GPU Coder™ также поддерживает концепцию сокращений - важное исключение из правила, согласно которому итерации цикла должны быть независимыми. Понижающая переменная накапливает значение, которое зависит от всех итераций вместе, но не зависит от порядка итераций. Переменные сокращения отображаются на обеих сторонах инструкции назначения, например в суммировании, скалярном произведении и сортировке. В следующем примере показано типичное использование переменной сокращения x:
x = ...; % Some initialization of x for i = 1:n x = x + d(i); end
Переменная x в каждой итерации получает свое значение либо перед входом в цикл, либо из предыдущей итерации цикла. Эта реализация типа последовательного заказа не подходит для параллельного выполнения из-за цепочки зависимостей в последовательном выполнении. Альтернативный подход заключается в использовании подхода, основанного на двоичном дереве.
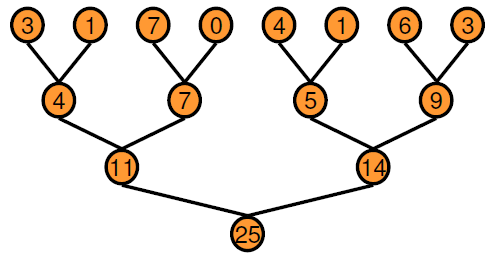
В подходе на основе дерева можно выполнять каждый горизонтальный уровень дерева параллельно в течение определенного количества проходов. По сравнению с последовательным выполнением двоичное дерево требует больше памяти, поскольку для каждого прохода требуется массив временных значений в качестве выходных данных. Преимущества производительности намного перевешивают затраты на увеличение использования памяти. Кодер GPU создает ядра сокращения, используя этот основанный на дереве подход, в котором каждый блок потока уменьшает часть массива. Параллельное сокращение требует частичного обмена данными между блоками потоков. В старых устройствах CUDA ® этот обмен данными был обеспечен с помощью общей памяти и синхронизации потоков. Начиная с архитектуры Kepler GPU, CUDA обеспечивает тасование (shfl) инструкции и быстрые операции с памятью устройства, которые делают сокращение еще быстрее. Ядра редуцирования, создаваемые кодером графического процессора, используют shfl_down команду на уменьшение поперек основы (32 резьбы) нитей. Затем первая нить каждой деформации использует команды атомной операции для обновления уменьшенного значения.
Для получения дополнительной информации об этих инструкциях см. документацию по NVIDIA ®.
В этом примере показано, как создавать ядра типа сокращения CUDA с помощью GPU Coder. Предположим, что требуется создать вектор v вычисляют сумму ее элементов. Этот пример можно реализовать как функцию MATLAB ®.
function s = VecSum(v) s = 0; for i = 1:length(v) s = s + v(i); end end
Кодер GPU не требует специальной прагматики для вывода ядер восстановления. В этом примере используйте coder.gpu.kernelfun pragma для создания ядер восстановления CUDA. Использовать измененное VecSum функция.
function s = VecSum(v) %#codegen s = 0; coder.gpu.kernelfun(); for i = 1:length(v) s = s + v(i); end end
При создании кода CUDA с помощью приложения GPU Coder или из командной строки, GPU Coder создает одно ядро, которое выполняет вычисление векторной суммы. Ниже приведен фрагмент vecSum_kernel1.
static __global__ __launch_bounds__(512, 1) void vecSum_kernel1(const real_T *v,
real_T *s)
{
uint32_T threadId;
uint32_T threadStride;
uint32_T thdBlkId;
uint32_T idx;
real_T tmpRed;
;
;
thdBlkId = (threadIdx.z * blockDim.x * blockDim.y + threadIdx.y * blockDim.x)
+ threadIdx.x;
threadId = ((gridDim.x * gridDim.y * blockIdx.z + gridDim.x * blockIdx.y) +
blockIdx.x) * (blockDim.x * blockDim.y * blockDim.z) + thdBlkId;
threadStride = gridDim.x * blockDim.x * (gridDim.y * blockDim.y) * (gridDim.z *
blockDim.z);
if (!((int32_T)threadId >= 512)) {
tmpRed = 0.0;
for (idx = threadId; threadStride < 0U ? idx >= 511U : idx <= 511U; idx +=
threadStride) {
tmpRed += v[idx];
}
tmpRed = workGroupReduction1(tmpRed, 0.0);
if (thdBlkId == 0U) {
atomicOp1(s, tmpRed);
}
}
}Перед вызовом VecSum_kernel1, два cudaMemcpy вызовы передают вектор v и скаляр s от хоста к устройству. Ядро имеет один блок потоков, содержащий 512 потоков на блок, совместимый с размером входного вектора. Одна треть cudaMemcpy вызов копирует результат вычисления обратно на хост. Ниже приведен фрагмент основной функции.
cudaMemcpy((void *)gpu_v, (void *)v, 4096ULL, cudaMemcpyHostToDevice); cudaMemcpy((void *)gpu_s, (void *)&s, 8ULL, cudaMemcpyHostToDevice); VecSum_kernel1<<<dim3(1U, 1U, 1U), dim3(512U, 1U, 1U)>>>(gpu_v, gpu_s); cudaMemcpy(&s, gpu_s, 8U, cudaMemcpyDeviceToHost);
Примечание
Для повышения производительности кодер GPU отдает приоритет параллельным ядрам по сравнению с сокращениями. Если алгоритм содержит сокращение внутри параллельного цикла, кодер GPU выводит сокращение как обычный цикл и генерирует ядра для него.
Вы можете использовать gpucoder.reduce функция для генерации кода CUDA, который выполняет эффективные операции снижения 1-D на GPU. Генерируемый код использует для реализации операции сокращения особенности тасования CUDA.
Например, чтобы найти sum и max элементы массива A:
function s = myReduce(A)
s = gpucoder.reduce(A, {@mysum, @mymax});
end
function c = mysum(a, b)
c = a+b;
end
function c = mymax(a, b)
c = max(a,b);
endgpucoder.reduce функция имеет следующие требования:
Входные данные должны иметь числовой или логический тип.
Функция, проходящая через @ handle, должна быть двоичной функцией, которая принимает два входа и возвращает один выход. Входы и выходы должны быть одного типа данных.
Функция должна быть коммутативной и ассоциативной.
Примечание
Для некоторых входных данных, относящихся к целочисленному типу данных, код, созданный для gpucoder.reduce функция может содержать промежуточные вычисления, достигающие насыщения. В таких случаях результаты из сгенерированного кода могут не совпадать с результатами моделирования из MATLAB.
coder.gpu.constantMemory | coder.gpu.kernel | coder.gpu.kernelfun | gpucoder.matrixMatrixKernel | gpucoder.reduce | gpucoder.stencilKernel
