Для эмпирического моделирования двигателя в браузере модели сначала загрузите, обработайте и выберите данные для моделирования. В этом учебном пособии показано, как использовать редактор данных для загрузки данных, создания переменных и создания ограничений для этих данных.
Данные можно загружать из файлов (файлов Microsoft ® Excel ®, файлов MATLAB ®, текстовых файлов) и из рабочей области MATLAB. Для создания нового набора данных можно объединить данные в любой из этих форм с ранее загруженными наборами данных. Планы тестирования могут использовать только один набор данных, поэтому функция объединения позволяет объединять записи и переменные из различных файлов в одной модели.
Можно определить новые переменные, применить фильтры для удаления нежелательных данных и применить примечания к фильтруемым тестам. Можно сохранять и извлекать эти пользовательские переменные и фильтры для любого набора данных, а также можно сохранять параметры печати. Можно изменять и добавлять записи и применять группы тестов, а также сопоставлять данные с конструкциями. Также можно записать собственные функции загрузки данных.
Чтобы начать работу, выполните следующие действия.
Шаги рабочего процесса | Описание |
|---|---|
Используйте окно «Редактор данных» для исследования данных. | |
Определите собственные новые переменные и фильтры для удаления нежелательных данных. | |
Сохранение настроек печати, пользовательских переменных, фильтров и заметок к тестам. | |
Для группирования данных используется диалоговое окно Define Test Groupings. | |
Пример проекта для сопоставления экспериментальных данных с проектами. |
Можно разделить виды для отображения сразу нескольких графиков. Используйте контекстные меню, кнопки панели инструментов или меню «Вид» для разделения видов. Можно выбрать 2-D графики, 3-D графики, несколько графиков данных, таблицы данных и вкладки, показывающие сводку, статистику, переменные, фильтры, тестовые фильтры и примечания к тестам. Примечания к тесту можно использовать для изучения данных о проблемах и принятия решения об удалении некоторых точек перед моделированием.
Щелкните правой кнопкой мыши вид и выберите «Текущий вид» > «Печать нескольких данных».
Щелкните правой кнопкой мыши на новом виде и выберите «Добавить печать».
Откроется диалоговое окно Настройка переменных печати (Plot Variables Setup).
Выбрать spark и щелкните, чтобы добавить к X Variable , затем выберите tq и щелкните, чтобы добавить к Y Variable коробка. Нажмите кнопку ОК, чтобы создать график.
Щелкните в списке «Тесты», чтобы выбрать тест для печати (или щелкните, удерживая нажатой клавишу Shift, клавишу Ctrl или щелкните и перетащите для выбора нескольких тестов).
Выберите Сервис > Тестовые примечания.
В редакторе тестовых заметок введите mean(tq)<10 в верхнем поле редактирования для определения тестов, которые необходимо отметить, и введите Low torque в поле редактирования Test Note. Оставьте цвет заметки по умолчанию и нажмите кнопку ОК.
Перейдите на вкладку «Тестовые примечания» для просмотра определения заметки.
На панели выбора тестов слева обратите внимание, что все тесты, удовлетворяющие условию mean(tq)<10 показать Low torque рядом с ними. Щелкните заголовок столбца, чтобы отсортировать тесты, удовлетворяющие условию заметки, по верхнему или нижнему краю списка.
Теперь создайте больше видов.
Щелкните правой кнопкой мыши вид и выберите «Разделить вид» > «Таблица данных».
Щелкните правой кнопкой мыши по представлению и выберите Представление Разделения> 3D Сюжет.
На панели «Выбор тестов» выберите определенные тесты с помощью Low torque примечание.
Обратите внимание, что при выборе теста один и тот же тест отображается на нескольких графиках данных, 3D графике данных и подсвечивается в таблице данных. Таким образом можно использовать примечания для простого определения проблемных тестов и принятия решения об их удалении.
Щелкните точку в представлении «Несколько графиков данных».
Точка выделена красным цветом на графике и выделена в таблице данных. Для удаления точек, выбранных в качестве отклонений, выберите «Сервис» > «Удалить данные» (или используйте сочетание клавиш Ctrl + A). Выберите «Сервис» > «Восстановить данные» (или используйте сочетание клавиш Ctrl + Z), чтобы открыть диалоговое окно, в котором можно восстановить любую или все удаленные точки.
Отдельные точки можно удалить как отклонения или удалить записи или все тесты с помощью фильтров.
Например, после проверки всех Low torque отмеченные тесты, вы можете решить отфильтровать их.
Выберите «Сервис» > «Тестовые фильтры».
В редакторе тестовых фильтров введите mean(tq)>10 чтобы сохранить все тесты, в которых средний крутящий момент больше 10, и нажмите кнопку ОК.
Перейдите на вкладку Test Filters и просмотрите новые результаты тестирования, показывающие, что он успешно применен и количество записей удалено.
Чтобы просмотреть удаленные данные в табличном представлении, щелкните правой кнопкой мыши и выберите Разрешить правку. Удаленные записи имеют красный цвет. Для просмотра удаленных данных на 2-D и нескольких графиках данных выберите Свойства (Properties) и установите флажок Показать удаленные данные (Show removed data).
Чтобы изменить отображение, щелкните правой кнопкой мыши 2-D график и выберите «Свойства». Можно изменить параметры сетки и печати, включая линии, для соединения точек данных.
Изменение порядка данных X в диалоговом окне «Свойства печати» может быть полезным, если порядок записи не создает разумную линию, соединяющую точки данных. Для иллюстрации этого:
Убедитесь, что отображается 2-D график. Можно щелкнуть правой кнопкой мыши на любом графике и выбрать «Текущий график» > «2-D график» или использовать команды разделения контекстного меню для добавления новых видов.
Щелкните правой кнопкой мыши на 2-D графике и выберите «Свойства». solid из раскрывающегося меню «Данные в стиле». Нажмите кнопку ОК.
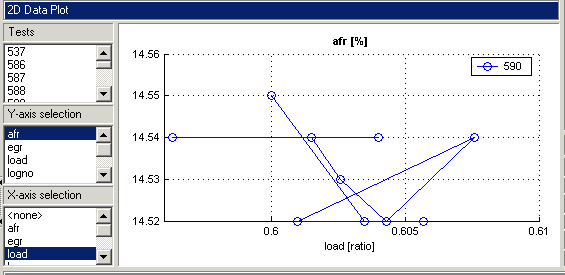
Выбирать afr для оси Y.
Выбирать Load для оси X.
Выберите тест 590. Используйте контрольные элементы, содержащиеся на графике 2-D. Панель Тесты (Tests) слева применяется к другим представлениям: таблицам и 3-D и нескольким графикам данных.
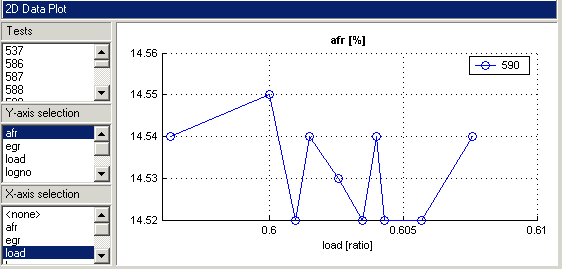
Щелкните правой кнопкой мыши и выберите Свойства и выберите Переупорядочить данные X. Нажмите кнопку ОК.
Эта команда выполняет репликацию строки слева направо, а не в порядке следования записей, как показано на рисунке.
Щелкните правой кнопкой мыши и выберите «Разделить график» > «Таблица данных», чтобы разделить выбранное представление и добавить табличное представление. Конкретные номера тестов можно выбрать на панели «Тесты» слева от редактора данных. Можно щелкнуть правой кнопкой мыши, чтобы выбрать «Разрешить редактирование», а затем дважды щелкнуть ячейки, чтобы изменить их.
В набор данных можно добавить новые переменные.
Выберите «Сервис» > «Переменные» или нажмите кнопку на панели инструментов.
В редакторе переменных можно определить новые переменные в терминах существующих переменных. Определите новую переменную, записав уравнение в поле редактирования вверху.
Определение новой переменной с именем POWER которая определяется как произведение двух существующих переменных, tq и n, путем ввода POWER=tq*n, как видно из следующего примера. Можно также дважды щелкнуть имена переменных и операторы, чтобы добавить их, что может быть полезно, чтобы избежать ошибок ввода имен переменных, которые должны быть точными, включая регистр.
Нажмите кнопку ОК, чтобы добавить эту переменную в текущий набор данных.
Просмотрите новую переменную в редакторе данных на вкладке Переменные вверху. Теперь вы также можете видеть 7 + 1 variables на вкладке сводки.
Фильтр является ограничением набора данных, который можно использовать для исключения некоторых записей. Для создания фильтров используется редактор фильтров.
Выберите меню «Сервис» > «Фильтры» или нажмите кнопку на панели инструментов.
В редакторе фильтров определите фильтр с помощью логических операторов для существующих переменных.
Вести все записи со скоростью (n) более 1000. Напечатать n (или дважды щелкните переменную n), затем введите >1000.
Нажмите кнопку ОК, чтобы применить этот фильтр к текущему набору данных.
Просмотрите новый фильтр в редакторе данных на вкладке «Фильтры» вверху. Здесь можно просмотреть список пользовательских фильтров и количество записей, удаляемых новым фильтром. Теперь вы также можете видеть 141/270 records на вкладке сводки и в красной области строки, иллюстрирующей записи, удаляемые фильтром.
Порядок пользовательских переменных в списке редактора переменных можно изменить с помощью кнопок со стрелками вверх и вниз.
Выберите «Сервис» > «Переменные».
Пример:
Определите две новые переменные, New1 и New2. С помощью кнопок можно добавить или удалить элемент списка для создания или удаления переменных в этом представлении. Нажмите кнопку «Добавить элемент», чтобы добавить переменную, и введите представленные определения.
Обратите внимание, что New2 определяется в терминах New1. Новые переменные добавляются к данным по очереди и, следовательно, New1 должен появиться в списке до New2, в противном случае New2 не имеет четкого определения.
Измените порядок, щелкнув стрелку вниз в редакторе переменных, чтобы создать эту ошибочную ситуацию. Нажмите кнопку «ОК», чтобы вернуться в редактор данных, и на вкладке «Переменные» появится сообщение об ошибке, указывающее на наличие проблемы с переменной.
Используйте стрелки, чтобы упорядочить пользовательские переменные в допустимой последовательности.
Можно удалить пользовательские переменные и фильтры.
Пример:
Удаление добавленной переменной New1выберите его на вкладке Переменные и нажмите клавишу Удалить.
Можно также удалить переменные в редакторе переменных, нажав кнопку «Удалить элемент».
Аналогичным образом можно удалить фильтры, выбрав нежелательный фильтр на вкладке Фильтры (Filters) и используя клавишу Удалить (Delete).
Можно сохранять и импортировать настройки печати, пользовательские переменные, фильтры и тестовые заметки, чтобы их можно было применять к другим наборам данных, загруженным позже в сессии, а также к другим сессиям.
Выберите «Сервис» > «Импорт выражений»
Нажмите кнопку на панели инструментов ![]()
Редактор данных запоминает настройки типа печати и при повторном открытии отображает те же типы видов. Можно также сохранить форматы печати для сохранения подробных данных нескольких графиков данных.
В диалоговом окне «Импорт переменных», «Фильтры» и «Компоновка редактора» используйте кнопки панели инструментов для импорта переменных, фильтров и листов печати. Импорт из других наборов данных в текущем проекте, из файлов проекта MBC или из файлов, экспортированных из редактора данных.
Чтобы использовать импортированные выражения в текущем проекте, выберите элементы в списках и нажмите кнопку панели инструментов для применения в редакторе данных.
Чтобы сохранить выражения в файле, в редакторе данных выберите «Сервис» > «Экспорт выражений» и выберите имя файла.
В диалоговом окне Define Test Groupings выполняется сбор записей текущего объекта данных в группы. Эти группы называются тестами.
Диалоговое окно открывается из редактора данных одним из следующих способов:
Использование меню Сервис > Тестовые группы
Использование кнопки панели инструментов ![]()
При вводе диалогового окна с помощью holliday данные, график отображается как переменная logno автоматически выбирается для группирования тестов.
Выберите другую переменную для использования при определении групп в данных.
Выбрать n в списке Переменные.
Нажмите ![]() кнопку, чтобы добавить переменную (или дважды щелкните
кнопку, чтобы добавить переменную (или дважды щелкните n).
Переменная n появляется в представлении списка слева. Теперь эту переменную можно использовать для определения групп в данных. Максимальное и минимальное значения n отображаются. Допуск используется для определения групп при чтении данных, когда значение n изменяется больше, чем допуск, определяется новая группа. Значение Допуск (Tolerance) можно изменить, введя его непосредственно в поле редактирования.
Можно определить дополнительные группы, выбрав другую переменную и допуск. Записи данных сгруппированы по n или этой дополнительной переменной, изменяющейся вне их допусков.
Снимите флажок Группировать по для logno. Обратите внимание, что переменные можно выводить на печать без использования для определения групп.
Добавить load в список, выбрав его справа и нажав кнопку .![]()
Изменить load допуск до 0,01 и наблюдать за изменением тестовой группировки на графике.
Снимите флажок Группировать по (Group By) для load. Теперь эта переменная выводится на печать без использования для определения групп.
На графике показаны масштабированные значения всех переменных в представлении списка (цвет текста допуска соответствует цвету точек данных на графике). Вертикальные розовые полосы показывают тесты (группы). Можно масштабировать график, перетаскивая указатель мыши, удерживая нажатой клавишу SHIFT, или перетаскивая указатель мыши. снова уменьшите изображение двойным щелчком мыши.
Выбрать load в представлении списка (оно подсвечивается синим цветом) и удалить его из списка, нажав ![]() кнопку.
кнопку.
Дважды щелкните, чтобы добавить spark и снимите флажок Группировать по (Group By). Выбрать logno в качестве единственной переменной группировки.
Можно распечатать переменную локальной модели (в данном случае искровую), чтобы проверить правильность группирования тестов. График показывает свипы значений искр в каждом тесте, в то время как скорость (n) поддерживается постоянной. Скорость изменяется только между тестами, поэтому она является глобальной переменной. Попробуйте увеличить изображение на графике, чтобы проверить тестовые группы; дважды щелкните для сброса.
Одноэтапные данные определяют один тест для каждой записи, независимо от любой другой группировки. Это необходимо для использования данных при создании одноступенчатых моделей.
Сортировка записей перед группировкой позволяет переупорядочить записи в наборе данных. В противном случае группы определяются с использованием порядка записей в исходном объекте данных.
Show original test groups отображает исходные группы тестов, если они были определены.
Переменная номера теста содержит список всех переменных в текущем наборе данных. Любой из них может быть выбран для нумерации тестов.
убедитесь, что logno выбран для переменной Test number.
Это изменяет способ отображения тестов в остальной части браузера модели. Номер теста может быть полезной переменной для идентификации отдельных тестов в представлениях браузера модели и редактора данных (вместо 1,2,3...), если данные были взяты в пронумерованных тестах и требуется доступ к этой информации во время моделирования.
Если вы выбрали none из списка Переменная номера теста, тесты будут пронумерованы 1,2,3 и так далее в порядке, в котором записи появляются в файле данных. С logno выбранные, вы видите тесты в редакторе данных, перечисленных как 586, 587 и т.д.
Каждая запись в тесте должна иметь один и тот же номер теста, поэтому при использовании переменной для нумерации тестов значение этой переменной берется в первой записи в каждом тесте.
Номера тестов должны быть уникальными, поэтому, если какие-либо значения в выбранной переменной одинаковы, им присваиваются новые номера тестов для целей моделирования (это не изменяет лежащие в основе данные, которые сохраняют правильный номер теста или другую переменную).
Нажмите кнопку OK, чтобы принять определенные группы тестов и закрыть диалоговое окно.
На вкладке Сводка редактора данных просмотрите количество тестов.
Количество записей показывает количество значений, оставшихся (после фильтрации) от каждой переменной в этом наборе данных, за которым следует исходное количество записей. На цветовых кодированных полосах также отображается количество удаленных записей в пропорции к общему числу. Значения собираются в несколько тестов; этот номер также отображается. Переменные показывают исходное количество переменных плюс пользовательские переменные.
Можно использовать пример проекта для иллюстрации процесса сопоставления экспериментальных данных с проектами.
Экспериментальные данные вряд ли будут идентичны требуемым точкам проектирования. Для сравнения фактических данных, собранных с экспериментальными точками проектирования, можно использовать представление «Соответствие конструкции» в редакторе данных. Здесь можно выбрать данные для моделирования. Если вы заинтересованы в сборе большего количества данных, вы можете обновить экспериментальный проект, сопоставив данные с точками проектирования, чтобы отразить фактические собранные данные. Затем можно оптимально расширить проект (используя Редактор дизайна), чтобы определить, какие точки данных было бы наиболее полезно собрать, на основе данных, полученных до настоящего времени.
Можно использовать итеративный процесс: создать конструкцию, собрать некоторые данные, сопоставить эти данные с точками конструкции, соответствующим образом изменить конструкцию, затем собрать больше данных и так далее. Этот процесс можно использовать для оптимизации процесса сбора данных для получения наиболее надежных моделей с минимальным объемом данных.
Для просмотра функций сопоставления данных в браузере модели выберите «Файл» > «Открыть проект» и перейдите к файлу. Data_Matching.mat в matlab\toolbox\mbc\mbctraining папка.
Щелкните значок Spark Sweeps узел в дереве модели для перехода к виду плана испытаний.
Здесь представлен двухэтапный план испытаний с установленными типами моделей и входными данными. Глобальная модель имеет связанный экспериментальный проект (который можно просмотреть в редакторе дизайна). Вы собираетесь использовать редактор данных, чтобы проверить, насколько точно собранные данные соответствуют экспериментальному дизайну.
Нажмите кнопку «Редактировать данные » ()![]() на панели инструментов.
на панели инструментов.
Появится редактор данных.
Для проверки конструкции и точек данных необходимо представление «Соответствие конструкции». Щелкните правой кнопкой мыши вид в редакторе данных и выберите «Текущий вид» > «Соответствие конструкции».
В окне «Соответствие проекта» можно увидеть цветные области, содержащие точки. Это «кластеры», где алгоритм согласования выбирает близко совпадающие дизайн и точки данных.
Значения допуска (первоначально полученные из доли диапазонов переменных) используются для определения того, находятся ли какие-либо точки данных в пределах допуска каждой точки проектирования. Точки данных, находящиеся в пределах допуска любой точки конструкции, сопоставляются с этим кластером. Точки данных, попадающие в допуск нескольких точек проектирования, образуют единый кластер, содержащий все эти точки проектирования и данных. Если точки данных не находятся в пределах допуска проектной точки, они остаются несопоставленными и кластер не выводится на печать.
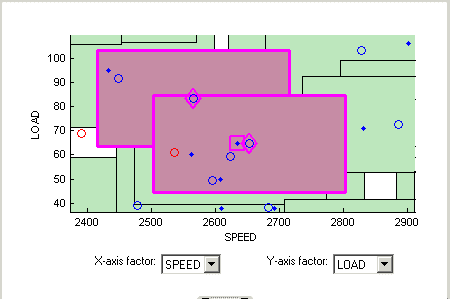
Обратите внимание на форму, образованную перекрывающимися кластерами. Пример, показанный розовым цветом, представляет собой единственный кластер, сформированный там, где точка данных находится в пределах допуска двух точек проектирования.
На этом графике можно увидеть другие очищенные точки, которые, по-видимому, содержатся в этом кластере. Точки отслеживаются через другие факторные размеры с помощью элементов управления осью, чтобы увидеть, где точки отделены за пределами допуска.
Для редактирования значений допусков выберите в контекстном меню «Допуски».
Появится редактор допусков. Здесь можно изменить размер кластеров в каждом измерении. Обратите внимание, что LOAD значение допуска равно 100. Это объясняет удлиненную форму (в LOAD размерность) кластеров на текущем графике, поскольку это значение допуска является высокой долей от общего диапазона этой переменной.
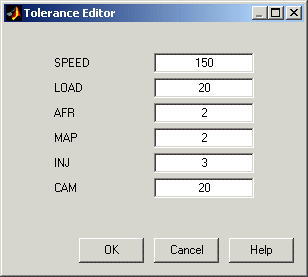
Щелкните на поле редактирования LOAD и введите 20, как показано. Нажмите кнопку ОК.
Обратите внимание на изменение формы кластеров в представлении «Соответствие конструкции».
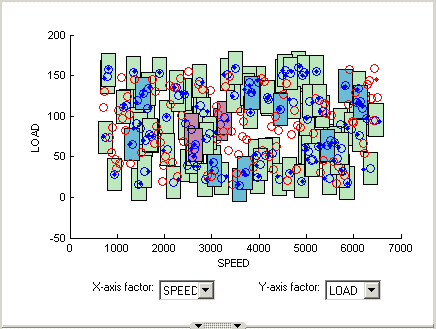
Нажмите кнопку «Shift» (щелкните по центру) и перетащите курсор, чтобы увеличить изображение области графика, как показано на рисунке. Можно дважды щелкнуть, чтобы вернуться к полноразмерному графику.
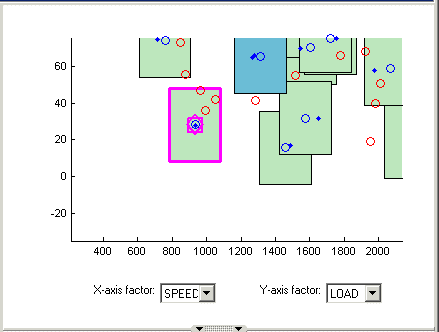
Щелкните кластер, чтобы выбрать его. Выбранные точки или кластеры выделены розовым цветом. При щелчке и удержании можно проверить значения глобальных переменных в выбранных точках (или для всех данных и точек проектирования, если щелкнуть кластер). Эту информацию можно использовать для выбора подходящих значений допуска при попытке совмещения точек.
Обратите внимание, что в списке Информация о кластере (Cluster Information) отображаются сведения обо всех данных и точках конструкции, содержащихся в выбранном кластере. Флажки здесь используются для выбора или исключения данных или точек проектирования. Щелкните различные кластеры, чтобы увидеть различные точки. В списке показаны значения глобальных переменных в каждой точке, а также данные и точки проектирования в пределах допуска друг к другу. Выбранные здесь параметры определяют, какие данные следует использовать для моделирования и какие точки конструкции заменяются фактическими точками данных.
Если вы не заинтересованы в сборе дополнительных данных, то нет необходимости в том, чтобы проект был изменен для отражения фактических данных.
Однако, если вы хотите новый дизайн (называется Actual Design), чтобы точно отразить, какие данные были получены до сих пор, например, чтобы собрать больше данных, то сопоставление кластеров важно. Все точки данных с установленным флажком добавляются к новому Actual Design, за исключением тех, кто в красных скоплениях. Цвет кластеров указывает, какую долю выбранных точек он содержит:
Зеленые кластеры имеют равное количество выбранной конструкции и выбранных точек данных. Точки данных заменят точки проектирования в Actual Design.
Доля выбранных точек определяет цвет; исключенные точки (со снятыми флажками) не действуют. Выбранные флажки могут изменить цвет кластера.
Синие кластеры имеют больше точек данных, чем расчетные точки. Все точки данных заменят точки проектирования в Actual Design.
Красные кластеры имеют больше точек проектирования, чем точки данных. Эти точки данных не будут добавлены в конструкцию, так как алгоритм не может выбрать, какие точки конструкции заменить, поэтому необходимо вручную сделать выбор для работы с красными кластерами, если вы хотите использовать эти точки данных в конструкции.
Если вас не волнует Actual Design (например, если вы не намерены собирать больше данных) и вы просто выбираете данные для моделирования, то вы можете игнорировать красные кластеры. Точки данных в красных кластерах выбираются для моделирования.
Щелкните правой кнопкой мыши «Соответствие конструкции» и выберите «Выбрать несопоставленные данные». Обратите внимание, что остальные несопоставленные точки данных отображаются в списке. Здесь можно использовать флажки, чтобы выбрать или исключить несопоставленные данные так же, как точки в кластерах.
Выберите кластер, затем с помощью раскрывающегося меню измените коэффициент оси Y на INJ. Наблюдать за выбранным кластером, нанесенным на график в новых факторных размерах SPEED и INJ.
Этот метод можно использовать для отслеживания точек и кластеров через размеры. Это может дать вам хорошее представление о том, какие допуски нужно изменить для согласования точек. Помните, что точки, которые не образуют кластер, могут выглядеть идеально совпадающими при просмотре в одной паре измерений; необходимо просмотреть их в других размерах, чтобы узнать, где они отделены за пределами значения допуска. Этот процесс отслеживания можно использовать для определения необходимости сопоставления определенных пар точек и последующего изменения допусков до тех пор, пока они не станут частью кластера.
Снимите флажок Равные данные и конструкция (Equal Data and Design) в представлении Соответствие конструкции (Design Match). Управление печатью осуществляется с помощью этих флажков.
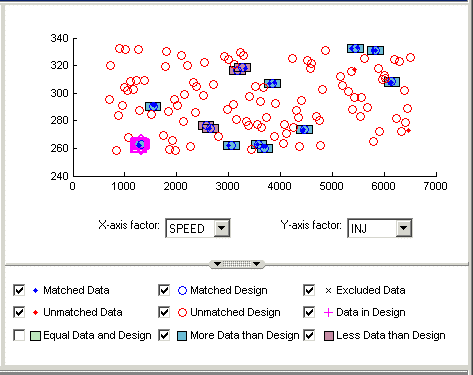
Это приведет к удалению зеленых кластеров из вида, как показано на рисунке. Эти кластеры совпадают; Вы, скорее всего, будете заинтересованы в непревзойденных точках и кластерах с неравномерным количеством данных и точек проектирования. Удаление зеленых кластеров позволяет сосредоточиться на этих интересующих точках. Если вы хотите, чтобы ваш новый Actual Design чтобы точно отразить ваши текущие данные, ваша цель состоит в том, чтобы получить как можно больше точек данных, сопоставленных с точками проектирования; то есть как можно меньше красных кластеров.
Снимите флажок «Больше данных, чем конструкция». Также можно игнорировать синие кластеры, содержащие больше точек данных, чем расчетные точки. Эти точки конструкции заменяются всеми точками данных в кластере. Избыток точек данных вряд ли может вызвать беспокойство.
Однако синие кластеры могут указывать на наличие проблемы со сбором данных в этот момент, и может потребоваться выяснить, почему было собрано больше точек, чем ожидалось.
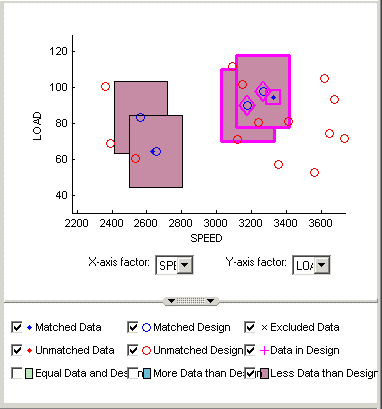
Выберите один из оставшихся красных кластеров. Обе они имеют две точки проектирования в пределах допуска одной точки данных.
Выберите одну из точек проектирования для сопоставления с точкой данных, а затем снимите флажок для другой точки проектирования. Очищенная точка проектирования остается неизменной в проекте. Выбранная проектная точка заменяется соответствующей точкой данных.
Обратите внимание, что красный кластер исчезает. Это происходит потому, что в результате выбора получается кластер с равным количеством выбранных данных и точек проектирования (зеленый кластер), а текущий график не отображает зеленые кластеры.
Повторите для другого красного кластера.
Теперь все скопления зеленые или синие. Остаются две несопоставленные точки данных.
Снимите флажок Несопоставленная конструкция (Unmatched Design), чтобы найти несопоставленные точки данных. Снова установите флажок Несопоставленное проектирование (Unmatched Design), чтобы увидеть точки проектирования и определить, достаточно ли они близки к точкам данных.
Найдите и увеличьте изображение несопоставленной точки данных. Выберите несопоставленную точку данных и ближайшую проектную точку щелчком мыши, затем используйте раскрывающиеся меню оси для отслеживания пары кандидатов по размерам. Решите, достаточно ли близки какие-либо точки проектирования, чтобы гарантировать изменение значений допуска для согласования точки с точкой проектирования.
Напомним, что можно щелкнуть правой кнопкой мыши «Соответствие конструкции» и выбрать «Выбрать несопоставленные данные» для отображения оставшихся несопоставленных точек данных в списке «Информация о кластере». Здесь можно использовать флажки для выбора или исключения этих точек. Если оставить их выбранными, они будут добавлены в Actual Design.
Эти шаги иллюстрируют процесс сопоставления данных с конструкциями, выбора данных моделирования и расширения конструкции на основе полученных фактических данных. Некоторые пробы и ошибки необходимы для поиска полезных значений допуска. Можно выбрать точки и изменить размеры печати, чтобы помочь найти подходящие значения. Если вы хотите, чтобы ваш новый Actual Design чтобы точно отразить экспериментальные данные, необходимо сделать выбор для работы с красными кластерами. Выберите точки проектирования в красных кластерах, которые требуется заменить точками данных. Если этого не сделать, эти точки данных не будут добавлены в новую конструкцию.
Убедившись в том, что выбраны все данные, необходимые для моделирования, закройте редактор данных. На этом этапе варианты в представлении «Соответствие конструкции» применяются к набору данных и новой конструкции с именем Actual Design создается.
Для моделирования выбраны все точки данных с установленным флажком. Точки данных со снятыми флажками исключаются из набора данных. Для создания новой конструкции в существующую конструкцию вносятся изменения Actual Design. Все выбранные данные добавляются в новую конструкцию, за исключением данных в красных кластерах. Выбранные точки данных, которые были сопоставлены с точками проектирования (зелеными и синими кластерами), заменяют эти точки проектирования.
Все выбранные точки данных становятся фиксированными точками проектирования (красными в редакторе проектирования) и отображаются как Data in Design (розовые крестики) при повторном открытии редактора данных.
Это означает, что эти точки не будут включены в кластеры при повторном совпадении. Эти фиксированные точки также не будут изменены в Редакторе проектирования при добавлении точек, хотя при необходимости можно разблокировать фиксированные точки. Это может быть полезно, если вы хотите оптимально увеличить дизайн с учетом уже полученных данных.
