Если подсистема в модели настроена на использование домена выполнения потока данных, на панели инструментов Simulink ® активируется вкладка Многоядерный (Multicore). Эта вкладка объединяет многоядерные методы анализа, используемые в потоке данных, в инкрементный и итеративный рабочий процесс .
С помощью элементов управления на вкладке Многоядерные можно выполнять следующие действия:
Оценка относительной стоимости блоков с использованием внутренней эвристики Simulink.
Измерьте среднее время выполнения (стоимость) блоков в подсистемах потока данных путем моделирования модели с помощью профилирования ПО в цикле (SIL) или процессора в цикле (PIL). Для этой функции требуется лицензия Embedded Coder ®.
Переопределите значения затрат блока вручную.
Предоставление ограничений анализа, таких как максимальное количество потоков и пороговое значение многопоточности.
Выполните анализ, чтобы создать выделение блоков потокам и визуализировать результаты анализа.

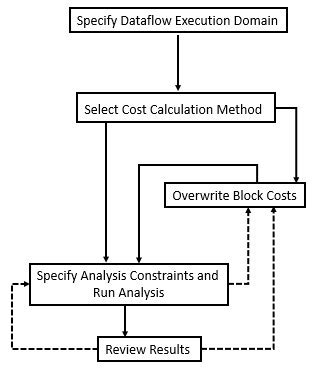
На диаграмме ниже показаны шаги многоядерного анализа. После указания области выполнения потока данных для подсистем в модели можно выбрать метод расчета затрат, перезаписать затраты на блоки, указать ограничения анализа и выполнить анализ, а также просмотреть результаты.
На вкладке Многоядерный (Multicore) в разделе Режим (Mode) можно выбрать метод расчета затрат как Оценка затрат (Cost Estimation) или Профилирование SIL/PIL (SIL/PIL Profiling). В обоих режимах стоимость отдельных блоков будет автоматически определяться и использоваться в многоядерном анализе для равномерного распределения вычислительной нагрузки между несколькими ядрами ЦП.
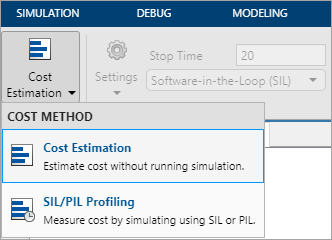
Использовать калькуляцию затрат для:
Быстрый анализ без выполнения моделирования или создания кода.
Предварительный анализ, когда модель не полностью реализована. В этом случае можно изменить результаты оценки в соответствии с ожидаемыми значениями затрат для окончательного внедрения.
Если щелкнуть Оценка затрат (Estimate Cost), Редактор затрат (Cost Editor) отобразит расчетную стоимость выполнения каждого блока в модели без ее моделирования.

Используйте метод профилирования «программное обеспечение в цикле» (SIL) или «процессор в цикле» (PIL) (требуется лицензия Embedded Coder), чтобы:
Получение точных значений затрат, измеренных на хост-компьютере с помощью созданного кода. Созданный код является самым близким к коду, который будет развернут на оборудовании.
Измерьте значения затрат на фактическом целевом оборудовании, чтобы максимизировать использование ядер при развертывании окончательного кода.
Профилирование SIL/PIL измеряет среднее время выполнения (стоимость) блоков в подсистемах потока данных путем моделирования модели с SIL/PIL.
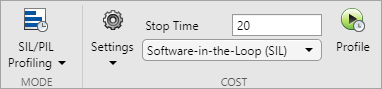
Используйте параметры, чтобы настроить генерацию кода C/C + + и параметры реализации аппаратного обеспечения.
Используйте «Время остановки», чтобы указать время для измерения стоимости.
Используйте раскрывающееся меню для выбора software-in-the-Loop (SIL) или processor-in-the-loop (PIL) установка.
Используйте «Профиль» для измерения затрат, связанных с блоками с указанными параметрами.
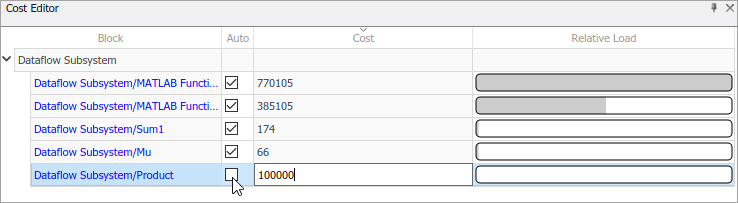
В этом примере показан выделенный блок в модели и его стоимость.

Можно вручную изменить значения стоимости блока, чтобы понять их влияние на поведение многоядерных процессоров. Чтобы переопределить затраты на блоки, снимите флажок в столбце «Авто» для соответствующего блока и отредактируйте значение в столбце «Затраты».
Перезапись значений затрат блока позволяет выполнять анализ пользовательских затрат.
Затем задайте ограничения и выполните многоядерный анализ. В разделе Анализ:

Используйте параметр Максимальное количество потоков (Maximum Number of Threads), чтобы указать максимальное количество потоков, полученных в результате анализа. По умолчанию программа пытается автоматически определить количество ядер целевого процессора по аппаратным настройкам и использует его в качестве максимального количества потоков. Если средство не может определить точное значение, оно будет использовать количество ядер на хост-платформе в качестве максимального количества потоков.
Укажите порог многопоточности, чтобы задать минимальное значение для общей стоимости (в микросекундах) подсистемы, для которой инструмент применяет многопоточность. Если общая стоимость падает ниже порогового значения, сервисная программа не будет разделять подсистему. По умолчанию в качестве порогового значения используется номинальное значение 25 микро- секунд.
Щелкните Выполнить анализ (Run Analysis), чтобы выполнить анализ на основе конфигурации.
Используйте инструменты, представленные в разделе Результаты проверки (Review Results), для визуализации и понимания многоядерного поведения модели.
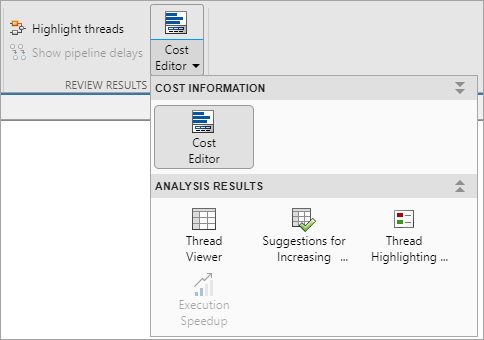
Выберите Подсветить потоки (Highlight threads), чтобы выделить и визуализировать потоки и назначение блоков потокам на основе значений затрат на выполнение блоков.

Выберите Просмотр потоков (Thread Viewer), чтобы визуализировать назначение блоков потокам.
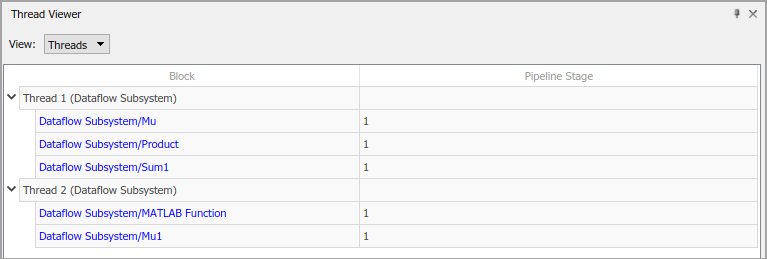
Выберите «Предложения по увеличению параллелизма», чтобы узнать, существуют ли рекомендуемые задержки конвейерной обработки. За счет конвейерной обработки зависимых от данных блоков блок подсистемы потока данных может увеличить параллелизм для более высокой пропускной способности. Дополнительные сведения о задержках конвейера см. в разделе Многоядерное моделирование и создание кода доменов потока данных.

После принятия предложенных задержек для задержки конвейера можно использовать команду Показать задержки конвейера для визуализации задержек в модели.
Используйте функцию Скорость выполнения (Execution Speed), чтобы указать максимальное теоретическое ускорение для всей модели. Это ускорение может быть достигнуто в результате разделения, выполненного во время анализа.
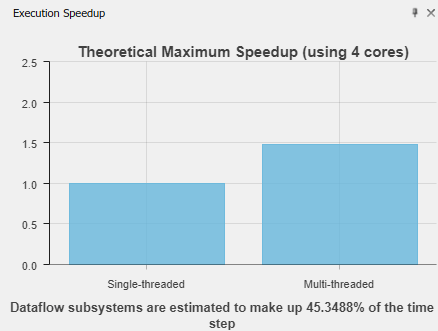
Ускорение вычисляется по этой формуле, где n общее количество блоков подсистемы потока данных, pctPar - процент параллельного выполнения подсистемы, и criticalPathCost - стоимость самого дорогостоящего потока в подсистеме.
+∑i=0npctPari×criticalPathCostitotalCostInSubsystemi
