Массивы Tall - это мощный и интуитивно понятный способ работы с большими наборами данных с использованием традиционного синтаксиса MATLAB ®. Однако, поскольку массивы tall работают на блоках данных, каждый из которых индивидуально вписывается в память, традиционные алгоритмы большинства функций необходимо обновить, чтобы использовать параллельный подход для поддержки массивов tall. В этом разделе показано, как разработать собственные параллельные алгоритмы для работы с массивами tall.
В настоящее время доступны следующие подходы к применению пользовательских функций к массивам tall:
Одношаговая операция преобразования: применение функции к блокам данных в массиве высокого уровня.
Двухшаговая операция сокращения: Примените функцию к высокому массиву для преобразования содержимого, а затем примените другую функцию для уменьшения выходного сигнала к одному блоку.
Операции со скользящим окном: Примените функцию скользящего окна к массиву высокого уровня для преобразования содержимого.
Независимо от выбранной операции, существуют опции, соображения по производительности и общие проблемы, которые относятся ко всем подходам.
Большинство распространенных математических функций и операций MATLAB уже поддерживают массивы tall. Если функциональность уже поддерживается, то написание собственного алгоритма может не потребоваться.
Вот несколько причин, по которым может потребоваться реализовать пользовательский алгоритм для массивов tall:
Реализация неподдерживаемых в настоящее время функций - если конкретная функция в настоящее время не поддерживает массивы tall, можно использовать описанные здесь API для записи версии этой функции, поддерживающей массивы tall.
Использование существующего кода - если существует код, выполняющий некоторые операции с данными в памяти, то с незначительными изменениями можно сделать его совместимым для работы с массивами tall. Этот подход позволяет избежать необходимости преобразования кода в соответствие с подмножеством языка MATLAB, поддерживающего массивы tall.
Повышение производительности - например, можно переписать функцию MATLAB как функцию C++ MEX, а затем использовать описанные здесь API для вызова функции MEX для работы с данными.
Использовать предпочтительную внешнюю библиотеку (Use a Preferred External Library) - для обеспечения совместимости внутри организации иногда требуется использовать определенную внешнюю библиотеку для определенных вычислений. Описанные здесь API можно использовать для повторного использования функции с этими внешними библиотеками.
Поддерживаемые API предназначены для расширенного использования и не включают расширенную проверку входных данных. Ожидайте потратить некоторое время на тестирование, чтобы реализованные дополнительные функции удовлетворяли всем требованиям и выполняли ожидаемые вычисления. Ниже перечислены поддерживаемые в настоящее время API для разработки алгоритмов массива высокого уровня.
| Имя функции пакета | Описание |
|---|---|
matlab.tall.transform | Примените указанную функцию к каждому блоку одного или нескольких массивов уровня. |
matlab.tall.reduce | Примените указанную функцию к каждому блоку одного или нескольких массивов уровня. Затем подайте выходной сигнал этой функции во вторую функцию уменьшения. |
matlab.tall.movingWindow | Примените функцию движущегося окна к блокам данных. |
matlab.tall.blockMovingWindow | Примените функцию движущегося окна и сокращение блоков к дополненным блокам данных. |
При создании массива высокого уровня из хранилища данных нижележащее хранилище данных облегчает перемещение данных во время вычисления. Данные перемещаются в дискретных фрагментах, называемых блоками, где каждый блок представляет собой набор последовательных строк, которые могут поместиться в памяти. Например, один блок массива 2-D (например, таблица) X(n:m,:). Размер каждого блока основан на значении ReadSize свойство хранилища данных, но блок не всегда имеет такой точный размер. Для целей разработки алгоритмов высокого массива считается, что высокий массив является вертикальной конкатенацией многих таких блоков.
Блоки данного массива выбираются во время выполнения на основе доступной памяти, поэтому они могут быть динамическими. Следовательно, блоки могут иметь не совсем одинаковый размер между ветвями. Если на компьютере есть изменения, влияющие на доступную память, это может повлиять на размер блоков.
Хотя эта страница относится только к блокам и строкам в 2-D смысле, эти понятия распространяются на N-D массивы. Размер блока ограничен только в первом размере, поэтому блок включает все элементы в других размерах; например, X(n:m,:,:,...). Кроме того, вместо строк N-D массивы имеют фрагменты, такие как X(p,:,:,...).
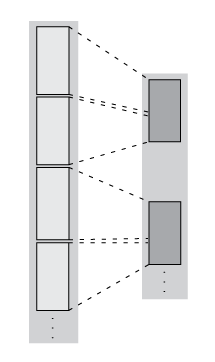
matlab.tall.transform функция применяет одну функцию к каждому блоку массива высокого уровня, поэтому ее можно использовать для применения блочного преобразования, фильтрации или сокращения данных. Например, можно удалить строки с определенными значениями, выполнить центрирование и масштабирование данных или определить определенные условия и преобразовать определенные части данных. Эти рисунки показывают, что происходит с блоками в массиве, когда они обрабатываются matlab.tall.transform.
Операция | Описание | Примеры |
|---|---|---|
| Преобразование - количество строк в каждом блоке остается неизменным, но значения изменяются. |
|
| Фильтрация - количество строк в каждом блоке уменьшается, поэтому блоки в новом массиве могут включать строки, первоначально присутствующие в других блоках. |
|
Общий синтаксис для применения одношагового преобразования:
[tA, tB, tC, ...] = matlab.tall.transform(fcn, tX, tY, tZ, ...)
fcnОбщая функциональная подпись fcn является
[a, b, c, ...] = fcn(x, y, z, ...)
fcn должны удовлетворять этим требованиям:
Входные аргументы - входные данные [x, y, z, ...] представляют собой блоки данных, которые помещаются в память. Блоки создаются путем извлечения данных из соответствующих входных данных массива высокого уровня. [tX, tY, tZ, ...]. Исходные данные [x, y, z, ...] удовлетворяют этим свойствам:
Все из [x, y, z, ...] имеют одинаковый размер в первом измерении после любого разрешенного расширения.
Блоки данных в [x, y, z, ...] происходит из одного и того же индекса в высоком измерении, предполагая, что высокий массив является несинглтоном в высоком измерении. Например, если tX и tY nonsingleton в высоком измерении, то первый набор блоков может быть x = tX(1:20000,:) и y = tY(1:20000,:).
Если первый размер любого из [tX, tY, tZ, ...] имеет размер 1, то соответствующий блок [x, y, z, ...] состоит из всех данных в этом массиве высокого уровня.
Аргументы вывода - выходные данные [a, b, c, ...] являются блоками, которые помещаются в память, для отправки на соответствующие выходы [tA, tB, tC, ...]. Продукция [a, b, c, ...] удовлетворяют этим свойствам:
Все из [a, b, c, ...] должен иметь одинаковый размер в первом измерении.
Все из [a, b, c, ...] связаны по вертикали с соответствующими результатами предыдущих вызовов fcn.
Все из [a, b, c, ...] отправляются в один и тот же индекс в первом измерении в соответствующих выходных массивах назначения.
Функциональные правила - fcn должно удовлетворять функциональному правилу:
F([inputs1; inputs2]) == [F(inputs1); F(inputs2)]Применение функции к конкатенации входов должно быть таким же, как применение функции к входам по отдельности, а затем к конкатенации результатов.
Пустые входы - убедитесь, что fcn может обрабатывать входные данные, высота которых равна 0. Пустые входные данные могут возникать, когда файл пуст или если вы провели большую фильтрацию данных.
matlab.tall.reduce применяет две функции к высокому массиву, при этом результат первого этапа подается в качестве входных данных на заключительный этап уменьшения. Функция уменьшения применяется неоднократно к промежуточным результатам до тех пор, пока не будет получен единственный конечный блок, который умещается в памяти. В парадигме MapReduce этот процесс аналогичен операции MapReduce с одним ключом, где промежуточные результаты имеют один и тот же ключ и объединяются на этапе сокращения.
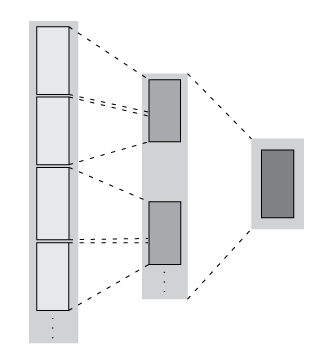
Первый шаг аналогичен matlab.tall.transform и имеет те же требования. Однако этап уменьшения всегда сводит промежуточные результаты к одному блоку, который помещается в память. Эти рисунки показывают, что происходит с блоками в массиве, когда они обрабатываются matlab.tall.reduce.
Операция | Описание | Примеры |
|---|---|---|
| Преобразование + сокращение - количество строк в каждом блоке остается одинаковым после первого шага, а затем промежуточные результаты сводятся к одному блоку. |
|
| Фильтрация + сокращение - количество строк в каждом блоке сокращается на первом шаге. Затем промежуточные результаты сводятся к одному блоку. |
|
Общий синтаксис для применения двухшагового сокращения:
[rA, rB, rC, ...] = matlab.tall.reduce(fcn, reducefcn, tX, tY, tZ, ...)
Функциональная подпись fcn является
[a, b, c, ...] = fcn(x, y, z, ...)
Функциональная подпись reducefcn является
[rA, rB, rC, ...] = reducefcn(a, b, c, ...)
То есть входные массивы tall [tX, tY, tZ, ...] разбиты на блоки [x, y, z, ...] которые являются входами в fcn. Затем, fcn возвращает выходные данные [a, b, c, ...] которые являются входами в reducefcn. Наконец, reducefcn возвращает окончательные результаты [rA, rB, rC] которые возвращаются matlab.tall.reduce.
reducefcnТребования к fcn те же самые, что были изложены в Функциональных требованиях к fcn. Однако требования к reducefcn отличаются друг от друга.
Общая функциональная подпись reducefcn является
[rA, rB, rC, ...] = reducefcn(a, b, c, ...)
reducefcn должны удовлетворять этим требованиям:
Входные аргументы - входные данные [a, b, c, ...] это блоки, которые вписываются в память. Блоки данных являются выходами, возвращаемыми fcn, или частично уменьшенный выход от reducefcn который снова эксплуатируется для дальнейшего сокращения. Исходные данные [a, b, c, ...] удовлетворяют этим свойствам:
Исходные данные [a, b, c, ...] имеют одинаковый размер в первом измерении.
Для данного индекса в первом измерении каждая строка блоков данных [a, b, c, ...] либо исходит от входа, либо исходит от того же самого предыдущего вызова reducefcn.
Для данного индекса в первом измерении каждая строка входных данных [a, b, c, ...] для этого индекса происходит от того же индекса в первом измерении.
Аргументы вывода - все выходы [rA, rB, rC, ...] должен иметь одинаковый размер в первом измерении. Кроме того, они должны быть вертикально сцеплены с соответствующими входами [a, b, c, ...] разрешить повторные сокращения, когда это необходимо.
Функциональные правила - reducefcn должны соответствовать этим функциональным правилам (вплоть до ошибки округления):
F(input) == F(F(input)): Многократное применение функции к одним и тем же входам не должно изменять результат.
F([input1; input2]) == F([input2; input1])Результат не должен зависеть от порядка конкатенации.
F([input1; input2]) == F([F(input1); F(input2)]): Однократное применение функции к конкатенации некоторых промежуточных результатов должно быть таким же, как применение ее отдельно, конкатенация и повторное применение.
Пустые входы - убедитесь, что reducefcn может обрабатывать входные данные, высота которых равна 0. Пустые входные данные могут возникать, когда файл пуст или если вы провели большую фильтрацию данных. Для этого вызова все входные блоки являются пустыми массивами правильного типа и размера в размерах за пределами первого.
matlab.tall.movingWindow и matlab.tall.blockMovingWindow функции применяют функцию к окнам данных в массиве высокого уровня. В то время как matlab.tall.transform и matlab.tall.reduce оперировать целыми блоками данных одновременно, функции движущегося окна оперировать окнами данных по мере перемещения окна от начала к концу массива. Окна могут располагаться между блоками данных, считываемых с диска.
Эти рисунки показывают, что происходит с блоками в массиве, когда они обрабатываются matlab.tall.movingWindow или matlab.tall.blockMovingWindow.
| Операция | Описание | Примеры |
|---|---|---|
|
| Преобразование окон - количество строк в каждом блоке остается неизменным, но значения изменяются. Выходные данные содержат результаты операций, выполненных как над неполными, так и над полными окнами данных. Оба |
|
|
| Фильтрация по окнам - неполные окна данных отбрасываются, поэтому выходные данные содержат меньше элементов, чем входные данные. Выходные данные содержат только результаты операций, выполненных в полных окнах данных. Оба |
|
Вы можете использовать matlab.tall.movingWindow и matlab.tall.blockMovingWindow для применения к данным преобразований или фильтров с окнами. Например, можно вычислить конечное среднее или скользящую медиану или применить к одному окну сразу несколько операций. Эти две функции различаются следующим образом:
matlab.tall.movingWindow применяется fcn ко всем окнам данных, независимо от того, завершены ли окна. matlab.tall.blockMovingWindow применяется windowfcn к неполным окнам данных и применяется blockfcn для заполнения окон данных.
matlab.tall.movingWindow работает на единых окнах данных одновременно. matlab.tall.blockMovingWindow оперирует целыми блоками данных, содержащими несколько полных окон, что уменьшает количество вызовов функций, требуемых при вычислении.
Синтаксис применения операции перемещения окна к одиночным окнам данных:
[tA, tB, tC, ...] = matlab.tall.movingWindow(fcn, window, tX, tY, tZ, ...)
Функциональная подпись fcn должно быть
[a, b, c, ...] = fcn(x, y, z, ...)
Аналогично, синтаксис для применения операции перемещения окна ко всем блокам данных является
[tA, tB, tC, ...] = matlab.tall.blockMovingWindow(windowfcn, blockfcn, window, tX, tY, tZ, ...)
Функциональные подписи windowfcn и blockfcn должно быть
[a, b, c, ...] = windowfcn(info, x, y, z, ...) [a, b, c, ...] = blockfcn(info, bX, bY, bZ, ...)
info input - это структура, содержащая поля Window и Stride. При написании функции. используйте эти поля для выбора окон данных в каждом блоке.
Для описания общих правил, которые fcn, windowfcn, и blockfcn должны следовать, см. Функциональные требования для fcn. Помимо info вход, fcn и windowfcn имеют те же требования. Однако требования к blockfcn отличаются, поскольку эта функция работает на целых блоках данных.
windowfcnОбщая функциональная подпись windowfcn является
[a, b, c, ...] = windowfcn(info, x, y, ...)
info input - это структура, обеспечиваемая matlab.tall.blockMovingWindow которая включает в себя следующие поля:
Stride - Указанный размер шага между окнами (по умолчанию: 1). Задайте это значение с помощью 'Stride' пара имя-значение.
Window - Указанный размер окна. Задайте это значение с помощью window входной аргумент.
windowfcn должны удовлетворять этим требованиям:
Входные аргументы - входные данные [x, y, z, ...] представляют собой блоки данных, которые помещаются в память. Блоки создаются путем извлечения данных из соответствующих входных данных массива высокого уровня. [tX, tY, tZ, ...]. Исходные данные [x, y, z, ...] удовлетворяют этим свойствам:
Все входы [x, y, z, ...] имеют одинаковый размер в первом измерении.
Блоки данных в [x, y, z, ...] происходит из одного и того же индекса в высоком измерении, предполагая, что высокий массив является несинглтоном в высоком измерении. Например, если tX и tY nonsingleton в высоком измерении, то первый набор блоков может быть x = tX(1:20000,:) и y = tY(1:20000,:).
Когда первый размер любого из [tX, tY, tZ, ...] имеет размер 1, соответствующий блок [x, y, z, ...] состоит из всех данных в этом массиве высокого уровня.
Применение windowfcn должно привести к уменьшению входных данных до скаляра или среза массива высотой 1.
Если входные данные являются матрицей, N-D массивом, таблицей или расписанием, применяется windowfcn должно привести к уменьшению входных данных в каждом из столбцов или переменных.
Аргументы вывода - выходные данные [a, b, c, ...] являются блоками, которые помещаются в памяти для отправки на соответствующие выходы [tA, tB, tC, ...]. Продукция [a, b, c, ...] удовлетворяют этим свойствам:
Все выходы [a, b, c, ...] должен иметь одинаковый размер в первом измерении.
Все выходы [a, b, c, ...] связаны по вертикали с соответствующими результатами предыдущих вызовов windowfcn.
Все выходы [a, b, c, ...] отправляются в один и тот же индекс в первом измерении в соответствующих выходных массивах назначения.
Функциональные правила - windowfcn должны удовлетворять этому функциональному правилу:
F([inputs1; inputs2]) == [F(inputs1); F(inputs2)]Применение функции к конкатенации входов должно быть таким же, как применение функции к входам по отдельности, а затем к конкатенации результатов.
blockfcnОбщая функциональная подпись blockfcn является
[a, b, c, ...] = blockfcn(info, bX, bY, bZ, ...)
info input - это структура, обеспечиваемая matlab.tall.blockMovingWindow которая включает в себя следующие поля:
Stride - Указанный размер шага между окнами (по умолчанию: 1). Задайте это значение с помощью 'Stride' пара имя-значение.
Window - Указанный размер окна. Задайте это значение с помощью window входной аргумент.
Блоки данных bX, bY, bZ, ... это matlab.tall.blockMovingWindow обеспечивает blockfcn имеют следующие свойства:
Блоки содержат только полноразмерные окна. blockfcn не обязательно определять поведение для неполных окон данных.
Первое окно данных начинается с первого элемента блока. Последний элемент последнего окна является последним элементом блока.
blockfcn должны удовлетворять этим требованиям:
Входные аргументы - входные данные [bX, bY, bZ, ...] представляют собой блоки данных, которые помещаются в память. Блоки создаются путем извлечения данных из соответствующих входных данных массива высокого уровня. [tX, tY, tZ, ...]. Исходные данные [bX, bY, bZ, ...] удовлетворяют этим свойствам:
Все входы [bX, bY, bZ, ...] имеют одинаковый размер в первом измерении после любого разрешенного расширения.
Блоки данных в [bX, bY, bZ, ...] происходит из одного и того же индекса в высоком измерении, предполагая, что высокий массив является несинглтоном в высоком измерении. Например, если tX и tY nonsingleton в высоком измерении, то первый набор блоков может быть bX = tX(1:20000,:) и bY = tY(1:20000,:).
Если первая размерность любого из входных данных [tX, tY, tZ, ...] имеет размер 1, то соответствующий блок [bX, bY, bZ, ...] состоит из всех данных в этом массиве высокого уровня.
Применение blockfcn должен привести к уменьшению входных данных таким образом, чтобы результат имел высоту, равную количеству окон в блоке. Вы можете использовать info.Window и info.Stride для определения количества окон в блоке.
Если входные данные являются матрицей, N-D массивом, таблицей или расписанием, то применяется blockfcn должно привести к уменьшению входных данных в каждом из столбцов или переменных.
Аргументы вывода - выходные данные [a, b, c, ...] являются блоками, которые помещаются в память, для отправки на соответствующие выходы [tA, tB, tC, ...]. Продукция [a, b, c, ...] удовлетворяют этим свойствам:
Все выходы [a, b, c, ...] должен иметь одинаковый размер в первом измерении.
Все выходы [a, b, c, ...] связаны по вертикали с соответствующими результатами предыдущих вызовов blockfcn.
Все выходы [a, b, c, ...] отправляются в один и тот же индекс в первом измерении в соответствующих выходных массивах назначения.
Функциональные правила - blockfcn должны удовлетворять этому функциональному правилу:
F([inputs1; inputs2]) == [F(inputs1); F(inputs2)]Применение функции к конкатенации входов должно быть таким же, как применение функции к входам по отдельности, а затем к конкатенации результатов.
Если конечный вывод любого из поддерживаемых API имеет тип данных, отличный от входного, необходимо указать 'OutputsLike' пара имя-значение, чтобы предоставить один или несколько массивов прототипов, которые имеют те же тип данных и атрибуты, что и соответствующие выходы. Значение 'OutputsLike' всегда является массивом ячеек, причем каждая ячейка содержит массив прототипа для соответствующего выходного аргумента.
Например, этот вызов matlab.tall.transform принимает один высокий массив tX в качестве входа и возвращает два выхода с различными типами, определенными массивами прототипов protoA и protoB. Продукция A имеет тот же тип данных и атрибуты, что и protoA, и аналогично для B и protoB.
C = {protoA protoB};
[A, B] = matlab.tall.transform(fcn, tX, 'OutputsLike', C)Обычным способом поставки прототипов массивов является вызов fcn с тривиальными входами надлежащего типа данных, так как выходы возвращены fcn имеют правильный тип данных. В этом примере функция преобразования принимает высокий двойник, но возвращает высокую таблицу. Массив прототипа создается путем вызова fcn(0) и прототип указан как значение 'OutputsLike'.
ds = tabularTextDatastore('airlinesmall.csv','TreatAsMissing','NA');
ds.SelectedVariableNames = {'ArrDelay', 'DepDelay'};
tt = tall(ds);
tX = tt.ArrDelay;
fcn = @(x) table(x,'VariableNames',{'MyVar'});
proto_A = fcn(0);
A = matlab.tall.transform(fcn,tX,'OutputsLike',{proto_A});
Поместите всю аналитику в одну функцию, вызываемую для работы непосредственно с данными, вместо использования ненужных вложенных функций.
Эксперимент с использованием небольшого подмножества данных. Профилируйте свой код, чтобы найти и устранить узкие места перед масштабированием до всего набора данных, где узкие места могут быть значительно усилены.
Обратите внимание на ориентацию данных, поскольку некоторые функции возвращают выходные данные в различных формах в зависимости от входных данных. Например, unique может возвращать либо вектор строки, либо вектор столбца в зависимости от ориентации входных данных.
Блоки динамически генерируются во время выполнения на основе доступной памяти компьютера. Убедитесь, что любая указанная функция сокращения соответствует правилу функции F([input1; input2]) == F([F(input1); F(input2)]). Если это правило не соблюдается, то результаты могут значительно отличаться между испытаниями.
Блоки могут иметь любой размер в первом размере, включая 0 или 1. Размер 0 или 1 может возникнуть в промежуточных расчетах в результате операций фильтрации или уменьшения. Убедитесь, что ваша функция правильно подходит для обоих этих случаев. Одним из признаков неправильной обработки этих случаев функцией является сообщение об ошибке «Output is different size».
matlab.tall.blockMovingWindow | matlab.tall.movingWindow | matlab.tall.reduce | matlab.tall.transform