На нейроконтроллер, описанный в этом разделе, ссылаются два разных названия: управление линеаризацией обратной связи и управление NARMA-L2. Это называется линеаризацией обратной связи, когда модель растения имеет определенную форму (сопутствующую форму). Это называется NARMA-L2 контролем, когда модель установки может быть аппроксимирована той же формой. Основная идея этого типа управления заключается в преобразовании динамики нелинейной системы в линейную динамику путем отмены нелинейности. Этот раздел начинается с представления модели системы сопутствующей формы и демонстрации того, как можно использовать нейронную сеть для идентификации этой модели. Далее описывается, как идентифицированную модель нейронной сети можно использовать для разработки контроллера. Далее следует пример использования блока NARMA-L2 Control, который содержится в блоке Deep Learning Toolbox™.
Как и в случае модельного прогнозирующего управления, первым шагом в использовании управления линеаризацией (или NARMA-L2) обратной связи является идентификация системы, подлежащей управлению. Вы тренируете нейронную сеть для представления прямой динамики системы. Первым шагом является выбор используемой структуры модели. Одной из стандартных моделей, которая используется для представления общих дискретных временных нелинейных систем, является модель нелинейного авторегрессионного скользящего среднего (NARMA):
k), u (k − 1),..., u (k − n + 1)]
где u (k) - системный вход, а y (k) - системный выход. Для фазы идентификации можно обучить нейронную сеть аппроксимировать нелинейную функцию N. Это процедура идентификации, используемая для NN Predictive Controller.
Если необходимо, чтобы выходные данные системы следовали по некоторой ссылочной траектории
y ( k + d ) = yr (k + d), следующим этапом является разработка нелинейного контроллера в виде:
d), u (k − 1),..., u (k − m + 1)]
Проблема с использованием этого контроллера заключается в том, что если вы хотите обучить нейронную сеть созданию функции G для минимизации среднеквадратической ошибки, необходимо использовать динамическое обратное распространение ([NaPa91] или [HaJe99]). Это может быть довольно медленно. Одним из решений, предложенных Нарендрой и Мухопадхьяем [NaMu97], является использование приближенных моделей для представления системы. Контроллер, используемый в этом разделе, основан на NARMA-L2 приблизительной модели:
k − 1),..., y (k − n + 1), u (k − 1),..., u (k − m + 1)] ⋅u (k
Эта модель имеет форму компаньона, где следующий вход u (k) контроллера не содержится внутри нелинейности. Преимущество этой формы состоит в том, что вы можете решить для управляющего ввода, который приводит к тому, что выходной сигнал системы следует за ссылочным y (k + d) = yr (k + d). Полученный контроллер будет иметь форму
, y (k − 1),..., y (k − n + 1), u (k − 1),..., u (k − n + 1)]
Использование этого уравнения непосредственно может вызвать проблемы реализации, потому что вы должны определить управляющий вход u (k) на основе выходного сигнала одновременно, y (k). Вместо этого используйте модель
k),..., y (k − n + 1), u (k),..., u (k − n + 1)] ⋅u (k + 1)
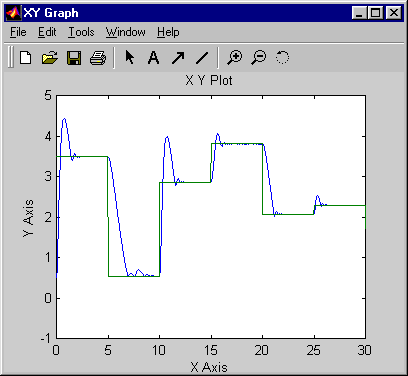
где d ≥ 2. На следующем рисунке показана структура представления нейронной сети.
С помощью модели NARMA-L2 можно получить контроллер
y (k),..., y (k − n + 1), u (k),..., u (k − n + 1)]
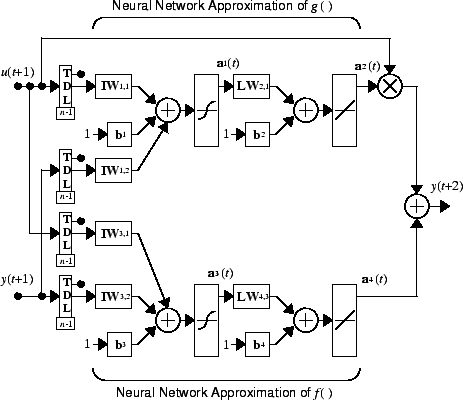
который может быть реализован для d ≥ 2. На следующем рисунке представлена блок-схема контроллера NARMA-L2.
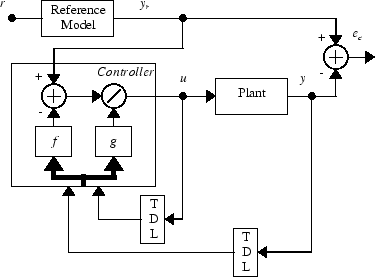
Этот контроллер может быть реализован с предварительно определенной моделью установки NARMA-L2, как показано на следующем рисунке.
В этом разделе показано обучение контроллера NARMA-L2. Первым шагом является копирование блока контроллера NARMA-L2 из библиотеки блоков Deep Learning Toolbox в редактор Simulink ®. Обратитесь к документации Simulink, если вы не знаете, как это сделать. Этот шаг пропускается в следующем примере.
Примерная модель поставляется с программным обеспечением Deep Learning Toolbox для демонстрации использования контроллера NARMA-L2. В этом примере целью является управление положением магнита, подвешенного над электромагнитом, где магнит ограничен так, что он может двигаться только в вертикальном направлении, как на следующем рисунке.
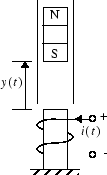
Уравнение движения для этой системы
− βMdy (t) dt
где y (t) - расстояние магнита над электромагнитом, i (t) - ток, протекающий в электромагните, M - масса магнита, g - гравитационная постоянная. Параметр β - коэффициент вязкого трения, который определяется материалом, в котором движется магнит, а α - постоянная напряженности поля, которая определяется числом витков провода на электромагните и прочностью магнита.
Для выполнения этого примера:
Запустите MATLAB ®.
Напечатать narmamaglev в окне команд MATLAB. Эта команда открывает редактор Simulink с помощью следующей модели. Блок управления NARMA-L2 уже находится в модели.
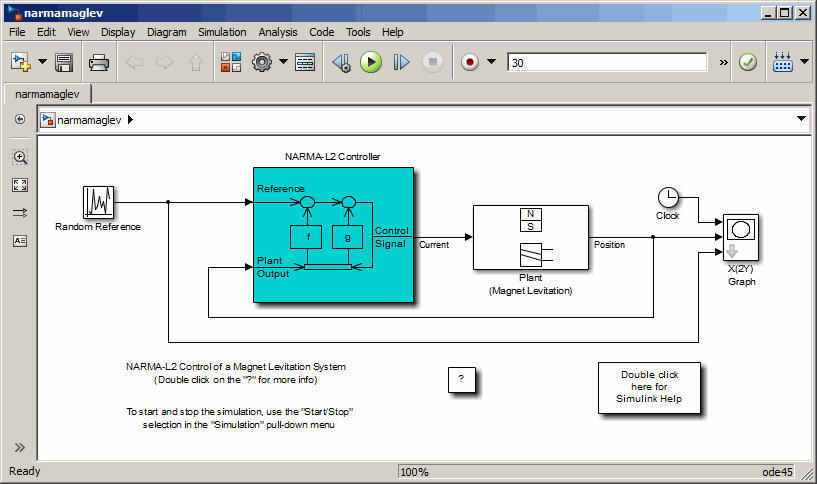
Дважды щелкните на блоке Контроллер NARMA-L2. Откроется следующее окно. Это окно позволяет обучить модель NARMA-L2. Отдельного окна для контроллера нет, потому что контроллер определяется непосредственно из модели, в отличие от прогнозирующего контроллера модели.
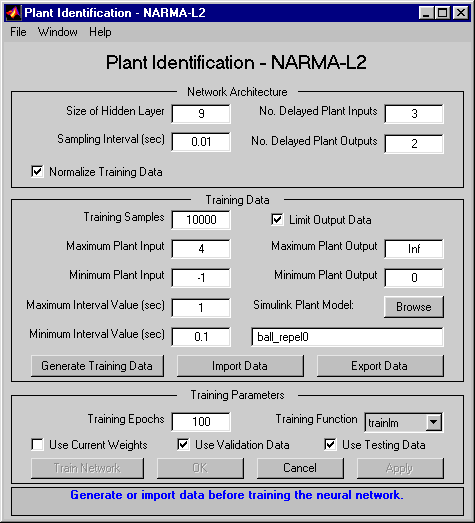
Это окно работает так же, как и другие окна идентификации завода, поэтому процесс обучения не повторяется. Вместо этого смоделируйте контроллер NARMA-L2.
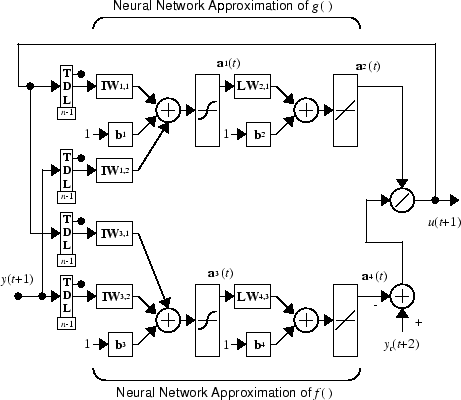
Вернитесь в редактор Simulink и запустите моделирование, выбрав пункт меню Simulation > Run. Во время моделирования отображаются выходные данные завода и опорный сигнал, как показано на следующем рисунке.