Декодирование с низкой плотностью контроля четности (LDPC)
[ возвращает декодированную LDPC выходную матрицу out,actNumIter,finalParityChecks] = nrLDPCDecode(in,bgn,maxNumIter)out для матрицы входных данных in, номер базового графа bgnи максимальное количество итераций декодирования maxNumIter. Функция также возвращает фактическое количество итераций actNumIter и окончательные проверки четности по кодовому слову finalParityChecks.
Декодер использует алгоритм передачи сообщений суммарного произведения. Биты данных должны кодироваться LDPC, как определено в TS 38.212 Раздел 5.3.2 [1].
[ указывает необязательные аргументы пары имя-значение в дополнение к входным аргументам в предыдущем синтаксисе.out,actNumIter,finalParityChecks] = nrLDPCDecode(___,Name,Value)
nrLDPCDecode функция поддерживает эти четыре алгоритма декодирования LDPC.
Реализация алгоритма распространения убеждений основана на алгоритме декодирования, представленном в [2]. Для передаваемого кодового слова LDPC, c, где cn − 1), вход в декодер LDPC представляет собой логарифмическое отношение правдоподобия (LLR) выход канала для ci)).
В каждой итерации ключевые компоненты алгоритма обновляются на основе следующих уравнений:
qi′j))),
(rj′i), ) = L (ci) перед первой итерацией, и
(rj′i).
В конце каждой итерации ) является обновленной оценкой значения LLR для переданного бита ci. Значение Qi) является выходным сигналом мягкого решения ci. ) < 0, выход жесткого решения для ci равен 1. В противном случае выходной сигнал равен 0.
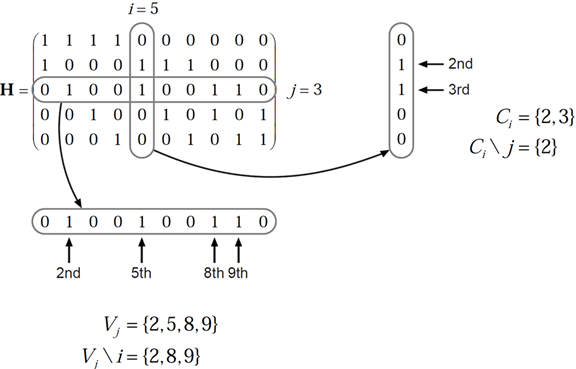
Наборы индексов и основаны на матрице контроля четности (PCM). Наборы индексов и соответствуют всем ненулевым элементам в столбце i и строке j ИКМ соответственно.
На этом рисунке показано вычисление этих наборов индексов в данном ИКМ для i = 5 и j = 3.
Чтобы избежать бесконечных чисел в уравнениях алгоритма, atanh (1) и atanh (-1) установлены в 19.07 и -19.07 соответственно. Из-за конечной точности MATLAB ® возвращает 1 для tanh (19.07) и -1 для tanh (-19.07).
Когда аргумент пары имя-значение 'Termination' имеет значение 'max'декодирование завершается после maxNumIter количество итераций. Когда 'Termination' имеет значение 'early'декодирование завершается, когда выполняются все проверки четности (0) или послеmaxNumIter количество итераций.
[1] 3GPP TS 38.212. "НР; мультиплексирование и канальное кодирование. "Проект партнерства 3-го поколения; Техническая спецификация на сеть радиодоступа группы.
[2] Галлагер, Роберт Г. Коды проверки четности с низкой плотностью, Кембридж, Массачусетс, MIT Press, 1963.
[3] Hocevar, D.E. «Архитектура декодера с уменьшенной сложностью посредством многоуровневого декодирования кодов LDPC». Семинар IEEE по системам обработки сигналов, 2004 год. SIPS 2004. дои: 10.1109/SIPS.2004.1363033
[4] Чен, Jinghu, R.M. Крем для загара, К. Джонс и Ян Ли. «Улучшены алгоритмы декодирования с минимальной суммой для нерегулярных LDPC-кодов». В разбирательстве. Международный симпозиум по теории информации, 2005 год. ISIT 2005. дои: 10.1109/ISIT.2005.1523374
