С помощью технологий Intel AVX и Intel SSE можно генерировать код SIMD (одна команда, несколько данных) из определенных блоков Simulink. SIMD - это вычислительная парадигма, в которой одна команда обрабатывает множество данных. Многие современные процессоры имеют команды SIMD, которые, например, выполняют сразу несколько дополнений или умножений. Для ресурсоемких операций с поддерживаемыми блоками встроенные функции SIMD могут значительно повысить производительность генерируемого кода на платформах Intel.
При выполнении определенных условий можно создать код SIMD с помощью технологии Intel SE или Intel AVX. В этой таблице перечислены блоки, поддерживающие создание кода SIMD. В таблице также приведены условия, при которых доступна поддержка.
| Блок | Условия |
|---|---|
| Добавить |
|
| Вычесть |
|
| Продукт |
|
| Выгода |
|
| Разделиться | Входной сигнал имеет тип данных single или double. |
| Sqrt | Входной сигнал имеет тип данных single или double. |
| Перекрыть |
|
| Пол |
|
| MinMax |
|
| Функция MATLAB | Код MATLAB соответствует условиям, указанным в разделе Создание кода SIMD для функций MATLAB. |
| Для каждой подсистемы |
|
Если у вас есть DSP System Toolbox™, вы также можете генерировать SIMD-код из определенных блоков DSP System Toolbox. Дополнительные сведения см. в разделе Блоки Simulink в панели системных инструментов DSP, поддерживающих создание кода SIMD (панель системных инструментов DSP).
Простая модель simdDemo имеет блок вычитания и блок деления. Блок вычитания имеет входной сигнал, который имеет размерность 240, и входной тип данных single. Блок разделения имеет входной сигнал, который имеет размер 140, и входной тип данных double.
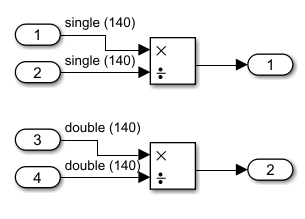
Простой сгенерированный код C для этой модели:
void simdDemo_step(void)
{
int32_T i;
for (i = 0; i < 240; i++) {
simdDemo_Y.Out1[i] = simdDemo_U.In1[i] - simdDemo_U.In2[i];
}
for (i = 0; i < 140; i++) {
simdDemo_Y.Out2[i] = simdDemo_U.In3[i] / simdDemo_U.In4[i];
}
}Создание кода SIMD
Откройте приложение Embedded Coder.
Щелкните Настройки > Реализация оборудования.
Задайте для параметра поставщика устройства значение Intel или AMD.
Задайте для параметра Device type значение x86-64(Windows 64) или x86-64(Linux 64).
На панели «Интерфейс» для параметра Библиотеки замены кода нажмите кнопку Выбрать. В открывшемся диалоговом окне выберите библиотеку Intel AVX или Intel SSE. Выбранная библиотека зависит от того, какое расширение набора команд поддерживает процессор. Для получения дополнительной информации см. https://www.intel.com/content/www/us/en/support/articles/000005779/processors.html. В этой таблице перечислены внутренние команды Intel, которые задаются в каждой библиотеке замены кода:
| Библиотека замены кода | Набор собственных команд Intel |
|---|---|
| Intel SSE | МРЗ, SSE2, SSE4.1 |
| Intel AVX | SSE, SSE2, SSE4.1, AVX, AVX2 |
| AVX-512 Intel | SSE, SSE2, SSE4.1, AVX, AVX2, AVX-512 |
Создайте код из модели.
void simdDemo_step(void)
{
int32_T i;
for (i = 0; i <= 236; i += 4) {
_mm_storeu_ps(&simdDemo_Y.Out1[i], _mm_sub_ps(_mm_loadu_ps(&simdDemo_U.In1[i]),
_mm_loadu_ps(&simdDemo_U.In2[i])));
}
for (i = 0; i <= 138; i += 2) {
_mm_storeu_pd(&simdDemo_Y.Out2[i], _mm_div_pd(_mm_loadu_pd(&simdDemo_U.In3[i]),
_mm_loadu_pd(&simdDemo_U.In4[i])));
}
}
Этот код предназначен для Intel SSE библиотека замены кода. Команды SIMD являются внутренними функциями, которые начинаются с идентификатора _mm. Эти функции обрабатывают несколько данных в одной итерации цикла, поскольку цикл увеличивается на четыре для отдельных типов данных и на два для двойных типов данных. Для моделей, которые обрабатывают больше данных и являются вычислительно более интенсивными, чем эта, наличие команд SIMD может значительно ускорить время выполнения кода.
Список встроенных функций Intel для поддерживаемых блоков Simulink см. в разделе https://software.intel.com/sites/landingpage/IntrinsicsGuide/.
Созданный код не оптимизируется с помощью SIMD, если:
Код в блоке MATLAB Function содержит скалярные типы данных вне тела циклов. Например, если a,b, и c скаляры, сгенерированный код не оптимизирует операцию, такую как c=a+b.
Код в блоке MATLAB Function содержит косвенно индексированные массивы или матрицы. Например, если A,B,C, и D являются векторами, сгенерированный код не векторизируется для такой операции, как D(A)=C(A)+B(A).
Блоки в многоразовой подсистеме могут быть не оптимизированы.
Если код в функциональном блоке MATLAB содержит параллельные циклы for-Loops (parfor), parfor цикл не оптимизирован с помощью SIMD-кода, но закольцовывается в теле parfor цикл можно оптимизировать с помощью SIMD-кода.
