Чтение форматированных данных из текстового файла или строки
C = textscan(fileID,formatSpec)C. Текстовый файл обозначается идентификатором файла, fileID. Использовать fopen чтобы открыть файл и получить fileID значение. По завершении чтения из файла закройте файл, вызвав fclose(fileID).
textscan пытается сопоставить данные в файле со спецификатором преобразования в formatSpec. textscan функция повторно применяется formatSpec по всему файлу и останавливается, когда он не может соответствовать formatSpec к данным.
C = textscan(fileID,formatSpec,N)formatSpec N времена, где N является положительным целым числом. Чтение дополнительных данных из файла после N циклы, вызов textscan снова с использованием оригинала fileID. При возобновлении текстового сканирования файла вызовом textscan с тем же идентификатором файла (fileID), то textscan автоматически возобновляет чтение в момент завершения последнего чтения.
C = textscan(chr,formatSpec)chr в массив ячеек C. При чтении текста из символьного вектора повторные вызовы textscan каждый раз перезапускать сканирование с начала. Чтобы перезапустить сканирование из последней позиции, запросите position выход.
textscan пытается сопоставить данные в символьном векторе chr в формат, указанный в formatSpec.
C = textscan(chr,formatSpec,N)formatSpec N времена, где N является положительным целым числом.
C = textscan(___,Name,Value)Name,Value пара аргументов, в дополнение к любому из входных аргументов в предыдущих синтаксисах.
Считывание символьного вектора, содержащего числа с плавающей запятой.
chr = '0.41 8.24 3.57 6.24 9.27'; C = textscan(chr,'%f');
Спецификатор '%f' в formatSpec говорит textscan для соответствия каждому полю в chr в число с плавающей запятой двойной точности.
Отображение содержимого массива ячеек C.
celldisp(C)
C{1} =
0.4100
8.2400
3.5700
6.2400
9.2700
Считывайте один и тот же символьный вектор и усекайте каждое значение до одной десятичной цифры.
C = textscan(chr,'%3.1f %*1d');Спецификатор %3.1f указывает ширину поля 3 цифры и точность 1. textscan функция считывает 3 цифры, включая десятичную точку и 1 цифру после десятичной точки. спецификатор, %*1d, рассказывает textscan для пропуска оставшейся цифры.
Отображение содержимого массива ячеек C.
celldisp(C)
C{1} =
0.4000
8.2000
3.5000
6.2000
9.2000
Считывание символьного вектора, представляющего набор шестнадцатеричных чисел. Текст, представляющий шестнадцатеричные числа, включает цифры 0-9, буквы a-f или A-F, и, при необходимости, префиксы 0x или 0X.
Сопоставление полей в hexnums для шестнадцатеричных чисел используйте '%x' спецификатор. textscan функция преобразует поля в беззнаковые 64-разрядные целые числа.
hexnums = '0xFF 0x100 0x3C5E A F 10'; C = textscan(hexnums,'%x')
C = 1x1 cell array
{6x1 uint64}
Отображение содержимого C как вектор строки.
transpose(C{:})ans = 1x6 uint64 row vector
255 256 15454 10 15 16
Поля можно преобразовать в целые числа со знаком или без знака, содержащие 8, 16, 32 или 64 бита. Преобразование полей в hexnums чтобы подписать 32-разрядные целые числа, используйте '%xs32' спецификатор.
C = textscan(hexnums,'%xs32');
transpose(C{:})ans = 1x6 int32 row vector
255 256 15454 10 15 16
Можно также указать ширину поля для интерпретации входных данных. В этом случае префикс отсчитывается в сторону ширины поля. Например, если задать ширину поля равной трем, как в %3x, то textscan разделяет текст '0xAF 100' на три части текста, '0xA', 'F', и '100'. Он рассматривает три части текста как различные шестнадцатеричные числа.
C = textscan('0xAF 100','%3x'); transpose(C{:})
ans = 1x3 uint64 row vector
10 15 256
Считывание символьного вектора, представляющего набор двоичных чисел. Текст, представляющий двоичные числа, включает цифры 0 и 1, и, при необходимости, префиксы 0b или 0B.
Сопоставление полей в binnums для двоичных чисел используйте '%b' спецификатор. textscan функция преобразует поля в беззнаковые 64-разрядные целые числа.
binnums = '0b101010 0b11 0b100 1001 10'; C = textscan(binnums,'%b')
C = 1x1 cell array
{5x1 uint64}
Отображение содержимого C как вектор строки.
transpose(C{:})ans = 1x5 uint64 row vector
42 3 4 9 2
Поля можно преобразовать в целые числа со знаком или без знака, содержащие 8, 16, 32 или 64 бита. Преобразование полей в binnums чтобы подписать 32-разрядные целые числа, используйте '%bs32' спецификатор.
C = textscan(binnums,'%bs32');
transpose(C{:})ans = 1x5 int32 row vector
42 3 4 9 2
Можно также указать ширину поля для интерпретации входных данных. В этом случае префикс отсчитывается в сторону ширины поля. Например, если задать ширину поля равной трем, как в %3b, то textscan разделяет текст '0b1010 100' на три части текста, '0b1', '010', и '100'. Он рассматривает три части текста как различные двоичные числа.
C = textscan('0b1010 100','%3b'); transpose(C{:})
ans = 1x3 uint64 row vector
1 2 4
Загрузите файл данных и прочитайте каждый столбец соответствующего типа.
Загрузить файл scan1.dat и предварительный просмотр его содержимого в текстовом редакторе. Ниже показан снимок экрана.
filename = 'scan1.dat';
Откройте файл и прочитайте каждый столбец с соответствующим спецификатором преобразования. textscan возвращает 1-by-9 массив ячеек C.
fileID = fopen(filename); C = textscan(fileID,'%s %s %f32 %d8 %u %f %f %s %f'); fclose(fileID); whos C
Name Size Bytes Class Attributes C 1x9 2105 cell
Просмотр типа данных MATLAB ® для каждой из ячеек вC.
C
C=1×9 cell array
Columns 1 through 5
{3x1 cell} {3x1 cell} {3x1 single} {3x1 int8} {3x1 uint32}
Columns 6 through 9
{3x1 double} {3x1 double} {3x1 cell} {3x1 double}
Проверьте отдельные записи. Обратите внимание, что C{1} и C{2} являются массивами ячеек. C{5} имеет тип данных uint32, так первые два элемента C{5} являются максимальными значениями для 32-разрядное целое число без знака, или intmax('uint32').
celldisp(C)
C{1}{1} =
09/12/2005
C{1}{2} =
10/12/2005
C{1}{3} =
11/12/2005
C{2}{1} =
Level1
C{2}{2} =
Level2
C{2}{3} =
Level3
C{3} =
12.3400
23.5400
34.9000
C{4} =
45
60
12
C{5} =
4294967295
4294967295
200000
C{6} =
Inf
-Inf
10
C{7} =
NaN
0.0010
100.0000
C{8}{1} =
Yes
C{8}{2} =
No
C{8}{3} =
No
C{9} =
5.1000 + 3.0000i
2.2000 - 0.5000i
3.1000 + 0.1000i
Удалить текст литерала 'Level' из каждого поля во втором столбце данных из предыдущего примера. Предварительный просмотр файла показан ниже.

Откройте файл и сопоставьте текст литерала во входном файле formatSpec.
filename = 'scan1.dat'; fileID = fopen(filename); C = textscan(fileID,'%s Level%d %f32 %d8 %u %f %f %s %f'); fclose(fileID); C{2}
ans = 3x1 int32 column vector
1
2
3
Просмотр типа данных MATLAB ® второй ячейки вC. Вторая ячейка 1-by-9 массив ячеек, C, теперь относится к типу данных int32.
disp( class(C{2}) )int32
Прочитайте первый столбец файла в предыдущем примере в массив ячеек, пропустив оставшуюся часть строки.
filename = 'scan1.dat'; fileID = fopen(filename); dates = textscan(fileID,'%s %*[^\n]'); fclose(fileID); dates{1}
ans = 3x1 cell
{'09/12/2005'}
{'10/12/2005'}
{'11/12/2005'}
textscan возвращает даты массива ячеек.
Загрузить файл data.csv и предварительный просмотр его содержимого в текстовом редакторе. Ниже показан снимок экрана. Обратите внимание, что файл содержит данные, разделенные запятыми, а также пустые значения.
![]()
Чтение файла, преобразование пустых ячеек в -Inf.
filename = 'data.csv'; fileID = fopen(filename); C = textscan(fileID,'%f %f %f %f %u8 %f',... 'Delimiter',',','EmptyValue',-Inf); fclose(fileID); column4 = C{4}, column5 = C{5}
column4 = 2×1
4
-Inf
column5 = 2x1 uint8 column vector
0
11
textscan возвращает 1-by-6 массив ячеек, C. textscan функция преобразует пустое значение в C{4} кому -Inf, где C{4} связан с форматом с плавающей запятой. Поскольку MATLAB ® представляет целое число без знака-Inf как 0, textscan преобразует пустое значение в C{5} кому 0, а не -Inf.
Загрузить файл data2.csv и предварительный просмотр его содержимого в текстовом редакторе. Ниже показан снимок экрана. Обратите внимание, что файл содержит данные, которые можно интерпретировать как комментарии и другие записи, такие как 'NA' или 'na' которые могут указывать на пустые поля.
filename = 'data2.csv';![]()
Обозначить входные данные, которые textscan следует рассматривать как комментарии или пустые значения и сканировать данные в C.
fileID = fopen(filename); C = textscan(fileID,'%s %n %n %n %n','Delimiter',',',... 'TreatAsEmpty',{'NA','na'},'CommentStyle','//'); fclose(fileID);
Просмотрите выходные данные.
celldisp(C)
C{1}{1} =
abc
C{1}{2} =
def
C{2} =
2
NaN
C{3} =
NaN
5
C{4} =
3
6
C{5} =
4
7
Загрузить файл data3.csv и предварительный просмотр его содержимого в текстовом редакторе. Ниже показан снимок экрана. Обратите внимание, что файл содержит повторяющиеся разделители.
filename = 'data3.csv';
Чтобы рассматривать повторяющиеся запятые как единый разделитель, используйте MultipleDelimsAsOne и задайте значение 1 (true).
fileID = fopen(filename); C = textscan(fileID,'%f %f %f %f','Delimiter',',',... 'MultipleDelimsAsOne',1); fclose(fileID); celldisp(C)
C{1} =
1
5
C{2} =
2
6
C{3} =
3
7
C{4} =
4
8
Загрузить файл данных grades.txt для этого примера и предварительный просмотр его содержимого в текстовом редакторе. Ниже показан снимок экрана. Обратите внимание, что файл содержит повторяющиеся разделители.
filename = 'grades.txt';
Считывание заголовков столбцов с использованием формата '%s' четыре раза.
fileID = fopen(filename); formatSpec = '%s'; N = 4; C_text = textscan(fileID,formatSpec,N,'Delimiter','|');
Прочитайте числовые данные в файле.
C_data0 = textscan(fileID,'%d %f %f %f')C_data0=1×4 cell array
{4x1 int32} {4x1 double} {4x1 double} {4x1 double}
Значение по умолчанию для CollectOutput является 0 (false), так textscan возвращает каждый столбец числовых данных в отдельном массиве.
Установите индикатор положения файла в начало файла.
frewind(fileID);
Перечитайте файл и установите для параметра CollectOutput значение 1 (true), чтобы собрать последовательные столбцы одного класса в один массив. Вы можете использовать repmat , чтобы указать, что %f спецификатор преобразования должен отображаться три раза. Этот метод полезен при многократном повторении формата.
C_text = textscan(fileID,'%s',N,'Delimiter','|'); C_data1 = textscan(fileID,['%d',repmat('%f',[1,3])],'CollectOutput',1)
C_data1=1×2 cell array
{4x1 int32} {4x3 double}
Результаты теста, которые являются двойными, собираются в один массив 4 на 3.
Закройте файл.
fclose(fileID);
Считывание первого и последнего столбцов данных из текстового файла. Пропустить столбец текста и столбец целочисленных данных.
Загрузить файл names.txt и предварительный просмотр его содержимого в текстовом редакторе. Ниже показан снимок экрана. Обратите внимание, что файл содержит два столбца текста в кавычках, за которыми следует столбец целых чисел и, наконец, столбец чисел с плавающей запятой.
filename = 'names.txt';
Прочитайте первый и последний столбцы данных в файле. Используйте спецификатор преобразования, %q для чтения текста, заключенного в двойные кавычки ("). %*q пропускает текст в кавычках, %*d пропускает целочисленное поле и %f считывает число с плавающей запятой. Укажите разделитель запятой с помощью 'Delimiter' аргумент пары имя-значение.
fileID = fopen(filename,'r'); C = textscan(fileID,'%q %*q %*d %f','Delimiter',','); fclose(fileID);
Просмотрите выходные данные. textscan возвращает массив ячеек C при удалении двойных кавычек с текстом.
celldisp(C)
C{1}{1} =
Smith, J.
C{1}{2} =
Bates, G.
C{1}{3} =
Curie, M.
C{1}{4} =
Murray, G.
C{1}{5} =
Brown, K.
C{2} =
71.1000
69.3000
64.1000
133.0000
64.9000
Загрузить файл german_dates.txt и предварительный просмотр его содержимого в текстовом редакторе. Ниже показан снимок экрана. Обратите внимание, что первый столбец значений содержит даты на немецком языке, а второй и третий столбцы являются числовыми значениями.
filename = 'german_dates.txt';
Откройте файл. Укажите схему кодирования символов, связанную с файлом, в качестве последнего ввода в fopen.
fileID = fopen(filename,'r','n','ISO-8859-15');
Прочитайте файл. Укажите формат дат в файле с помощью %{dd % MMMM yyyy}D спецификатор. Укажите языковой стандарт дат с помощью DateLocale аргумент пары имя-значение.
C = textscan(fileID,'%{dd MMMM yyyy}D %f %f',... 'DateLocale','de_DE','Delimiter',','); fclose(fileID);
Просмотр содержимого первой ячейки C. Даты, отображаемые на языке MATLAB, используются в зависимости от языка системы.
C{1}ans = 3x1 datetime
01 January 2014
01 February 2014
01 March 2014
Использовать sprintf для преобразования не используемых по умолчанию escape-последовательностей в данные.
Создание текста, содержащего символ канала формы. \f. Затем, чтобы прочитать текст с помощью textscan, звонок sprintf для явного преобразования веб-канала формы.
lyric = sprintf('Blackbird\fsinging\fin\fthe\fdead\fof\fnight'); C = textscan(lyric,'%s','delimiter',sprintf('\f')); C{1}
ans = 7x1 cell
{'Blackbird'}
{'singing' }
{'in' }
{'the' }
{'dead' }
{'of' }
{'night' }
textscan возвращает массив ячеек, C.
Возобновите сканирование с позиции, отличной от начальной.
Если вы возобновите сканирование текста, textscan читает с начала каждый раз. Чтобы возобновить сканирование из любой другой позиции, используйте синтаксис аргумента с двумя выходами в первом вызове textscan.
Например, создайте вектор символов с именем lyric. Прочитайте первое слово символьного вектора, а затем возобновите сканирование.
lyric = 'Blackbird singing in the dead of night'; [firstword,pos] = textscan(lyric,'%9c',1); lastpart = textscan(lyric(pos+1:end),'%s');
fileID - Идентификатор файлаИдентификатор открытого текстового файла, указанный как число. Перед чтением файла с помощью textscan, вы должны использовать fopen чтобы открыть файл и получить fileID.
Типы данных: double
formatSpec - Формат полей данныхФормат полей данных, указанный как символьный вектор или строка одного или нескольких спецификаторов преобразования. Когда textscan считывает входные данные, пытается сопоставить данные с форматом, указанным в formatSpec. Если textscan не соответствует полю данных, оно прекращает чтение и возвращает все поля, считанные до сбоя.
Количество спецификаторов преобразования определяет количество ячеек в выходном массиве, C.
Числовые поля
В этой таблице перечислены доступные спецификаторы преобразования для числовых входных данных.
| Тип числового ввода | Спецификатор преобразования | Класс вывода |
|---|---|---|
| Целое число, с подписью | %d | int32 |
%d8 | int8 | |
%d16 | int16 | |
%d32 | int32 | |
%d64 | int64 | |
| Целое число, без знака | %u | uint32 |
%u8 | uint8 | |
%u16 | uint16 | |
%u32 | uint32 | |
%u64 | uint64 | |
| Число с плавающей запятой | %f | double |
%f32 | single | |
%f64 | double | |
%n | double | |
| Шестнадцатеричное число, целое число без знака | %x | uint64 |
%xu8 | uint8 | |
%xu16 | uint16 | |
%xu32 | uint32 | |
%xu64 | uint64 | |
| Шестнадцатеричное число, целое число со знаком | %xs8 | int8 |
%xs16 | int16 | |
%xs32 | int32 | |
%xs64 | int64 | |
| Двоичное число, целое число без знака | %b | uint64 |
%bu8 | uint8 | |
%bu16 | uint16 | |
%bu32 | uint32 | |
%bu64 | uint64 | |
| Двоичное число, целое число со знаком | %bs8 | int8 |
%bs16 | int16 | |
%bs32 | int32 | |
%bs64 | int64 |
Нечисловые поля
В этой таблице перечислены доступные спецификаторы преобразования для входных данных, содержащих нечисловые символы.
| Нечисловой тип ввода | Спецификатор преобразования | Подробнее |
|---|---|---|
| Характер | %c | Считывание любого отдельного символа, включая разделитель. |
| Текстовый массив | %s | Считывается как массив ячеек символьных векторов. |
%q | Считывается как массив ячеек символьных векторов. Если текст начинается с двойной кавычки ( Пример: | |
| Даты и время | %D | Читать так же, как |
%{ | Читать так же, как Дополнительные сведения о форматах отображения datetime см. в разделе Пример: | |
| Продолжительность | %T |
Читать так же, как |
%{ | Читать так же, как Дополнительные сведения о форматах отображения длительности см. в разделе Пример: | |
| Категория | %C | Читать так же, как |
| Сопоставление шаблонов | %[...] | Считывайте как массив ячеек векторов символов, символы внутри скобок вплоть до первого несопоставимого символа. Включать Пример: |
%[^...] | Исключите символы внутри скобок, читая до первого совпадающего символа. Исключить Пример: |
Дополнительные операторы
Спецификаторы преобразования в formatSpec могут включать необязательные операторы, которые отображаются в следующем порядке (включают пробелы для ясности):
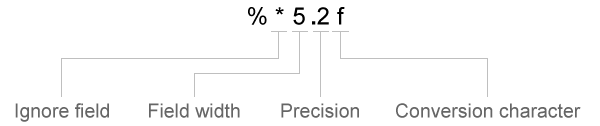
К дополнительным операторам относятся:
Игнорируемые поля и символы
textscan считывает все символы в файле в последовательности, если не указано игнорировать определенное поле или часть поля.
Вставьте символ звездочки (*) после символа процента (%), чтобы пропустить поле или часть символьного поля.
Оператор | Принятые меры |
|---|---|
%* | Пропустите поле. Пример: |
'%* | Пропустить до Пример: |
'%* | Пропустить |
Ширина поля
textscan считывает число символов или цифр, заданное шириной поля или точностью, или до первого разделителя, в зависимости от того, что наступит раньше. Десятичная точка, знак (+ или -), символ экспоненты и цифры в числовой экспоненте считаются символами и цифрами в пределах ширины поля. Для комплексных чисел ширина поля относится к индивидуальной ширине действительной части и мнимой части. Для мнимой части ширина поля включает + или − но не включает i или j. Укажите ширину поля, вставив число после символа процента (%) в спецификаторе преобразования.
Пример: %5f читает '123.456' как 123.4.
Пример: %5c читает 'abcdefg' как 'abcde'.
При использовании оператора ширины поля с одиночными символами (%c), textscan также считывает символы разделителя, пробела и конца строки.
Пример: %7c читает 7 символов, включая пробел, поэтому'Day and night' читает как 'Day and'.
Точность
Для чисел с плавающей запятой (%n, %f, %f32, %f64), можно указать количество читаемых десятичных цифр.
Пример: %7.2f читает '123.456' как 123.45.
Пропускаемый текст литерала
textscan игнорирует текст, добавленный к formatSpec спецификатор преобразования.
Пример: Level%u8 читает 'Level1' как 1.
Пример: %u8Step читает '2Step' как 2.
Типы данных: char | string
N - Количество случаев применения formatSpecInf (по умолчанию) | положительное целое числоКоличество применений formatSpec, указано как положительное целое число.
Типы данных: single | double | int8 | int16 | int32 | int64 | uint8 | uint16 | uint32 | uint64
chr - Входной текстВведите текст для чтения.
Типы данных: char | string
Укажите дополнительные пары, разделенные запятыми Name,Value аргументы. Name является именем аргумента и Value - соответствующее значение. Name должен отображаться внутри кавычек. Можно указать несколько аргументов пары имен и значений в любом порядке как Name1,Value1,...,NameN,ValueN.
C = textscan(fileID,formatSpec,'HeaderLines',3,'Delimiter',',') пропускает первые три строки данных, а затем считывает оставшиеся данные, рассматривая запятые как разделитель.Имена не чувствительны к регистру.
textscan преобразует числовые поля в указанный тип вывода в соответствии с правилами MATLAB, касающимися переполнения, усечения и использования NaN, Inf, и -Inf. Например, MATLAB представляет целое число NaN как ноль. Если textscan находит пустое поле, связанное со спецификатором целочисленного формата (например, %d или %u), он возвращает пустое значение как ноль, а не NaN.
При сопоставлении данных со спецификатором преобразования текста textscan считывает до тех пор, пока не найдет разделитель или символ конца строки. При сопоставлении данных со спецификатором числового преобразования textscan читает, пока не найдет нечисловой символ. Когда textscan больше не может сопоставлять данные с определенным спецификатором преобразования, он пытается сопоставить данные со следующим спецификатором преобразования в formatSpec. Знак (+ или -), символы экспоненты и десятичные точки считаются числовыми символами.
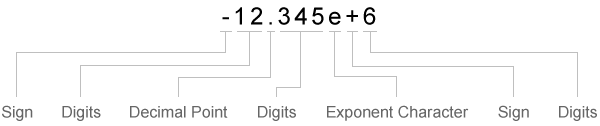
| Знак | Цифры | Десятичная точка | Цифры | Символ экспоненты | Знак | Цифры |
|---|---|---|---|---|---|---|
| Прочитайте один знак, если он существует. | Прочитайте одну или несколько цифр. | Считывайте одну десятичную точку, если она существует. | Если есть десятичная точка, прочитайте одну или несколько цифр, которые сразу следуют за ней. | Прочитайте один символ экспоненты, если он существует. | При наличии символа экспоненты прочитайте один символ знака. | При наличии символа экспоненты прочитайте одну или несколько цифр, следующих за ним. |
textscan импортирует любое комплексное число в целом в комплексное числовое поле, преобразуя действительную и мнимую части в указанный числовой тип (например, %d или %f). Допустимыми формами для комплексного номера являются:
±<real>±<imag>i|j | Пример: |
±<imag>i|j | Пример: |
Не включайте встроенный пробел в комплексное число. textscan интерпретирует внедренное пустое пространство как разделитель поля.
