Classification Learner хорошо подходит для интерактивного выбора и обучения моделей классификации, но не генерирует код C/C + +, который маркирует данные на основе обученной модели. Кнопка «Создать функцию» в разделе «Экспорт» приложения Classification Learner генерирует код MATLAB для обучения модели, но не создает код C/C + +. В этом примере показано, как создать код C из функции, которая прогнозирует метки с использованием экспортированной классификационной модели. Пример строит модель, которая предсказывает кредитный рейтинг бизнеса с учетом различных финансовых коэффициентов, в соответствии со следующими шагами:
Использовать набор данных кредитного рейтинга в файле CreditRating_Historical.dat, которая включена в Toolbox™ статистики и машинного обучения.
Уменьшите размерность данных с помощью анализа основных компонентов (PCA).
Подготовка набора моделей, поддерживающих генерацию кода для прогнозирования меток.
Экспортируйте модель с минимальной пятикратной проверенной точностью классификации.
Создайте код C из функции точки входа, которая преобразует новые данные предиктора, а затем прогнозирует соответствующие метки с помощью экспортированной модели.
Загрузите данные выборки и импортируйте их в приложение Classification Learner. Просмотрите данные с помощью графиков рассеяния и удалите ненужные предикторы.
Использовать readtable для загрузки исторических данных кредитного рейтинга в файл CreditRating_Historical.dat в таблицу.
creditrating = readtable('CreditRating_Historical.dat');
На вкладке Приложения щелкните Классификатор.
В разделе «Классификатор» на вкладке «Классификатор» в разделе «Файл» щелкните «Создать сеанс» и выберите «Из рабочей области».
В диалоговом окне Создать сессию из рабочей области (New Session from Workspace) выберите таблицу creditrating. Все переменные, за исключением переменной, идентифицированной как отклик, являются числовыми векторами с двойной точностью. Щелкните Начало сессии (Start Session), чтобы сравнить модели классификации на основе пятикратной, перекрестно проверенной точности классификации.
Classification Learner загружает данные и строит график рассеяния переменных WC_TA против ID. Поскольку идентификационные номера не подходят для отображения на графике, выберите RE_TA для X в разделе Предикторы.
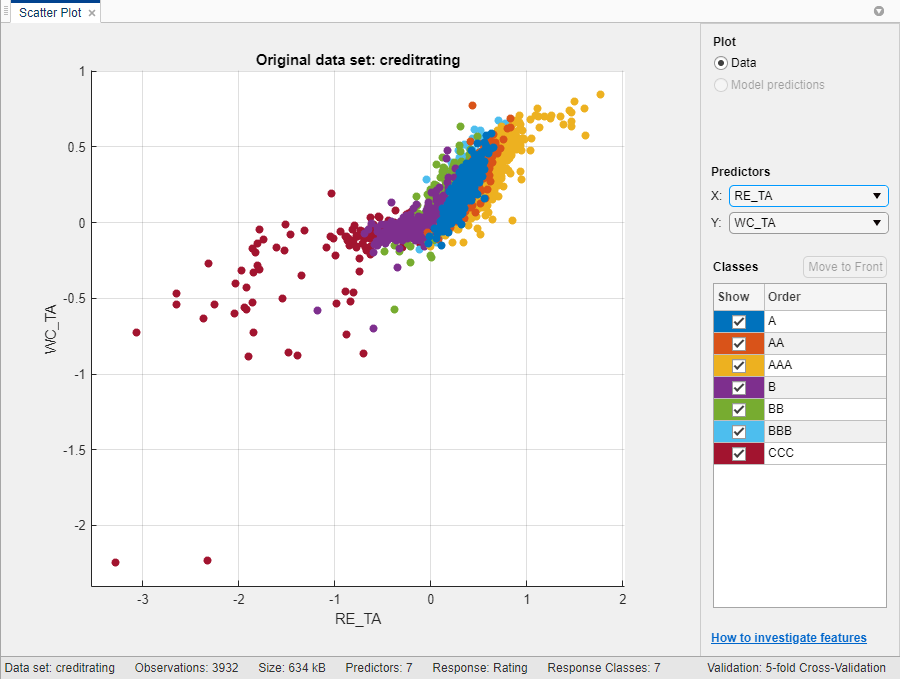
График рассеяния предполагает, что две переменные могут разделить классы AAA, BBB, BB, и CCC довольно хорошо. Однако наблюдения, соответствующие остальным классам, смешиваются с этими классами.
Идентификационные номера не полезны для прогнозирования. Поэтому в разделе Элементы (Features) щелкните Выбор элемента (Feature Selection) и снимите флажок Идентификатор (ID). Также можно удалить ненужные предикторы с самого начала, используя флажки в диалоговом окне Создать сессию из рабочей области (New Session from Workspace). В этом примере показано, как удалить неиспользуемые предикторы для генерации кода при включении всех предикторов.
Включите PCA для уменьшения размерности данных.
В разделе Функции щелкните PCA, а затем выберите Включить PCA. Это действие применяет PCA к данным предиктора, а затем преобразует данные перед обучением моделей. Classification Learner использует только компоненты, которые в совокупности объясняют 95% вариабельности.
Подготовка набора моделей, поддерживающих генерацию кода для прогнозирования меток. Список моделей в Classification Learner, поддерживающих создание кода, см. в разделе Создание кода C для прогнозирования.
Выберите следующие модели и опции классификации, которые поддерживают создание кода для прогнозирования метки, а затем выполните перекрестную проверку (дополнительные сведения см. в разделе Введение в создание кода). Чтобы выбрать каждую модель, в разделе Тип модели (Model Type) щелкните стрелку Показать (Show more), а затем щелкните модель. Выбрав модель и указав любые опции, закройте все открытые меню, а затем щелкните Тренировать (Train) в разделе Обучение (Training).
| Модели и опции для выбора | Описание |
|---|---|
| В разделе Деревья решений (Decision Trees) выберите Все деревья (All Trees) | Деревья классификации различных сложностей |
| В разделе Support Vector Machines выберите All SVM | SVM различной сложности и с использованием различных ядер. Для установки сложных SVM требуется время. |
| В разделе «Классификаторы ансамблей» выберите «Усиленные деревья». В разделе Тип модели (Model Type) щелкните Дополнительно (Advanced). Уменьшите максимальное количество разделений до 5 и увеличьте число обучающихся до 100. | Усиленный ансамбль классификационных деревьев |
| В разделе «Классификаторы ансамблей» выберите «Деревья в мешках». В разделе Тип модели (Model Type) щелкните Дополнительно (Advanced). Увеличить Максимальное число разделений до 50 и Увеличить число обучающихся до 100. | Случайный лес классификационных деревьев |
После перекрестной проверки каждого типа модели на панели Модели (Models) отображается каждая модель и ее пятикратная точность перекрестной проверки классификации, и модель выделяется с наилучшей точностью.
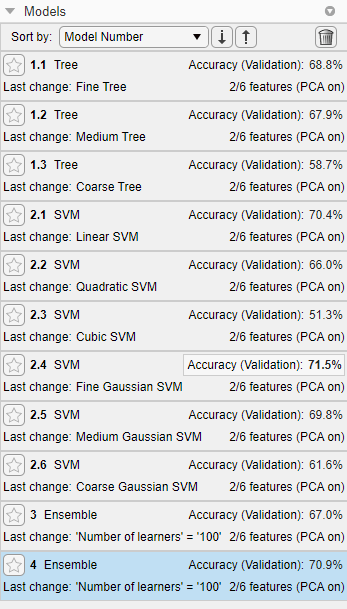
Выберите модель, которая дает максимальную пятикратную точность перекрестной проверки классификации, которая является моделью выходных кодов с исправлением ошибок (ECOC) для учеников с тонким гауссовым SVM. С включенным PCA программа Classification Learner использует два предиктора из шести.
В разделе «Графики» щелкните «Матрица путаницы» и выберите «Данные проверки».
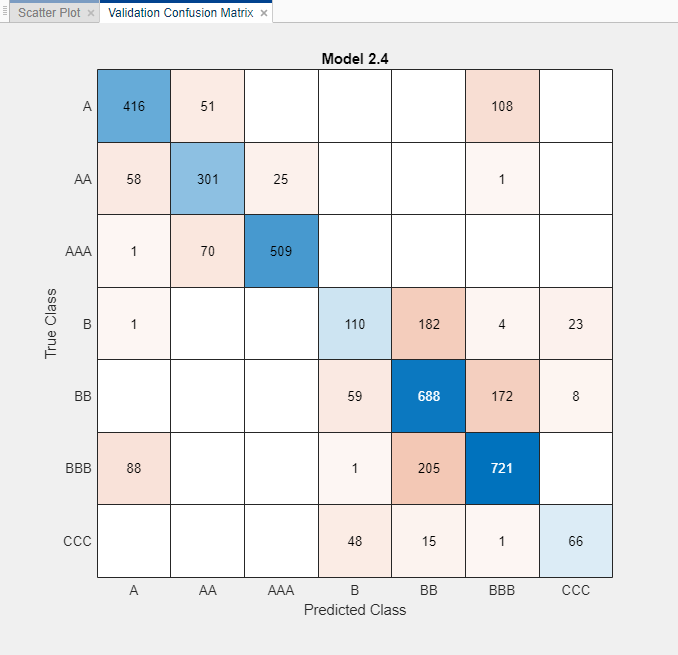
Модель хорошо различает A, B, и C классы. Однако модель не так хорошо различает конкретные уровни в этих группах, в частности более низкие уровни В.
Экспорт модели в рабочую область MATLAB ® и сохранение модели с помощьюsaveLearnerForCoder.
В разделе Экспорт щелкните Экспорт модели, а затем выберите Экспорт компактной модели. Нажмите кнопку ОК в диалоговом окне.
Структура trainedModel появляется в рабочей области MATLAB. Область ClassificationSVM из trainedModel содержит компактную модель.
В командной строке сохраните компактную модель в файле с именем ClassificationLearnerModel.mat в текущей папке.
saveLearnerForCoder(trainedModel.ClassificationSVM,'ClassificationLearnerModel')Прогнозирование с использованием функций объекта требует обученного объекта модели, но -args вариант codegen (Кодер MATLAB) не принимает такие объекты. Обойти это ограничение с помощью saveLearnerForCoder и loadLearnerForCoder. Сохранение обучаемой модели с помощью saveLearnerForCoder. Затем определите функцию точки входа, которая загружает сохраненную модель с помощью loadLearnerForCoder и вызывает predict функция. Наконец, используйте codegen для создания кода для функции точки входа.
Предварительная обработка новых данных выполняется так же, как и предварительная обработка данных обучения.
Для предварительной обработки необходимы следующие три параметра модели:
removeVars - Вектор столбца не более p элементы, идентифицирующие индексы переменных для удаления из данных, где p - количество переменных предиктора в необработанных данных
pcaCenters - Вектор строки точно q Центры PCA
pcaCoefficients — qоколо-r матрица коэффициентов PCA, где r самое большее q
Укажите индексы переменных предиктора, которые были удалены при выборе данных с помощью параметра «Выбор элемента» в разделе «Классификатор». Извлеките статистику PCA из trainedModel.
removeVars = 1; pcaCenters = trainedModel.PCACenters; pcaCoefficients = trainedModel.PCACoefficients;
Сохранение параметров модели в файле с именем ModelParameters.mat в текущей папке.
save('ModelParameters.mat','removeVars','pcaCenters','pcaCoefficients');
Функция точки входа - это функция, определяемая для генерации кода. Потому что вы не можете вызвать какую-либо функцию на верхнем уровне с помощью codegen, необходимо определить функцию точки входа, которая вызывает функции с поддержкой генерации кода, а затем создать код C/C + + для функции точки входа с помощью codegen.
В текущей папке определите функцию с именем mypredictCL.m что:
Принимает числовую матрицу (X) необработанных наблюдений, содержащих те же предикторные переменные, что и те, которые были переданы в Classification Learner
Загружает классификационную модель в ClassificationLearnerModel.mat и параметры модели в ModelParameters.mat
Удаляет переменные предиктора, соответствующие индексам в removeVars
Преобразует оставшиеся данные предиктора с помощью центров PCA (pcaCenters) и коэффициенты (pcaCoefficients) оценивается классификатором
Возвращает прогнозируемые метки с использованием модели
function label = mypredictCL(X) %#codegen %MYPREDICTCL Classify credit rating using model exported from %Classification Learner % MYPREDICTCL loads trained classification model (SVM) and model % parameters (removeVars, pcaCenters, and pcaCoefficients), removes the % columns of the raw matrix of predictor data in X corresponding to the % indices in removeVars, transforms the resulting matrix using the PCA % centers in pcaCenters and PCA coefficients in pcaCoefficients, and then % uses the transformed data to classify credit ratings. X is a numeric % matrix with n rows and 7 columns. label is an n-by-1 cell array of % predicted labels. % Load trained classification model and model parameters SVM = loadLearnerForCoder('ClassificationLearnerModel'); data = coder.load('ModelParameters'); removeVars = data.removeVars; pcaCenters = data.pcaCenters; pcaCoefficients = data.pcaCoefficients; % Remove unused predictor variables keepvars = 1:size(X,2); idx = ~ismember(keepvars,removeVars); keepvars = keepvars(idx); XwoID = X(:,keepvars); % Transform predictors via PCA Xpca = bsxfun(@minus,XwoID,pcaCenters)*pcaCoefficients; % Generate label from SVM label = predict(SVM,Xpca); end
Поскольку C и C++ являются статически типизированными языками, необходимо определить свойства всех переменных в функции точки входа во время компиляции. Укажите аргументы переменного размера с помощью coder.typeof (Кодер MATLAB) и создайте код с помощью аргументов.
Создание матрицы двойной точности с именем x для генерации кода с использованием coder.typeof (Кодер MATLAB). Укажите, что количество строк x является произвольным, но что x должен иметь p столбцы.
p = size(creditrating,2) - 1; x = coder.typeof(0,[Inf,p],[1 0]);
Дополнительные сведения об указании аргументов переменного размера см. в разделе Указание аргументов переменного размера для создания кода.
Создание функции MEX из mypredictCL.m. Используйте -args параметр для указания x в качестве аргумента.
codegen mypredictCL -args x
codegen создает файл MEX mypredictCL_mex.mexw64 в текущей папке. Расширение файла зависит от платформы.
Убедитесь, что функция MEX возвращает ожидаемые метки.
Удалите переменную ответа из исходного набора данных, а затем произвольно проведите 15 наблюдений.
rng('default'); % For reproducibility m = 15; testsampleT = datasample(creditrating(:,1:(end - 1)),m);
Прогнозирование соответствующих меток с помощью predictFcn в модели классификации, обученной Classification Learner.
testLabels = trainedModel.predictFcn(testsampleT);
Преобразование результирующей таблицы в матрицу.
testsample = table2array(testsampleT);
Столбцы testsample соответствуют столбцам данных предиктора, загруженных Classification Learner.
Передача тестовых данных в mypredictCL. Функция mypredictCL предсказывает соответствующие метки с помощью predict и модель классификации, обученную Classification Learner.
testLabelsPredict = mypredictCL(testsample);
Прогнозирование соответствующих меток с помощью созданной функции MEX mypredictCL_mex.
testLabelsMEX = mypredictCL_mex(testsample);
Сравните наборы прогнозов.
isequal(testLabels,testLabelsMEX,testLabelsPredict)
ans = logical 1
isequal возвращает логический 1 (true), если все входы равны. predictFcn, mypredictCLи функция MEX возвращает те же значения.
learnerCoderConfigurer | loadLearnerForCoder | saveLearnerForCoder | codegen (Кодер MATLAB) | coder.typeof (Кодер MATLAB)
