Интерактивная пошаговая регрессия
stepwise
stepwise(X,y)
stepwise(X,y,inmodel,penter,premove)
stepwise использует данные образца в hald.mat для отображения графического интерфейса пользователя для выполнения пошаговой регрессии значений ответа в heat о прогностических терминах в ingredients.
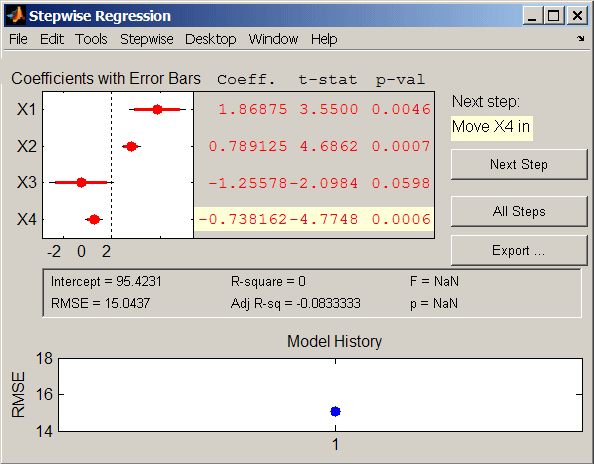
В левом верхнем углу интерфейса отображаются оценки коэффициентов для всех потенциальных членов с горизонтальными столбцами, указывающими на 90% (цветные) и 95% (серые) доверительные интервалы. Красный цвет указывает на то, что изначально терминов в модели нет. В таблице отображаются значения, которые могут быть получены при добавлении терминов в модель.
В средней части интерфейса отображается сводная статистика по всей модели. Эти статистические данные обновляются с каждым шагом.
В нижней части интерфейса История модели (Model History) отображается RMSE для модели. График отслеживает RMSE от шага к шагу, чтобы можно было сравнить оптимальность различных моделей. Наведите курсор на синие точки в истории, чтобы увидеть, какие термины были в модели на определенном этапе. Щелкните синюю точку в истории, чтобы открыть копию интерфейса, инициализированного терминами в модели на этом шаге.
Исходные модели, а также допуски входа/выхода для p-значений F-статистики задаются с помощью дополнительных входных аргументов для stepwise. Значения по умолчанию представляют собой начальную модель без членов, входной допуск 0,05 и выходной допуск 0,10.
Чтобы центрировать и масштабировать входные данные (вычислить z-оценки) для улучшения кондиционирования лежащей в основе задачи наименьших квадратов, выберите Scale Inputs в меню Пошаговая (Stepwise).
Пошаговая регрессия выполняется одним из двух способов:
Щелкните Следующий шаг (Next Step), чтобы выбрать рекомендуемый следующий шаг. Рекомендуемый следующий шаг либо добавляет наиболее значимый термин, либо удаляет наименее значимый термин. Когда регрессия достигает локального минимума RMSE, рекомендуемым следующим шагом является «Move no terms». Все рекомендуемые шаги можно выполнить сразу, щелкнув Все шаги.
Щелкните строку на графике или в таблице, чтобы переключить состояние соответствующего элемента. Щелчок красной линии, соответствующей термину, который в настоящее время не находится в модели, добавляет этот термин в модель и изменяет его на синий. Если щелкнуть синюю линию, соответствующую термину, находящемуся в модели, этот термин удаляется из модели и изменяется на красный.
Звонить addedvarplot и создать график добавленной переменной из stepwise выберите в меню Пошаговый (Stepwise) команду Добавить переменный график (Added Variable Plot). Отображается список терминов. Выберите термин, который требуется добавить, и нажмите кнопку ОК.
Щелкните Экспорт (Export), чтобы открыть диалоговое окно, в котором можно выбрать информацию из интерфейса для сохранения в рабочей области MATLAB ®. Проверьте информацию, которую требуется экспортировать, и, при необходимости, измените имена создаваемых переменных рабочей области. Нажмите кнопку ОК, чтобы экспортировать информацию.
stepwise(X,y) отображает интерфейс с использованием предсказательных терминов p в матрице n-by-p X и значения отклика в векторе n-by-1 y. Различные прогностические термины должны появляться в различных столбцах X.
Примечание
stepwise автоматически включает постоянный член во все модели. Не вводите столбец 1 непосредственно в X.
stepwise удовольствия NaN значения в любом из них X или y как отсутствующие значения, и игнорирует их.
stepwise(X,y,inmodel,penter,premove) дополнительно задает начальную модель (inmodel) и вход (penter) и выход (premove) допуски для p-значений F-статистики. inmodel является логическим вектором с длиной, равной количеству столбцов Xили вектор индексов со значениями в диапазоне от 1 до числа столбцов в X. Значение penter должно быть меньше или равно значению premove.
Ступенчатая регрессия - систематический метод добавления и удаления членов из многолинейной модели на основе их статистической значимости в регрессии. Метод начинается с начальной модели и затем сравнивает объяснительную силу инкрементально больших и меньших моделей. На каждом этапе значение p F-статистики вычисляется для тестирования моделей с потенциальным термином и без него. Если член в настоящее время не находится в модели, нулевая гипотеза состоит в том, что член будет иметь нулевой коэффициент при добавлении к модели. При наличии достаточных доказательств для отклонения нулевой гипотезы к модели добавляется термин. И наоборот, если член в настоящее время находится в модели, нулевая гипотеза состоит в том, что член имеет нулевой коэффициент. Если доказательств для отклонения нулевой гипотезы недостаточно, термин удаляется из модели. Способ осуществляется следующим образом:
Подгоните исходную модель.
Если какие-либо члены, отсутствующие в модели, имеют p-значения, меньшие, чем входной допуск (то есть, если маловероятно, что они имели бы нулевой коэффициент при добавлении в модель), добавьте один с наименьшим значением p и повторите этот шаг; в противном случае перейдите к шагу 3.
Если какие-либо члены в модели имеют p-значения, превышающие допуск выхода (то есть, если маловероятно, что гипотеза нулевого коэффициента может быть отвергнута), удалите значение с наибольшим значением p и перейдите к шагу 2; в противном случае конец.
В зависимости от терминов, включенных в начальную модель, и порядка, в котором термины перемещаются внутрь и наружу, метод может строить различные модели из одного и того же набора потенциальных терминов. Метод завершается, когда ни один шаг не улучшает модель. Однако нет никакой гарантии, что иная начальная модель или другая последовательность шагов не приведут к лучшей подгонке. В этом смысле пошаговые модели являются локально оптимальными, но могут не быть глобально оптимальными.
