Класс: ClassificationTree
Ошибка классификации в результате повторного предоставления
L = resubLoss(tree)
L = resubLoss(tree,Name,Value)
L = resubLoss(tree,'Subtrees',subtreevector)
[L,se] = resubLoss(tree,'Subtrees',subtreevector)
[L,se,NLeaf] = resubLoss(tree,'Subtrees',subtreevector)
[L,se,NLeaf,bestlevel] = resubLoss(tree,'Subtrees',subtreevector)
[L,...] = resubLoss(tree,'Subtrees',subtreevector,Name,Value)
L = resubLoss(tree)fitctree используется для создания tree.
L = resubLoss(tree,Name,Value)Name,Value аргументы пары. Можно указать несколько аргументов пары имя-значение в любом порядке как Name1,Value1,…,NameN,ValueN.
L = resubLoss(tree,'Subtrees',subtreevector)subtreevector.
[ возвращает вектор стандартных ошибок классификации.L,se] = resubLoss(tree,'Subtrees',subtreevector)
[ возвращает вектор чисел узлов листа в деревьях последовательности обрезки.L,se,NLeaf] = resubLoss(tree,'Subtrees',subtreevector)
[ возвращает наилучший уровень отсечения, определенный в L,se,NLeaf,bestlevel] = resubLoss(tree,'Subtrees',subtreevector)TreeSize пара имя-значение. По умолчанию bestlevel - уровень отсечения, который дает потери в пределах одного стандартного отклонения минимальных потерь.
[L,...] = resubLoss( возвращает статистику потерь с дополнительными опциями, указанными одним или несколькими tree,'Subtrees',subtreevector,Name,Value)Name,Value аргументы пары. Можно указать несколько аргументов пары имя-значение в любом порядке как Name1,Value1,…,NameN,ValueN.
|
Потеря классификации, вектор длины |
|
Стандартная ошибка потери, вектор длины |
|
Количество листьев (конечных узлов) в обрезанных поддеревьях, вектор длина |
|
Скаляр, значение которого зависит от
|
Вычислить ошибку классификации повторной выборки для ionosphere данные.
load ionosphere
tree = fitctree(X,Y);
L = resubLoss(tree)L = 0.0114
Необработанные деревья принятия решений, как правило, слишком подходят. Одним из способов сбалансировать сложность модели и производительность вне выборки является обрезка дерева (или ограничение его роста), чтобы производительность внутри выборки и вне выборки была удовлетворительной.
Загрузите набор данных радужки Фишера. Разбейте данные на наборы обучения (50%) и проверки (50%).
load fisheriris n = size(meas,1); rng(1) % For reproducibility idxTrn = false(n,1); idxTrn(randsample(n,round(0.5*n))) = true; % Training set logical indices idxVal = idxTrn == false; % Validation set logical indices
Создайте дерево классификации с помощью обучающего набора.
Mdl = fitctree(meas(idxTrn,:),species(idxTrn));
Просмотр дерева классификации.
view(Mdl,'Mode','graph');

Дерево классификации имеет четыре уровня обрезки. Уровень 0 - это полное дерево без обрезки (как показано). Уровень 3 - это только корневой узел (т.е. без разбиений).
Проверьте ошибку классификации обучающих образцов для каждого поддерева (или уровня отсечения), исключая самый высокий уровень.
m = max(Mdl.PruneList) - 1;
trnLoss = resubLoss(Mdl,'SubTrees',0:m)trnLoss = 3×1
0.0267
0.0533
0.3067
Полное, неперерезанное дерево неправильно классифицирует около 2,7% тренировочных наблюдений.
Дерево, отсеченное до уровня 1, неправильно классифицирует около 5,3% тренировочных наблюдений.
Дерево, отсеченное до уровня 2 (то есть культи), неправильно классифицирует около 30,6% тренировочных наблюдений.
Проверьте ошибку классификации образца проверки на каждом уровне, исключая самый высокий уровень.
valLoss = loss(Mdl,meas(idxVal,:),species(idxVal),'SubTrees',0:m)valLoss = 3×1
0.0369
0.0237
0.3067
Полное неперерезанное дерево неправильно классифицирует около 3,7% проверочных наблюдений.
Дерево, отсеченное до уровня 1, неправильно классифицирует около 2,4% проверочных наблюдений.
Дерево, отсеченное до уровня 2 (то есть культи), неправильно классифицирует около 30,7% проверочных наблюдений.
Чтобы сбалансировать сложность модели и производительность вне выборки, рассмотрите возможность сокращения Mdl на уровень 1.
pruneMdl = prune(Mdl,'Level',1); view(pruneMdl,'Mode','graph')

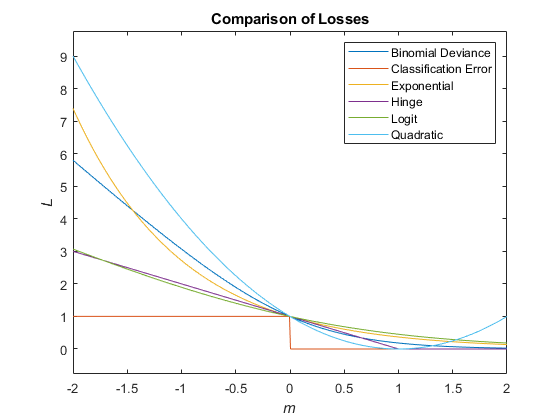
Функции потери классификации измеряют прогностическую неточность классификационных моделей. При сравнении одного и того же типа потерь между многими моделями меньшие потери указывают на лучшую прогностическую модель.
Рассмотрим следующий сценарий.
L - средневзвешенная потеря классификации.
n - размер выборки.
Для двоичной классификации:
yj - наблюдаемая метка класса. Программное обеспечение кодирует его как -1 или 1, указывая отрицательный или положительный класс (или первый или второй класс в ClassNames свойство), соответственно.
f (Xj) - показатель классификации положительного класса для наблюдения (строки) j данных прогнозирования X.
mj = yjf (Xj) - показатель классификации для классификации наблюдения j в класс, соответствующий yj. Положительные значения mj указывают на правильную классификацию и не вносят большого вклада в средние потери. Отрицательные значения mj указывают на неправильную классификацию и вносят значительный вклад в средний убыток.
Для алгоритмов, поддерживающих мультиклассовую классификацию (то есть K ≥ 3):
yj * - вектор из K - 1 нулей, с 1 в положении, соответствующем истинному наблюдаемому классу yj. Например, если истинным классом второго наблюдения является третий класс и K = 4, то y2 * = [0 0 1 0] ′. Порядок классов соответствует порядку в ClassNames свойства входной модели.
f (Xj) - вектор длины K оценок класса для наблюдения j данных предсказателя X. Порядок оценок соответствует порядку классов в ClassNames свойства входной модели.
mj = yj * ′ f (Xj). Поэтому mj - это скалярная оценка классификации, которую модель прогнозирует для истинного наблюдаемого класса.
Вес для наблюдения j равен wj. Программное обеспечение нормализует весовые коэффициенты наблюдения таким образом, что они суммируются с соответствующей вероятностью предыдущего класса. Программное обеспечение также нормализует предыдущие вероятности, так что они составляют 1. Поэтому
С учетом этого сценария в следующей таблице описаны поддерживаемые функции потерь, которые можно указать с помощью 'LossFun' аргумент пары имя-значение.
| Функция потерь | Значение LossFun | Уравнение |
|---|---|---|
| Биномиальное отклонение | 'binodeviance' | |
| Неверно классифицированная скорость в десятичной | 'classiferror' | j - метка класса, соответствующая классу с максимальным баллом. I {·} - функция индикатора. |
| Потери перекрестной энтропии | 'crossentropy' |
Взвешенная потеря перекрестной энтропии равна Kn, где веса нормализуются для суммирования в n вместо 1. |
| Экспоненциальные потери | 'exponential' | ). |
| Потеря шарнира | 'hinge' | |
| Потеря журнала | 'logit' | mj)). |
| Минимальная ожидаемая стоимость классификации ошибок | 'mincost' |
Программное обеспечение вычисляет взвешенную минимальную ожидаемую стоимость классификации, используя эту процедуру для наблюдений j = 1,..., n.
Средневзвешенное минимальное ожидаемое снижение затрат на неправильную классификацию Если используется матрица затрат по умолчанию (значение элемента которой равно 0 для правильной классификации и 1 для неправильной классификации), то |
| Квадратичные потери | 'quadratic' | ) 2. |
На этом рисунке сравниваются функции потерь (за исключением 'crossentropy' и 'mincost') над баллом м для одного наблюдения. Некоторые функции нормализуются для прохождения через точку (0,1).
fitctree | loss | resubEdge | resubMargin | resubPredict
