Декодирование с низкой плотностью проверки четности (LDPC)
[ возвращает декодированную LDPC выходную матрицу out,actNumIter,finalParityChecks] = nrLDPCDecode(in,bgn,maxNumIter)out для матрицы входных данных in, базовый номер график bgnи максимальное количество итераций декодирования maxNumIter. Функция также возвращает фактическое количество итераций actNumIter и конечные проверки четности по кодовому слову finalParityChecks.
Декодер использует алгоритм передачи суммарного сообщения. Биты данных должны быть закодированы LDPC, как определено в TS 38.212 Раздел 5.3.2 [1].
[ задает необязательные аргументы аргументы пары "имя-значение" дополнение к входным параметрам в предыдущем синтаксисе.out,actNumIter,finalParityChecks] = nrLDPCDecode(___,Name,Value)
The nrLDPCDecode функция поддерживает эти четыре алгоритма декодирования LDPC.
Реализация алгоритма распространения убеждений основана на алгоритме декодирования, представленном в [2]. Для переданного кодового слова с кодировкой LDPC, c, где , входом для декодера LDPC является значение отношения логарифмической правдоподобности (LLR) .
В каждой итерации ключевые компоненты алгоритма обновляются на основе этих уравнений:
,
, инициализированный как перед первой итерацией, и
.
В конце каждой итерации, является обновленной оценкой значения LLR для переданного бита . Значение - выходы мягкого решения для . Если , выход жесткого решения для равен 1. В противном случае выводится значение 0.
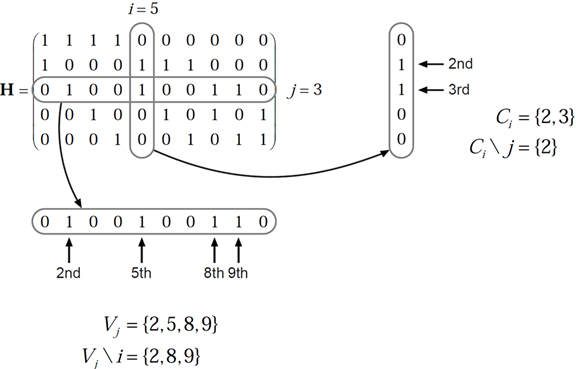
Наборы индексов и основаны на матрице проверки четности (PCM). Наборы индексов и соответствуют всем ненулевым элементам в столбцах i и j строках PCM, соответственно.
Этот рисунок подсвечивает расчет этих наборов индексов в заданном PCM для i = 5 и j = 3.
Чтобы избежать бесконечных чисел в уравнениях алгоритма, atanh (1) и atanh (-1) устанавливаются в 19.07 и -19.07 соответственно. Из-за конечной точности MATLAB® возвращает 1 для танха (19.07) и -1 для танха (-19.07).
Когда аргумент пары "имя-значение" 'Termination' установлено в 'max'декодирование заканчивается после maxNumIter количество итераций. Когда 'Termination' установлено в 'early'декодирование заканчивается, когда выполняются все проверки четности () или после maxNumIter количество итераций.
[1] 3GPP TS 38.212. "NR; Мультиплексирование и канальное кодирование. "3rd Генерация Partnership Project; Группа технических спецификаций Радиосеть доступ.
[2] Gallager, Robert G. Low-Density Parity-Check Codes, Cambridge, MA, MIT Press, 1963.
[3] Hocevar, D.E. «архитектура декодера пониженной сложности посредством многоуровневого декодирования кодов LDPC». Семинар IEEE по системам обработки сигналов, 2004 год. SIPS 2004. doi: 10.1109/SIPS.2004.1363033
[4] Chen, Jinghu, R.M. Tanner, C. Jones и Yan Li. «Улучшенные алгоритмы декодирования min-sum для неправильных кодов LDPC». В производстве. Международный симпозиум по теории информации, 2005 год. ISIT 2005. doi: 10.1109/ISIT.2005.1523374
