В этом разделе описывается, что такое регулярные выражения и как использовать их для поиска текста. Регулярные выражения являются гибкими и мощными, хотя в них используется сложный синтаксис. Альтернативой регулярным выражениям является pattern (начиная с версии R2020b), что упрощает определение и приводит к более легкому считыванию кода. Дополнительные сведения см. в разделе Создание выражений массива.
Регулярное выражение - это последовательность символов, которая определяет определенный шаблон. Как правило, регулярное выражение используется для поиска текста по группе слов, соответствующих шаблону, например, при анализе входных данных программы или при обработке блока текста.
Вектор символов 'Joh?n\w*' является примером регулярного выражения. Он определяет образец, начинающийся с букв Jo, дополнительно сопровождается буквой h (указывается 'h?'), затем следует буква n, и заканчивается любым количеством символов слова, то есть символов, которые являются буквами, цифрами или подчеркиванием (обозначается '\w*'). Этот шаблон соответствует любому из следующих вариантов:
Jon, John, Jonathan, Johnny
Регулярные выражения предоставляют уникальный способ поиска объема текста для определенного подмножества символов в этом тексте. Вместо поиска точного соответствия символов, как вы бы сделать с функцией, как strfind, регулярные выражения дают возможность искать определенный шаблон символов.
Например, несколько способов выражения метрической скорости скорости:
km/h km/hr km/hour kilometers/hour kilometers per hour
Вы можете найти любой из вышеперечисленных терминов в своем тексте, введя пять отдельных команд поиска:
strfind(text, 'km/h'); strfind(text, 'km/hour'); % etc.
Однако для повышения эффективности можно создать одну фразу, которая применима ко всем этим поисковым терминам:
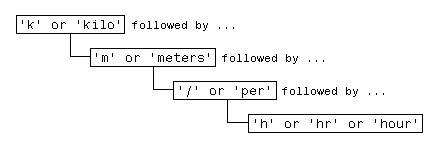
Переведите эту фразу в регулярное выражение (будет объяснено ниже в этом разделе), и у вас есть:
pattern = 'k(ilo)?m(eters)?(/|\sper\s)h(r|our)?';
Теперь найдите один или несколько терминов, используя одну команду:
text = ['The high-speed train traveled at 250 ', ... 'kilometers per hour alongside the automobile ', ... 'travelling at 120 km/h.']; regexp(text, pattern, 'match')
ans =
1×2 cell array
{'kilometers per hour'} {'km/h'}
Существует четыре функции MATLAB ®, которые поддерживают поиск и замену символов с помощью регулярных выражений. Первые три аналогичны по входным значениям, которые они принимают, и выходным значениям, которые они возвращают. Для получения дополнительных сведений щелкните ссылки на страницы ссылок на функции.
| Функция | Описание |
|---|---|
regexp | Соответствие регулярному выражению. |
regexpi | Соответствует регулярному выражению, регистр игнорируется. |
regexprep | Заменить часть текста регулярным выражением. |
regexptranslate | Перевод текста в регулярное выражение. |
При вызове любой из первых трех функций передайте анализируемый текст и регулярное выражение в первых двух входных аргументах. При звонке regexprepпередайте дополнительный ввод, который является выражением, указывающим шаблон для замены.
При использовании регулярных выражений для поиска текста для определенного термина необходимо выполнить три шага:
Определение уникальных шаблонов в строке
Это влечет за собой разделение текста, который требуется найти, на группы одинаковых типов символов. Эти типы символов могут представлять собой ряд строчных букв, знак доллара, за которым следуют три числа, а затем десятичная точка и т.д.
Выражать каждый шаблон как регулярное выражение
Используйте метасимволы и операторы, описанные в этой документации, чтобы выразить каждый сегмент шаблона поиска как регулярное выражение. Затем объедините эти сегменты выражения в одно выражение для использования в поиске.
Вызовите соответствующую функцию поиска
Передача текста, который требуется проанализировать, одной из функций поиска, например: regexp или regexpiили функции замены текста, regexprep.
В примере, показанном в этом разделе, выполняется поиск записи, содержащей контактную информацию, принадлежащую группе из пяти друзей. Эта информация включает имя, номер телефона, место жительства и адрес электронной почты каждого человека. Цель состоит в том, чтобы извлечь конкретную информацию из текста..
contacts = { ...
'Harry 287-625-7315 Columbus, OH hparker@hmail.com'; ...
'Janice 529-882-1759 Fresno, CA jan_stephens@horizon.net'; ...
'Mike 793-136-0975 Richmond, VA sue_and_mike@hmail.net'; ...
'Nadine 648-427-9947 Tampa, FL nadine_berry@horizon.net'; ...
'Jason 697-336-7728 Montrose, CO jason_blake@mymail.com'};
В первой части примера создается регулярное выражение, представляющее формат стандартного адреса электронной почты. С помощью этого выражения в примере выполняется поиск информации по адресу электронной почты одного из друзей. Контактная информация для Дженис находится во 2-й строке contacts массив ячеек:
contacts{2}
ans =
'Janice 529-882-1759 Fresno, CA jan_stephens@horizon.net'
Типичный адрес электронной почты состоит из стандартных компонентов: имя учетной записи пользователя, за которым следует знак @, имя поставщика интернет-услуг пользователя (ISP), точка (точка) и домен, к которому принадлежит ISP. В таблице ниже перечислены эти компоненты в левом столбце и обобщен формат каждого компонента в правом столбце.
| Уникальные шаблоны адреса электронной почты | Общее описание каждого шаблона |
|---|---|
Начать с имени учетной записиjan_stephens . . . | Одна или несколько строчных букв и подчеркиваний |
Добавить '@'jan_stephens@ . . . | @ знак |
Добавление интернет-провайдера jan_stephens@horizon . . . | Одна или несколько строчных букв, без подчеркивания |
Добавить точку (точку)jan_stephens@horizon. . . . | Знак точки (точки) |
Завершить с доменомjan_stephens@horizon.net | com или net |
На этом шаге выполняется перевод общих форматов, полученных на шаге 1, в сегменты регулярного выражения. Затем эти сегменты добавляются вместе для формирования всего выражения.
В таблице ниже приведены обобщенные описания форматов каждого образца символов в крайнем левом столбце. (Это было перенесено из правого столбца таблицы на этапе 1.) Во втором столбце показаны операторы или метасимволы, представляющие образец символа.
| Описание каждого сегмента | Образец |
|---|---|
| Одна или несколько строчных букв и подчеркиваний | [a-z_]+ |
@ знак | @ |
| Одна или несколько строчных букв, без подчеркивания | [a-z]+ |
| Знак точки (точки) | \. |
com или net | (com|net) |
Объединение этих образцов в один символьный вектор дает полное выражение:
email = '[a-z_]+@[a-z]+\.(com|net)';
На этом шаге регулярное выражение, полученное на шаге 2, используется для сопоставления адреса электронной почты одного из друзей в группе. Используйте regexp для выполнения поиска.
Вот список контактной информации, показанный ранее в этом разделе. Запись каждого человека занимает ряд contacts массив ячеек:
contacts = { ...
'Harry 287-625-7315 Columbus, OH hparker@hmail.com'; ...
'Janice 529-882-1759 Fresno, CA jan_stephens@horizon.net'; ...
'Mike 793-136-0975 Richmond, VA sue_and_mike@hmail.net'; ...
'Nadine 648-427-9947 Tampa, FL nadine_berry@horizon.net'; ...
'Jason 697-336-7728 Montrose, CO jason_blake@mymail.com'};
Это регулярное выражение, представляющее адрес электронной почты, полученный на шаге 2:
email = '[a-z_]+@[a-z]+\.(com|net)';
Позвоните в regexp , передавая строку 2 contacts массив ячеек и email регулярное выражение. Это возвращает адрес электронной почты Дженис.
regexp(contacts{2}, email, 'match')
ans =
1×1 cell array
{'jan_stephens@horizon.net'}
MATLAB анализирует вектор символов слева направо, «потребляя» его по мере движения. При обнаружении совпадающих символов regexp записывает местоположение и возобновляет анализ вектора символов, начиная сразу после окончания последнего совпадения.
Сделайте тот же звонок, но на этот раз для пятого человека в списке:
regexp(contacts{5}, email, 'match')
ans =
1×1 cell array
{'jason_blake@mymail.com'}
Можно также выполнить поиск адреса электронной почты всех участников списка, используя весь массив ячеек для входного аргумента:
regexp(contacts, email, 'match');
Регулярные выражения могут содержать символы, метасимволы, операторы, маркеры и флаги, определяющие шаблоны для сопоставления, как описано в следующих разделах:
Метасимволы представляют собой буквы, диапазоны букв, цифры и символы пробела. Используйте их для построения обобщенного образца символов.
Метахарактер | Описание | Пример |
|---|---|---|
| Любой отдельный символ, включая пробел |
|
| Любой символ, заключенный в квадратные скобки. Следующие символы обрабатываются буквально: |
|
| Любой символ, не заключенный в квадратные скобки. Следующие символы обрабатываются буквально: |
|
| Любой символ в диапазоне |
|
| Любой алфавитный, цифровой или символ подчеркивания. Для английских наборов символов, |
|
| Любой символ, не являющийся алфавитным, цифровым или подчеркиванием. Для английских наборов символов, |
|
| Любой символ пробела; эквивалентно |
|
| Любой символ, отличный от пробела; эквивалентно |
|
| Любая цифровая цифра; эквивалентно |
|
| Любой неигрирующий персонаж; эквивалентно |
|
| Символ восьмеричного значения |
|
| Символ шестнадцатеричного значения |
|
Оператор | Описание |
|---|---|
| Аварийный сигнал (звуковой сигнал) |
| Клавиша Backspace |
| Веб-канал формы |
| Новая линия |
| Возврат каретки |
| Горизонтальная вкладка |
| Вертикальная вкладка |
| Любой символ со специальным значением в регулярных выражениях, которые должны совпадать буквально (например, используйте |
Квантификаторы указывают, сколько раз шаблон должен присутствовать в соответствующем тексте.
Квантор | Число выполнений выражения | Пример |
|---|---|---|
| 0 или более раз последовательно. |
|
| 0 раз или 1 раз. |
|
| 1 или более раз последовательно. |
|
| По крайней мере
|
|
| По крайней мере
|
|
| Точно Эквивалентно |
|
Квантователи могут появляться в трех режимах, описанных в следующей таблице. q представляет любой из количественных показателей в предыдущей таблице.
Способ | Описание | Пример |
|---|---|---|
| Жадное выражение: соответствует как можно большему количеству символов. | Учитывая текст |
| Ленивое выражение: соответствует необходимому количеству символов. | Учитывая текст |
| Притяжательное выражение: максимально совпадать, но не повторять какие-либо части текста. | Учитывая текст |
Операторы группировки позволяют захватывать маркеры, применять один оператор к нескольким элементам или отключать обратное отслеживание в определенной группе.
Оператор группировки | Описание | Пример |
|---|---|---|
| Группировка элементов выражения и маркеров захвата. |
|
| Группировать, но не захватывать токены. |
Без группировки, |
| Группировать атомарно. Не выполняйте обратную трассировку внутри группы для завершения сопоставления и не захватывайте токены. |
|
| Выражение соответствия При совпадении с Можно включить |
|
Якоря в выражении соответствуют началу или концу символьного вектора или слова.
Якорь | Соответствует... | Пример |
|---|---|---|
| Начало входного текста. |
|
| Конец входного текста. |
|
| Начало слова. |
|
| Конец слова. |
|
Утверждения lookaround ищут шаблоны, которые непосредственно предшествуют предполагаемому соответствию или следуют за ним, но не являются его частью.
Указатель остается в текущем местоположении, а символы соответствуют test выражения не захватываются и не отбрасываются. Поэтому утверждения lookahead могут совпадать с перекрывающимися группами символов.
Lookaround утверждение | Описание | Пример |
|---|---|---|
| Загляните вперед, чтобы найти совпадающие символы |
|
| Загляните вперед для символов, которые не совпадают |
|
| Искать совпадающие символы |
|
| Искать символы, которые не совпадают |
|
Если перед выражением указать утверждение lookahead, операция эквивалентна логической AND.
Операция | Описание | Пример |
|---|---|---|
| Сопоставить оба |
|
| Матч |
|
Дополнительные сведения см. в разделе Lookahead Assertions in Regular Expressions.
Логические и условные операторы позволяют проверить состояние данного условия, а затем использовать результат, чтобы определить, какой шаблон, если он есть, будет соответствовать следующему. Эти операторы поддерживают логические OR и if или if/else условия. (Для AND условия, см. Lookaround Утверждения.)
Условия могут быть маркерами, проверяемыми утверждениями или динамическими выражениями формы (?@cmd). Динамические выражения должны возвращать логическое или числовое значение.
Условный оператор | Описание | Пример |
|---|---|---|
| Выражение соответствия При совпадении с |
|
| Если условие |
|
| Если условие |
|
Маркеры - это части совпадающего текста, определяемые путем включения части регулярного выражения в круглые скобки. Можно ссылаться на маркер по его последовательности в тексте (порядковый маркер) или назначать имена маркерам для упрощения обслуживания кода и удобочитаемого вывода.
Оператор маркера порядкового номера | Описание | Пример |
|---|---|---|
| Зафиксируйте в маркере символы, соответствующие заключенному выражению. |
|
| Сопоставить |
|
| Если |
|
Оператор именованного маркера | Описание | Пример |
|---|---|---|
| Зафиксируйте в именованном маркере символы, соответствующие заключенному выражению. |
|
| Сопоставить маркер, на который ссылается |
|
| Если именованный токен найден, тогда сопоставьте |
|
Примечание
Если выражение имеет вложенные круглые скобки, MATLAB захватывает маркеры, соответствующие самому внешнему набору круглых скобок. Например, учитывая шаблон поиска '(and(y|rew))', MATLAB создает маркер для 'andrew' но не для 'y' или 'rew'.
Дополнительные сведения см. в разделе Маркеры в регулярных выражениях.
Динамические выражения позволяют выполнять команду MATLAB или регулярное выражение для определения совпадающего текста.
Круглые скобки, содержащие динамические выражения, не создают группу захвата.
Оператор | Описание | Пример |
|---|---|---|
| Разбор При анализе |
|
| Выполните команду MATLAB, представленную |
|
| Выполните команду MATLAB, представленную |
|
В динамических выражениях используйте следующие операторы для определения терминов замены.
Оператор замены | Описание |
|---|---|
| Часть входного текста, которая в настоящее время соответствует |
| Часть входного текста, предшествующая текущему совпадению |
| Часть входного текста, которая следует за текущим совпадением (используйте |
|
|
| Именованный токен |
| Выходные данные, возвращаемые при выполнении команды MATLAB, |
Дополнительные сведения см. в разделе Динамические регулярные выражения.
comment позволяет вставлять комментарии в код, чтобы сделать его более удобным для обслуживания. Текст комментария игнорируется MATLAB при сопоставлении с вводимым текстом.
Персонажи | Описание | Пример |
|---|---|---|
(?#comment) | Вставка комментария в регулярное выражение. Текст комментария игнорируется при совпадении ввода. |
|
Флаги поиска изменяют поведение соответствующих выражений.
Флаг | Описание |
|---|---|
(?-i) | Совпадение буквенного регистра (по умолчанию для |
(?i) | Не соответствовать буквенному регистру (по умолчанию для |
(?s) | Точка совпадения ( |
(?-s) | Сопоставьте точку в шаблоне с любым символом, который не является символом новой строки. |
(?-m) | Сопоставить |
(?m) | Сопоставить |
(?-x) | Включать символы пробела и комментарии при совпадении (по умолчанию). |
(?x) | Игнорировать символы пробела и комментарии при сопоставлении. Использовать |
Выражение, которое изменяет флаг, может появиться после скобок, например
(?i)\w*
или внутри скобок и отделены от флага двоеточием (:), например,
(?i:\w*)
Последний синтаксис позволяет изменить поведение части большего выражения.
pattern | regexp | regexpi | regexprep | regexptranslate
