Очень трудно узнать, какой алгоритм обучения будет самым быстрым для данной проблемы. Это зависит от многих факторов, включая сложность проблемы, количество точек данных в обучающем наборе, количество весов и смещений в сети, цель ошибки и то, используется ли сеть для распознавания образов (дискриминантный анализ) или аппроксимации функций (регрессия). В этом разделе сравниваются различные алгоритмы обучения. Сети прямой связи обучаются шести различным проблемам. Три проблемы относятся к категории распознавания образов, а три другие - к категории аппроксимации функций. Две из проблем являются простыми «игрушечными» проблемами, в то время как другие четыре являются «реальными» проблемами. Используются сети с различными архитектурами и сложностями, и сети обучаются различным уровням точности.
В следующей таблице перечислены проверяемые алгоритмы и акронимы, используемые для их идентификации.
Акроним | Алгоритм | Описание |
|---|---|---|
LM | trainlm | Левенберг-Марквардт |
BFG | trainbfg | BFGS Квази-Ньютон |
RP | trainrp | Упругое обратное распространение |
SCG | trainscg | Масштабированный сопряженный градиент |
CGB | traincgb | Сопряжение градиента с перезапуском Пауэлла/Била |
CGF | traincgf | Сопряженный градиент Флетчера-Пауэлла |
CGP | traincgp | Сопряженный градиент Полака-Рибьера |
OSS | trainoss | Одношаговый секант |
GDX | traingdx | Обратное распространение переменной скорости обучения |
В следующей таблице перечислены шесть проблем эталонного тестирования и некоторые характеристики используемых сетей, процессов обучения и компьютеров.
Название проблемы | Тип проблемы | Структура сети | Цель ошибки | Компьютер |
|---|---|---|---|---|
ГРЕХ | Аппроксимация функции | 1-5-1 | 0.002 | Солнечный спарк 2 |
ПАРИТЕТ | Распознавание образов | 3-10-10-1 | 0.001 | Солнечный спарк 2 |
ДВИГАТЕЛЬ | Аппроксимация функции | 2-30-2 | 0.005 | Sun Enterprise 4000 |
РАК | Распознавание образов | 9-5-5-2 | 0.012 | Солнечный спарк 2 |
ХОЛЕСТЕРИН | Аппроксимация функции | 21-15-3 | 0.027 | Солнечный Спарк 20 |
ДИАБЕТ | Распознавание образов | 8-15-15-2 | 0.05 | Солнечный Спарк 20 |
Первый набор эталонных данных представляет собой простую задачу аппроксимации функции. Сеть 1-5-1, с tansig передаточные функции в скрытом слое и линейная передаточная функция в выходном слое используются для аппроксимации одного периода синусоидальной волны. В следующей таблице приведены результаты обучения сети с использованием девяти различных алгоритмов обучения. Каждая запись в таблице представляет 30 различных испытаний, где в каждом испытании используются разные случайные начальные веса. В каждом случае сеть обучают до тех пор, пока квадрат ошибки не станет меньше 0,002. Самый быстрый алгоритм для этой задачи - алгоритм Левенберга - Марквардта. В среднем он в четыре раза быстрее следующего самого быстрого алгоритма. Это тип задачи, для которой лучше всего подходит алгоритм LM - задача аппроксимации функции, где сеть имеет меньше ста весов и аппроксимация должна быть очень точной.
Алгоритм | Среднее время (и) | Отношение | Минимальное время (и) | Макс. Время (и) | Стд. (ы) |
|---|---|---|---|---|---|
LM | 1.14 | 1.00 | 0.65 | 1.83 | 0.38 |
BFG | 5.22 | 4.58 | 3.17 | 14.38 | 2.08 |
RP | 5.67 | 4.97 | 2.66 | 17.24 | 3.72 |
SCG | 6.09 | 5.34 | 3.18 | 23.64 | 3.81 |
CGB | 6.61 | 5.80 | 2.99 | 23.65 | 3.67 |
CGF | 7.86 | 6.89 | 3.57 | 31.23 | 4.76 |
CGP | 8.24 | 7.23 | 4.07 | 32.32 | 5.03 |
OSS | 9.64 | 8.46 | 3.97 | 59.63 | 9.79 |
GDX | 27.69 | 24.29 | 17.21 | 258.15 | 43.65 |
На производительность различных алгоритмов может влиять точность, требуемая для аппроксимации. Это показано на следующем рисунке, который отображает среднюю квадратную ошибку в зависимости от времени выполнения (усредненное за 30 испытаний) для нескольких репрезентативных алгоритмов. Здесь видно, что ошибка в алгоритме LM со временем уменьшается гораздо быстрее, чем другие показанные алгоритмы.
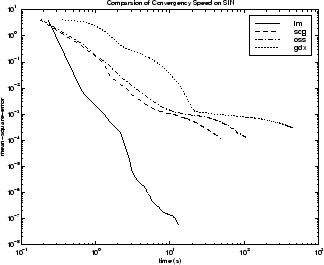
Взаимосвязь между алгоритмами дополнительно проиллюстрирована на следующем рисунке, на котором показано время, необходимое для сходимости, по сравнению со средней целью сходимости квадратной ошибки. Здесь видно, что по мере уменьшения цели ошибки улучшение, обеспечиваемое алгоритмом LM, становится более выраженным. Некоторые алгоритмы работают лучше по мере уменьшения цели ошибки (LM и BFG), а другие алгоритмы ухудшаются по мере уменьшения цели ошибки (OSS и GDX).
Второй проблемой эталонного теста является простая проблема распознавания образов - обнаружение четности 3-битного числа. Если количество единиц во входном шаблоне нечетное, то сеть должна выводить 1; в противном случае он должен выводить -1. Сеть, используемая для этой проблемы, представляет собой сеть 3-10-10-1 с нейронами тансиг в каждом слое. В следующей таблице приведены результаты обучения этой сети с использованием девяти различных алгоритмов. Каждая запись в таблице представляет 30 различных испытаний, где в каждом испытании используются разные случайные начальные веса. В каждом случае сеть обучается до тех пор, пока квадрат ошибки не станет меньше 0,001. Самый быстрый алгоритм для этой проблемы - алгоритм упругого обратного распространения, хотя алгоритмы сопряженного градиента (в частности, алгоритм масштабированного сопряженного градиента) почти такие же быстрые. Обратите внимание, что алгоритм LM не справляется с этой проблемой. В общем, алгоритм LM не так хорошо работает с проблемами распознавания образов, как с проблемами аппроксимации функций. Алгоритм LM предназначен для задач наименьших квадратов, которые являются приблизительно линейными. Поскольку выходные нейроны в проблемах распознавания образов, как правило, насыщены, вы не будете работать в линейной области.
Алгоритм | Среднее время (и) | Отношение | Минимальное время (и) | Макс. Время (и) | Стд. (ы) |
|---|---|---|---|---|---|
RP | 3.73 | 1.00 | 2.35 | 6.89 | 1.26 |
SCG | 4.09 | 1.10 | 2.36 | 7.48 | 1.56 |
CGP | 5.13 | 1.38 | 3.50 | 8.73 | 1.05 |
CGB | 5.30 | 1.42 | 3.91 | 11.59 | 1.35 |
CGF | 6.62 | 1.77 | 3.96 | 28.05 | 4.32 |
OSS | 8.00 | 2.14 | 5.06 | 14.41 | 1.92 |
LM | 13.07 | 3.50 | 6.48 | 23.78 | 4.96 |
BFG | 19.68 | 5.28 | 14.19 | 26.64 | 2.85 |
GDX | 27.07 | 7.26 | 25.21 | 28.52 | 0.86 |
Как и в случае проблем аппроксимации функций, на производительность различных алгоритмов может влиять точность, требуемая сетью. Это показано на следующем рисунке, на котором показана среднеквадратическая ошибка в зависимости от времени выполнения для некоторых типичных алгоритмов. Алгоритм LM быстро сходится после некоторого момента, но только после того, как другие алгоритмы уже сошлись.
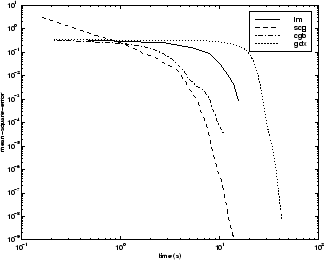
Взаимосвязь между алгоритмами дополнительно проиллюстрирована на следующем рисунке, на котором показано время, необходимое для сходимости, по сравнению со средней целью сходимости квадратной ошибки. Снова видно, что некоторые алгоритмы ухудшаются по мере уменьшения цели ошибки (OSS и BFG).
Третья задача эталона - это задача аппроксимации реалистичной функции (или нелинейной регрессии). Данные получают из работы двигателя. Входами в сеть являются частота вращения двигателя и уровни заправки, а выходами сети - крутящий момент и уровни выбросов. Сеть, используемая для этой проблемы, представляет собой сеть 2-30-2 с нейронами тансиг в скрытом слое и линейными нейронами в выходном слое. В следующей таблице приведены результаты обучения этой сети с использованием девяти различных алгоритмов. Каждая запись в таблице представляет 30 различных испытаний (10 испытаний для RP и GDX из-за временных ограничений), где в каждом испытании используются разные случайные начальные веса. В каждом случае сеть обучают до тех пор, пока квадрат ошибки не станет меньше 0,005. Самым быстрым алгоритмом для этой задачи является алгоритм LM, за которым следуют алгоритм квази-Ньютона BFGS и алгоритмы сопряженного градиента. Хотя это проблема аппроксимации функции, алгоритм LM не так явно превосходит, как это было в наборе данных SIN. В этом случае количество весов и смещений в сети значительно больше, чем используемое в проблеме SIN (152 против 16), и преимущества алгоритма LM уменьшаются по мере увеличения числа параметров сети.
Алгоритм | Среднее время (и) | Отношение | Минимальное время (и) | Макс. Время (и) | Стд. (ы) |
|---|---|---|---|---|---|
LM | 18.45 | 1.00 | 12.01 | 30.03 | 4.27 |
BFG | 27.12 | 1.47 | 16.42 | 47.36 | 5.95 |
SCG | 36.02 | 1.95 | 19.39 | 52.45 | 7.78 |
CGF | 37.93 | 2.06 | 18.89 | 50.34 | 6.12 |
CGB | 39.93 | 2.16 | 23.33 | 55.42 | 7.50 |
CGP | 44.30 | 2.40 | 24.99 | 71.55 | 9.89 |
OSS | 48.71 | 2.64 | 23.51 | 80.90 | 12.33 |
RP | 65.91 | 3.57 | 31.83 | 134.31 | 34.24 |
GDX | 188.50 | 10.22 | 81.59 | 279.90 | 66.67 |
На следующем рисунке показана среднеквадратическая ошибка в зависимости от времени выполнения для некоторых типичных алгоритмов. Производительность алгоритма LM улучшается с течением времени по сравнению с другими алгоритмами.
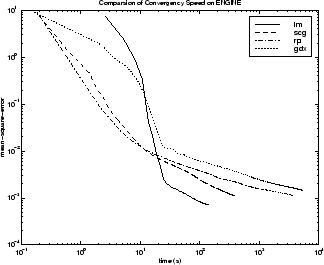
Взаимосвязь между алгоритмами дополнительно проиллюстрирована на следующем рисунке, на котором показано время, необходимое для сходимости, по сравнению со средней целью сходимости квадратной ошибки. Снова видно, что некоторые алгоритмы ухудшаются по мере уменьшения цели ошибки (GDX и RP), в то время как алгоритм LM улучшается.
Четвертая задача эталона - это задача реалистичного распознавания образов (или нелинейного дискриминантного анализа). Целью сети является классификация опухоли как доброкачественной или злокачественной на основе описаний клеток, собранных при микроскопическом исследовании. Входные атрибуты включают толщину комка, однородность размера и формы ячейки, величину предельной адгезии и частоту голых ядер. Данные были получены из больниц Университета Висконсина, Мэдисон, от доктора Уильяма Х. Вольберга. Сеть, используемая для этой проблемы, представляет собой сеть 9-5-5-2 с нейронами тансиг во всех слоях. В следующей таблице приведены результаты обучения этой сети с использованием девяти различных алгоритмов. Каждая запись в таблице представляет 30 различных испытаний, где в каждом испытании используются разные случайные начальные веса. В каждом случае сеть обучается до тех пор, пока квадрат ошибки не станет меньше 0,012. Несколько прогонов не смогли сойтись для некоторых алгоритмов, поэтому для получения статистики использовались только верхние 75% прогонов из каждого алгоритма.
Сопряженные алгоритмы градиента и упругое обратное распространение обеспечивают быструю сходимость, и алгоритм LM также является достаточно быстрым. Как и в случае набора данных четности, алгоритм LM не работает так же хорошо над проблемами распознавания образов, как и над проблемами аппроксимации функций.
Алгоритм | Среднее время (и) | Отношение | Минимальное время (и) | Макс. Время (и) | Стд. (ы) |
|---|---|---|---|---|---|
CGB | 80.27 | 1.00 | 55.07 | 102.31 | 13.17 |
RP | 83.41 | 1.04 | 59.51 | 109.39 | 13.44 |
SCG | 86.58 | 1.08 | 41.21 | 112.19 | 18.25 |
CGP | 87.70 | 1.09 | 56.35 | 116.37 | 18.03 |
CGF | 110.05 | 1.37 | 63.33 | 171.53 | 30.13 |
LM | 110.33 | 1.37 | 58.94 | 201.07 | 38.20 |
BFG | 209.60 | 2.61 | 118.92 | 318.18 | 58.44 |
GDX | 313.22 | 3.90 | 166.48 | 446.43 | 75.44 |
OSS | 463.87 | 5.78 | 250.62 | 599.99 | 97.35 |
На следующем рисунке показана среднеквадратическая ошибка в зависимости от времени выполнения для некоторых типичных алгоритмов. Для этой проблемы существует не так много изменений в производительности, как в предыдущих проблемах.
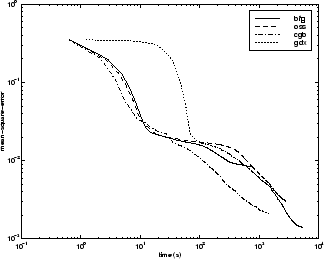
Взаимосвязь между алгоритмами дополнительно проиллюстрирована на следующем рисунке, на котором показано время, необходимое для сходимости, по сравнению со средней целью сходимости квадратной ошибки. Снова видно, что некоторые алгоритмы ухудшаются по мере уменьшения цели ошибки (OSS и BFG), в то время как алгоритм LM улучшается. Типично для алгоритма LM при любой проблеме, что его производительность улучшается по сравнению с другими алгоритмами по мере уменьшения цели ошибки.
Пятая задача эталона - это задача аппроксимации реалистичной функции (или нелинейной регрессии). Целью сети является прогнозирование уровней холестерина (ldl, hdl и vldl) на основе измерений 21 спектрального компонента. Данные были получены от доктора Нила Пурди, химического факультета, Университет штата Оклахома [PuLu92]. Сеть, используемая для этой проблемы, представляет собой сеть 21-15-3 с нейронами тансиг в скрытых слоях и линейными нейронами в выходном слое. В следующей таблице приведены результаты обучения этой сети с использованием девяти различных алгоритмов. Каждая запись в таблице представляет 20 различных испытаний (10 испытаний для RP и GDX), где в каждом испытании используются разные случайные начальные веса. В каждом случае сеть обучается до тех пор, пока квадрат ошибки не станет меньше 0,027.
Масштабируемый алгоритм сопряженного градиента имеет наилучшую производительность по этой проблеме, хотя все алгоритмы сопряженного градиента работают хорошо. Алгоритм LM не так хорошо выполняет эту задачу аппроксимации функции, как это было с двумя другими. Это происходит потому, что количество весов и отклонений в сети снова увеличилось (378 против 152 против 16). По мере увеличения числа параметров геометрически увеличивается требуемое в алгоритме LM вычисление.
Алгоритм | Среднее время (и) | Отношение | Минимальное время (и) | Макс. Время (и) | Стд. (ы) |
|---|---|---|---|---|---|
SCG | 99.73 | 1.00 | 83.10 | 113.40 | 9.93 |
CGP | 121.54 | 1.22 | 101.76 | 162.49 | 16.34 |
CGB | 124.06 | 1.2 | 107.64 | 146.90 | 14.62 |
CGF | 136.04 | 1.36 | 106.46 | 167.28 | 17.67 |
LM | 261.50 | 2.62 | 103.52 | 398.45 | 102.06 |
OSS | 268.55 | 2.69 | 197.84 | 372.99 | 56.79 |
BFG | 550.92 | 5.52 | 471.61 | 676.39 | 46.59 |
RP | 1519.00 | 15.23 | 581.17 | 2256.10 | 557.34 |
GDX | 3169.50 | 31.78 | 2514.90 | 4168.20 | 610.52 |
На следующем рисунке показана среднеквадратическая ошибка в зависимости от времени выполнения для некоторых типичных алгоритмов. Для этой проблемы можно увидеть, что алгоритм LM способен довести среднеквадратическую ошибку до более низкого уровня, чем другие алгоритмы. Алгоритмы SCG и RP обеспечивают самую быструю начальную сходимость.
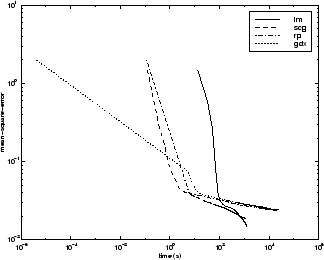
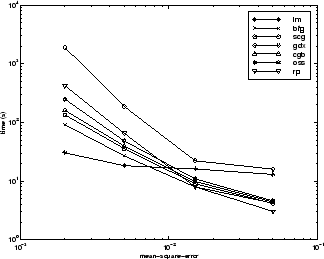
Взаимосвязь между алгоритмами дополнительно проиллюстрирована на следующем рисунке, на котором показано время, необходимое для сходимости, по сравнению со средней целью сходимости квадратной ошибки. Можно видеть, что алгоритмы LM и BFG улучшаются относительно других алгоритмов по мере уменьшения цели ошибки.
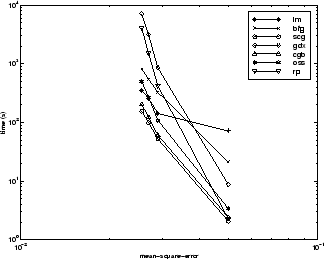
Шестой проблемой эталонного теста является проблема распознавания образов. Цель сети - решить, есть ли у человека диабет, на основе личных данных (возраст, количество беременностей) и результатов медицинских осмотров (например, артериальное давление, индекс массы тела, результат теста на толерантность к глюкозе и т.д.). Данные были получены из базы данных машинного обучения Калифорнийского университета в Ирвайне. Сеть, используемая для этой проблемы, представляет собой сеть 8-15-15-2 с нейронами тансиг во всех слоях. В следующей таблице приведены результаты обучения этой сети с использованием девяти различных алгоритмов. Каждая запись в таблице представляет 10 различных испытаний, где в каждом испытании используются разные случайные начальные веса. В каждом случае сеть обучают до тех пор, пока квадрат ошибки не станет меньше 0,05.
Алгоритмы сопряженного градиента и упругое обратное распространение обеспечивают быструю сходимость. Результаты по этой проблеме согласуются с другими рассмотренными проблемами распознавания образов. Алгоритм RP хорошо работает над всеми проблемами распознавания образов. Это разумно, потому что этот алгоритм был разработан для преодоления трудностей, вызванных тренировками с сигмоидальными функциями, которые имеют очень небольшие уклоны при работе далеко от центральной точки. Для распознавания образов используются функции переноса сигмоидов на уровне вывода, и необходимо, чтобы сеть работала в хвостах сигмоидной функции.
Алгоритм | Среднее время (и) | Отношение | Минимальное время (и) | Макс. Время (и) | Стд. (ы) |
|---|---|---|---|---|---|
RP | 323.90 | 1.00 | 187.43 | 576.90 | 111.37 |
SCG | 390.53 | 1.21 | 267.99 | 487.17 | 75.07 |
CGB | 394.67 | 1.22 | 312.25 | 558.21 | 85.38 |
CGP | 415.90 | 1.28 | 320.62 | 614.62 | 94.77 |
OSS | 784.00 | 2.42 | 706.89 | 936.52 | 76.37 |
CGF | 784.50 | 2.42 | 629.42 | 1082.20 | 144.63 |
LM | 1028.10 | 3.17 | 802.01 | 1269.50 | 166.31 |
BFG | 1821.00 | 5.62 | 1415.80 | 3254.50 | 546.36 |
GDX | 7687.00 | 23.73 | 5169.20 | 10350.00 | 2015.00 |
На следующем рисунке показана среднеквадратическая ошибка в зависимости от времени выполнения для некоторых типичных алгоритмов. Как и в случае с другими проблемами, вы видите, что SCG и RP имеют быструю начальную сходимость, в то время как алгоритм LM способен обеспечить меньшую конечную ошибку.
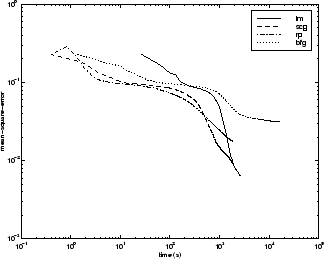
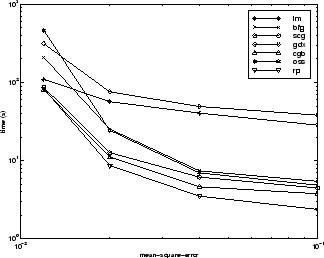
Взаимосвязь между алгоритмами дополнительно проиллюстрирована на следующем рисунке, на котором показано время, необходимое для сходимости, по сравнению со средней целью сходимости квадратной ошибки. В этом случае можно увидеть, что алгоритм BFG ухудшается по мере уменьшения цели ошибки, в то время как алгоритм LM улучшается. Алгоритм RP лучше всего, за исключением наименьшей цели ошибки, где SCG лучше.
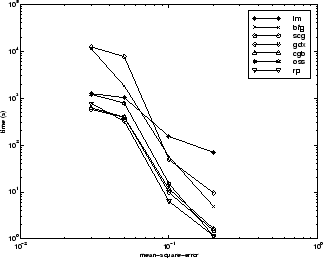
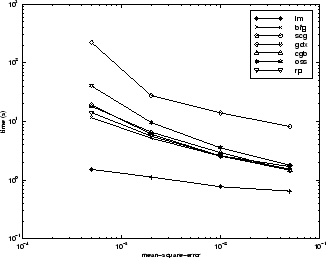
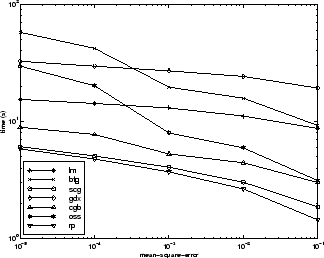
Существует несколько характеристик алгоритма, которые можно вывести из описанных экспериментов. В целом, на задачах аппроксимации функций, для сетей, которые содержат до нескольких сотен весов, алгоритм Левенберга-Марквардта будет иметь самую быструю сходимость. Это преимущество особенно заметно, если требуется очень точная тренировка. Во многих случаях trainlm способен получить более низкие среднеквадратические ошибки, чем любой из других протестированных алгоритмов. Однако по мере увеличения количества весов в сети преимущество trainlm уменьшается. Кроме того, trainlm производительность относительно низкая при проблемах распознавания образов. Требования к хранению trainlm больше, чем другие проверенные алгоритмы.
trainrp функция является самым быстрым алгоритмом для проблем распознавания образов. Однако он плохо выполняет задачи аппроксимации функций. Его производительность также ухудшается по мере снижения цели ошибки. Требования к памяти для этого алгоритма относительно малы по сравнению с другими рассмотренными алгоритмами.
Алгоритмы сопряженного градиента, в частности trainscg, по-видимому, выполняет более широкий спектр проблем, особенно для сетей с большим количеством весов. Алгоритм SCG почти так же быстр, как алгоритм LM по проблемам аппроксимации функций (быстрее для больших сетей) и почти так же быстр, как trainrp о проблемах распознавания образов. Его производительность снижается не так быстро, как trainrp это происходит, когда ошибка уменьшается. Алгоритмы сопряженного градиента имеют относительно скромные требования к памяти.
Производительность trainbfg аналогичен trainlm. Для этого не требуется столько ресурсов хранения, сколько trainlm, но требуемое вычисление увеличивается геометрически с размером сети, потому что эквивалент обратной матрицы должен вычисляться при каждой итерации.
Алгоритм переменной скорости обучения traingdx обычно гораздо медленнее, чем другие методы, и имеет примерно те же требования к хранению, что и trainrp, но это может быть полезно для некоторых проблем. Есть определенные ситуации, в которых лучше сходиться медленнее. Например, при использовании ранней остановки можно получить противоречивые результаты, если использовать алгоритм, который слишком быстро сходится. Возможно, будет превышена точка минимизации ошибки в наборе проверки.
