cars = rmmissing(tbl);
Создайте cvpartition объект для 5-кратной перекрестной проверки. cvp делит данные в пять сгибов, где каждый сгиб имеет примерно то же количество наблюдений. Установите случайный seed на значение по умолчанию для воспроизводимости раздела.
rng("default") n = size(cars,1); cvp = cvpartition(n,"KFold",5);
Вычислите среднеквадратическую ошибку (MSE) перекрестной проверки для моделей регрессии нейронной сети с различными сильными местами регуляризации. Попробуйте сильные места регуляризации порядка 1/n, где n является количеством наблюдений. Задайте, чтобы стандартизировать данные перед обучением модели нейронной сети.
1/n
ans = 0.0026
lambda = (0:0.5:5)*1e-3; cvloss = zeros(length(lambda),1); for i = 1:length(lambda) cvMdl = fitrnet(cars,"MPG","Lambda",lambda(i), ... "CVPartition",cvp,"Standardize",true); cvloss(i) = kfoldLoss(cvMdl); end
Постройте график результатов. Найдите силу регуляризации, соответствующую самой низкой перекрестной проверке MSE.
plot(lambda,cvloss) xlabel("Regularization Strength") ylabel("Cross-Validation Loss")

[~,idx] = min(cvloss); bestLambda = lambda(idx)
bestLambda = 0
Обучите модель регрессии нейронной сети использование bestLambda сила регуляризации.
Mdl = fitrnet(cars,"MPG","Lambda",bestLambda, ... "Standardize",true)
Mdl =
RegressionNeuralNetwork
PredictorNames: {'Acceleration' 'Displacement' 'Horsepower' 'Model_Year' 'Origin' 'Weight'}
ResponseName: 'MPG'
CategoricalPredictors: 5
ResponseTransform: 'none'
NumObservations: 392
LayerSizes: 10
Activations: 'relu'
OutputLayerActivation: 'linear'
Solver: 'LBFGS'
ConvergenceInfo: [1×1 struct]
TrainingHistory: [1000×7 table]
Properties, Methods
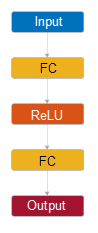
Модель регрессии нейронной сети по умолчанию имеет следующую структуру слоя.
| Структура | Описание |
|---|---|
|
| Введите — Этот слой соответствует данным о предикторе в Tbl или X. |
Первый полносвязный слой — Этот слой имеет 10 выходных параметров по умолчанию.
| |
Функция активации ReLU —
| |
Итоговый полносвязный слой — Этот слой имеет тот выход.
| |
| Вывод Этот слой соответствует предсказанным значениям отклика. |
Для примера, который показывает, как модель нейронной сети регрессии с этой структурой слоя возвращает предсказания, смотрите, Предсказывают Используя Структуру Слоя Модели Нейронной сети Регрессии.
Всегда пытайтесь стандартизировать числовые предикторы (см. Standardize). Стандартизация делает предикторы нечувствительными к шкалам, по которым они измеряются.
[1] Glorot, Ксавьер и Иосуа Бенхио. “Изучая трудность учебных глубоких нейронных сетей прямого распространения”. В Продолжениях тринадцатой международной конференции по вопросам искусственного интеллекта и статистики, стр 249–256. 2010.
[2] Он, Kaiming, Сянюй Чжан, Шаоцин Жэнь и Цзянь Сунь. “Копаясь глубоко в выпрямителях: Превосходная эффективность человеческого уровня на imagenet классификации”. В Продолжениях международной конференции IEEE по вопросам компьютерного зрения, стр 1026–1034. 2015.
[3] Nocedal, J. и С. Дж. Райт. Числовая Оптимизация, 2-й редактор, Нью-Йорк: Спрингер, 2006.
CompactRegressionNeuralNetwork | loss | predict | RegressionNeuralNetwork | RegressionPartitionedModel