Incremental learning или online learning, является ветвью машинного обучения, которое включает обработку входящие данные от потока данных — постоянно и в режиме реального времени — возможно, учитывая мало ни к какому знанию распределения переменных предикторов, объема выборки, аспектов предсказания или целевой функции (включая соответствующие настраивающие значения параметров), и имеют ли наблюдения метки.
Алгоритмы пошагового обучения гибки, эффективны, и адаптивны. Следующие характеристики отличают пошаговое обучение от традиционного машинного обучения:
Инкрементная модель является подходящей к данным быстро и эффективно, что означает, что это может адаптироваться, в режиме реального времени, к изменениям (или drifts) в распределении данных.
Поскольку метки наблюдения могут отсутствовать, когда соответствующие данные о предикторе доступны, алгоритм должен смочь сгенерировать предсказания от последней версии модели быстро и задержать обучение модель.
Мало информации может быть известно о населении, прежде чем пошаговое обучение запустится. Поэтому алгоритм может быть запущен с cold start. Например, для проблем классификации, имена классов не могут быть известны до окончания наблюдений процессов модели. Когда достаточно информации известно, прежде чем изучение начинается (например, у вас есть хорошие оценки линейных коэффициентов модели), можно указать такую информацию, чтобы предоставить модели warm start.
Поскольку наблюдения могут прибыть в поток, объем выборки является, вероятно, неизвестным и возможно большим, который делает хранение данных неэффективным или невозможным. Поэтому алгоритм должен обработать наблюдения, когда они доступны и прежде чем система отбросит их. Эта характеристика пошагового обучения делает гиперпараметр, настраивающийся трудный или невозможный.
В традиционном машинном обучении пакет маркированных данных доступен, чтобы выполнить перекрестную проверку, чтобы оценить ошибку обобщения и гиперпараметры мелодии, вывести распределение переменного предиктора и подбирать модель. Однако получившаяся модель должна быть переобучена с начала при лежании в основе дрейфа распределений, или модель ухудшается. Несмотря на то, что выполнение перекрестной проверки, чтобы настроить гиперпараметры затрудняет в среде пошагового обучения, методы пошагового обучения гибки, потому что они могут адаптироваться к дрейфу распределения в режиме реального времени с прогнозирующей точностью, приближающейся к той из традиционно обученной модели, когда модель обучает больше данных.
Предположим, что инкрементная модель готова сгенерировать предсказания и измерить ее прогнозирующую эффективность. Учитывая входящие фрагменты наблюдений, схема пошагового обучения обрабатывает данные в режиме реального времени и любым из следующих способов, но обычно заданным порядком:
Модель Evaluate: Отследите прогнозирующую эффективность модели, когда истинные метки будут доступны, или на входящих данных только по раздвижному окну наблюдений, или по целой истории модели, используемой для пошагового обучения.
Обнаружьте дрейф: Проверяйте на структурные пропуски или дрейф распределения. Например, определите, изменилось ли распределение какого-либо переменного предиктора достаточно.
Модель Train: Обновите модель по образованию это на входящих наблюдениях, когда истинные метки доступны или когда текущая модель достаточно ухудшилась.
Сгенерируйте предсказания: Предскажите метки из последней модели.
Эта процедура является особым случаем пошагового обучения, в котором все входящие фрагменты обработаны как тест (затяжка) наборы. Процедура называется interleaved test-then-train или prequential evaluation [1].
Если недостаточная информация существует для инкрементной модели, чтобы сгенерировать предсказания, или вы не хотите отслеживать прогнозирующую эффективность модели, потому что это не было обучено достаточно, можно включать дополнительный начальный шаг, чтобы найти соответствующие значения для гиперпараметров для моделей, которые поддерживают один (estimation period) или период начальной подготовки перед оценкой модели (metrics warm-up period).
Как пример проблемы пошагового обучения, рассмотрите умный термостат, который автоматически устанавливает температуру, учитывая температуру окружающей среды, относительную влажность, время суток и другие измерения, и может изучить внутренние температурные настройки пользователя. Предположим, что производитель подготовил устройство путем встраивания известной модели, которая описывает настройки среднего человека, учитывая измерения. После установки устройство собирает данные каждую минуту и корректирует температуру к ее предварительным установкам. Термостат настраивает встроенную модель или переобучает себя, на основе действий пользователя или бездействий с устройством. Этот цикл может продолжиться неопределенно. Если термостат ограничил дисковое пространство, чтобы хранить исторические данные, это должно переобучить себя в режиме реального времени. Если производитель не подготовил устройство с известной моделью, устройство переобучает себя чаще.
Функциональности Statistics and Machine Learning Toolbox™ позволяют вам реализовать пошаговое обучение для классификации или регрессию. Как другие функциональности машинного обучения Statistics and Machine Learning Toolbox, точка входа в пошаговое обучение является объектом пошагового обучения, который вы передаете функциям с данными, чтобы реализовать пошаговое обучение. В отличие от других функций машинного обучения, данные не требуются, чтобы создавать объект пошагового обучения. Однако объект пошагового обучения задает, как обработать входящие данные, такой как тогда, когда подбирать модель, измерить показатели производительности или выполнить оба действия, в дополнение к параметрической форме и специфичных для проблемы опций модели.
Эта таблица содержит доступные объекты модели точки входа для пошагового обучения с их поддерживаемой целью машинного обучения, типом модели и любой информацией, запрошенной после создания.
| Объект модели | Цель | Тип модели | Запрошенная информация |
|---|---|---|---|
incrementalClassificationLinear | Бинарная классификация | Линейный SVM и логистическая регрессия | 'none' |
incrementalClassificationNaiveBayes | Классификация Mutliclass | Наивный Байесов с нормальными условными распределениями предиктора | Максимальное количество классов, ожидаемых в данных во время пошагового обучения или имен всех ожидаемых классов |
incrementalRegressionLinear | Регрессия | Линейный | 'none' |
Свойства объекта модели пошагового обучения задают:
Характеристики данных, такие как количество переменных предикторов NumPredictors и их первые и вторые моменты.
Характеристики модели, такой как, для линейных моделей, тип ученика Learner, линейные коэффициенты Beta, и прервите Bias
Опции обучения, такой как, для линейных моделей, объективный решатель Solver и специфичные для решателя гиперпараметры, такие как гребенчатый штраф Lambda для стандартного и среднего стохастического градиентного спуска (SGD и ASGD)
Характеристики оценки производительности модели и опции, такой как, является ли моделью теплый IsWarm, какие показатели производительности отследить Metrics, и последние значения показателей производительности
В отличие от этого, при работе с другими объектами модели машинного обучения, можно создать любую модель путем прямого вызова объекта и определения значений свойств опций с помощью аргументов значения имени; вы не должны подбирать модель к данным, чтобы создать тот. Эта функция удобна, когда у вас есть мало информации о данных или модели перед обучением она. В зависимости от ваших технических требований программное обеспечение может осуществить оценку и метрические периоды прогрева, в которые инкрементные подходящие функции выводят характеристики данных и затем обучают модель оценке результатов деятельности. По умолчанию, для линейных моделей, программное обеспечение решает целевую функцию с помощью адаптивного инвариантного к масштабу решателя, который не требует настройки и нечувствителен к шкалам переменного предиктора [2].
В качестве альтернативы можно преобразовать традиционно обученную модель в любую модель при помощи incrementalLearner функция. Конвертируемые модели включают машины опорных векторов (SVM) для бинарной классификации и регрессии, наивной классификации Бейеса и моделей линейной регрессии. Например, incrementalLearner преобразует обученную линейную модель классификации типа ClassificationLinear к incrementalClassificationLinear объект. По умолчанию программное обеспечение полагает, что преобразованные модели подготовлены ко всем аспектам пошагового обучения (преобразованные модели являются теплыми). incrementalLearner переносит характеристики данных (такие как имена классов), адаптированные параметры и опции, доступные для пошагового обучения из традиционно обученной преобразовываемой модели. Например:
Для наивной классификации Бейеса, incrementalLearner переносит все имена классов в данных, ожидаемых во время пошагового обучения, и подходящие моменты условных распределений предиктора (DistributionParameters).
Для линейных моделей, если объективный решатель традиционно обученной модели является SGD, incrementalLearner устанавливает решатель пошагового обучения на SGD.
Объект модели пошагового обучения задает все аспекты алгоритма пошагового обучения от учебной и подготовки к оценке модели до учебной и оценки модели. Чтобы реализовать пошаговое обучение, вы передаете сконфигурированную модель пошагового обучения инкрементной подходящей функциональной или функции оценки модели. Функции пошагового обучения Statistics and Machine Learning Toolbox предлагают два рабочих процесса, которые хорошо подходят для изучения prequential. Для простоты следующие описания рабочего процесса принимают, что модель готова оценить производительность модели (другими словами, модель является теплой).
Гибкий рабочий процесс — Когда фрагмент данных доступен:
Вычислите совокупный и метрики производительности модели окна путем передачи модели данных и текущей модели к updateMetrics функция. Данные обработаны как тест (затяжка) данные, потому что модель еще не была обучена на нем. updateMetrics перезаписывает производительность модели, сохраненную в модели новыми значениями. Для линейных моделей смотрите updateMetrics и для наивных моделей классификации Бейеса смотрите updateMetrics.
Опционально обнаружьте дрейф распределения или ухудшилась ли модель.
Обучите модель путем передачи входящего фрагмента данных и текущей модели к fit функция. fit функционируйте использует заданный решатель, чтобы подбирать модель к входящему фрагменту данных и перезаписывает текущие коэффициенты и смещение с новыми оценками. Для линейных моделей смотрите fit и для наивных моделей классификации Бейеса смотрите fit.
Гибкий рабочий процесс позволяет вам выполнить пользовательскую модель и оценки качества данных прежде, чем решить, обучить ли модель. Все шаги являются дополнительными, но вызов updateMetrics прежде fit когда вы планируете вызвать обе функции.
Сжатый рабочий процесс — Когда фрагмент данных будет доступен, предоставьте входящий фрагмент и сконфигурированную инкрементную модель к updateMetricsAndFit функция. updateMetricsAndFit вызовы updateMetrics сразу сопровождаемый fit. Сжатый рабочий процесс позволяет вам реализовать пошаговое обучение с prequential оценкой легко, когда вы планируете отследить производительность модели и обучить модель на всех входящих фрагментах данных. Для линейных моделей смотрите updateMetricsAndFit и для наивных моделей классификации Бейеса смотрите updateMetricsAndFit.
Если вы создаете инкрементный объект модели и выбираете рабочий процесс, чтобы использовать, запишите цикл, который реализует пошаговое обучение:
Считайте фрагмент наблюдений от потока данных, когда фрагмент будет доступен.
Реализуйте гибкий или сжатый рабочий процесс. Чтобы выполнить пошаговое обучение правильно, перезапишите входную модель с выходной моделью. Например:
% Flexible workflow Mdl = updateMetrics(Mdl,X,Y); % Insert optional code Mdl = fit(Mdl,X,Y); % Succinct workflow Mdl = updateMetricsAndFit(Mdl,X,Y);
loss функция. loss возвращает скалярную потерю; это не настраивает модель. Для линейных моделей смотрите loss и для наивных моделей классификации Бейеса смотрите loss.Настройки модели определяют, обучают ли функции пошагового обучения или оценивают производительность модели во время каждой итерации. Настройки могут измениться, когда функции обрабатывают данные. Для получения дополнительной информации смотрите Периоды Пошагового обучения.
Опционально:
Сгенерируйте предсказания путем передачи фрагмента и последней модели к predict. Для линейных моделей смотрите predict и для наивных моделей классификации Бейеса смотрите predict.
Если модель была подходящей к данным, вычислите потерю перезамены путем передачи фрагмента и последней модели к loss.
Для наивных моделей классификации Бейеса, logp функция позволяет вам обнаружить выбросы в режиме реального времени. Функция возвращает журнал безусловная плотность вероятности переменных предикторов при каждом наблюдении во фрагменте.
Учитывая входящие фрагменты данных, действия, выполняемые функциями пошагового обучения, зависят от текущей настройки или состояния модели. Этот рисунок показывает периоды (последовательные группы наблюдений), во время которого функции пошагового обучения выполняют конкретные действия.
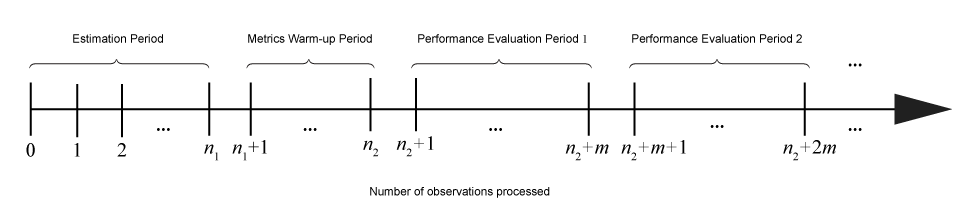
Эта таблица описывает действия, выполняемые функциями пошагового обучения в каждый период.
| Период | Связанные свойства модели | Размер (Количество наблюдений) | Действия |
|---|---|---|---|
| Оценка | EstimationPeriod, применяется к линейной классификации и моделям регрессии только | n 1 | При необходимости подходящие функции выбирают значения для гиперпараметров на основе наблюдений периода оценки. Действия включают следующее:
|
| Метрический прогрев | MetricsWarmupPeriod | n 2 – n 1 | Когда свойство
|
| Оценка результатов деятельности j | Metrics и MetricsWindowSize | m |
|
