Двухмерные счетчики Bivariate histogram bin
[ секционирует значения в N,Xedges,Yedges] = histcounts2(X,Y)X и Y в 2-D ячейки и возвращает количество ячеек, а также кромки ячеек в каждом измерении. histcounts2 функция использует алгоритм автоматического объединения, который возвращает однородные ячейки, выбранные для охвата диапазона значений в X и Y и раскрыть основную форму распределения.
[ разделение N,Xedges,Yedges] = histcounts2(X,Y,Xedges,Yedges)X и Y в ячейки с кромками ячеек, указанными Xedges и Yedges.
N(i,j) подсчитывает значение [X(k),Y(k)] если Xedges(i) ≤ X(k) < Xedges(i+1) и Yedges(j) ≤ Y(k) < Yedges(j+1). Последние ячейки в каждом измерении также включают последнее (внешнее) ребро. Например, [X(k),Y(k)] попадает в ith bin в последней строке, если Xedges(end-1) ≤ X(k) ≤ Xedges(end) и Yedges(i) ≤ Y(k) < Yedges(i+1).
[ использует дополнительные параметры, указанные одним или несколькими N,Xedges,Yedges] = histcounts2(___,Name,Value)Name,Value пара аргументов с использованием любого из входных аргументов в предыдущих синтаксисах. Например, можно указать 'BinWidth' и двухэлементный вектор для регулировки ширины ячеек в каждом измерении.
[ также возвращает массивы индексов N,Xedges,Yedges,binX,binY] = histcounts2(___)binX и binY, используя любой из предыдущих синтаксисов. binX и binY массивы того же размера, что и X и Y чьи элементы являются индексами ячейки для соответствующих элементов в X и Y. Количество элементов в (i,j)th bin равен nnz(binX==i & binY==j), что является тем же, что и N(i,j) если Normalization является 'count'.
N - Количество ячеекКоличество ячеек, возвращаемое в виде числового массива.
Схема включения ячеек для различных пронумерованных ячеек в N, а также их относительная ориентация по осям X и Y
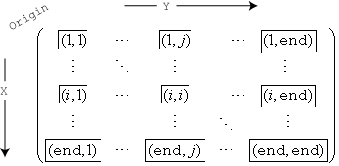
Например, (1,1) ячейка содержит значения, которые попадают на первое ребро в каждом измерении, а последняя ячейка в нижнем правом - на любое из его ребер.
Xedges - Кромки бункера в x-размерностиРебра ячейки в x-размерности, возвращаемые как вектор. Xedges(1) является первым ребром ячейки в x-измерении и Xedges(end) является последним краем ячейки.
Yedges - Кромки бункера в y-размерностиРебра ячейки в размерности y, возвращаемые как вектор. Yedges(1) является первым ребром ячейки в y-измерении и Yedges(end) является последним краем ячейки.
binX - Индекс ячейки в x-измеренииИндекс ячейки в x-измерении, возвращаемый в виде числового массива того же размера, что и X. Соответствующие элементы в binX и binY опишите, какая пронумерованная ячейка содержит соответствующие значения в X и Y. Значение 0 в binX или binY указывает элемент, который не принадлежит ни одному из ячеек (например, NaN значение).
Например, binX(1) и binY(1) опишите размещение ячейки для значения [X(1),Y(1)].
binY - Индекс ячейки в y-измеренииИндекс ячейки в измерении y, возвращаемый в виде числового массива того же размера, что и Y. Соответствующие элементы в binX и binY опишите, какая пронумерованная ячейка содержит соответствующие значения в X и Y. Значение 0 в binX или binY указывает элемент, который не принадлежит ни одному из ячеек (например, NaN значение).
Например, binX(1) и binY(1) опишите размещение ячейки для значения [X(1),Y(1)].
discretize | fewerbins | histcounts | histogram | histogram2 | morebins
