Классификация звуков в аудиосигнале
sounds = classifySound(audioIn,fs,Name,Value)Name,Value аргументы в виде пар.
sounds = classifySound(audioIn,fs,'SpecificityLevel','low') классифицирует звуки с использованием низкой специфичности.[ также возвращает метки времени, сопоставленные с каждым обнаруженным звуком.sounds,timestamps] = classifySound(___)
[ также возвращает таблицу, содержащую подробные данные результатов.sounds,timestamps,resultsTable] = classifySound(___)
classifySound(___) без выходных аргументов создает облако слов идентифицированных звуков в аудиосигнале.
Эта функция требует как Audio Toolbox™, так и Deep Learning Toolbox™.
classifySoundЗагрузите и разархивируйте поддержку Audio Toolbox™ для YAMNet.
Если поддержка Audio Toolbox для YAMNet не установлена, то первый вызов функции предоставляет ссылку на расположение загрузки. Чтобы скачать модель, щелкните ссылку. Разархивируйте файл в местоположении по пути MATLAB.
Также выполните следующие команды, чтобы загрузить и разархивировать модель YAMNet во временную директорию.
downloadFolder = fullfile(tempdir,'YAMNetDownload'); loc = websave(downloadFolder,'https://ssd.mathworks.com/supportfiles/audio/yamnet.zip'); YAMNetLocation = tempdir; unzip(loc,YAMNetLocation) addpath(fullfile(YAMNetLocation,'yamnet'))
Сгенерируйте 1 секунду розового шума, принимая частоту дискретизации 16 кГц.
fs = 16e3; x = pinknoise(fs);
Функции classifySound с розовым сигналом шума и частотой дискретизации.
identifiedSound = classifySound(x,fs)
identifiedSound = "Pink noise"
Считывайте аудиосигнал. Функции classifySound для возврата обнаруженных звуков и соответствующих меток времени.
[audioIn,fs] = audioread('multipleSounds-16-16-mono-18secs.wav');
[sounds,timeStamps] = classifySound(audioIn,fs);Постройте график аудиосигнала и пометьте обнаруженные области звука.
t = (0:numel(audioIn)-1)/fs; plot(t,audioIn) xlabel('Time (s)') axis([t(1),t(end),-1,1]) textHeight = 1.1; for idx = 1:numel(sounds) patch([timeStamps(idx,1),timeStamps(idx,1),timeStamps(idx,2),timeStamps(idx,2)], ... [-1,1,1,-1], ... [0.3010 0.7450 0.9330], ... 'FaceAlpha',0.2); text(timeStamps(idx,1),textHeight+0.05*(-1)^idx,sounds(idx)) end

Выберите область и прослушивайте только выбранную область.
sampleStamps = floor(timeStamps*fs)+1; soundEvent =3; isolatedSoundEvent = audioIn (sampleStamps (soundEvent, 1): sampleStamps (soundEvent, 2)); звук (isolatedSoundEvent, fs); отображение ('Detected Sound = ' + звуки (soundEvent))
"Detected Sound = Snoring"
Считывайте в аудиосигнале, содержащем несколько различных звуковых событий.
[audioIn,fs] = audioread('multipleSounds-16-16-mono-18secs.wav');Функции classifySound с аудиосигналом и частотой дискретизации.
[sounds,~,soundTable] = classifySound(audioIn,fs);
The sounds Строковые массивы содержат наиболее вероятное звуковое событие в каждой области.
sounds
sounds = 1×5 string
"Stream" "Machine gun" "Snoring" "Bark" "Meow"
The soundTable содержит подробную информацию относительно звуков, обнаруженных в каждой области, включая средство счета и максимумы по анализируемому сигналу.
soundTable
soundTable=5×2 table
TimeStamps Results
________________ ___________
0 3.92 {4×3 table}
4.0425 6.0025 {3×3 table}
6.86 9.1875 {2×3 table}
10.658 12.373 {4×3 table}
12.985 16.66 {4×3 table}
Просмотр последней обнаруженной области.
soundTable.Results{end}ans=4×3 table
Sounds AverageScores MaxScores
________________________ _____________ _________
"Animal" 0.79514 0.99941
"Domestic animals, pets" 0.80243 0.99831
"Cat" 0.8048 0.99046
"Meow" 0.6342 0.90177
Функции classifySound снова. На этот раз установите IncludedSounds на Animal так что функция сохраняет только области, в которых Animal обнаружен класс звука.
[sounds,timeStamps,soundTable] = classifySound(audioIn,fs, ... 'IncludedSounds','Animal');
Массив звуков возвращает только звуки, заданные как включенные звуки. The sounds массив теперь содержит два образцов Animal которые соответствуют областям, объявленной как Bark и Meow ранее.
sounds
sounds = 1×2 string
"Animal" "Animal"
Звуковая таблица включает только области, в которых были обнаружены указанные классы звука.
soundTable
soundTable=2×2 table
TimeStamps Results
________________ ___________
10.658 12.373 {4×3 table}
12.985 16.66 {4×3 table}
Просмотр последней обнаруженной области в soundTable. Таблица результатов по-прежнему включает статистику по всем обнаруженным звукам в области.
soundTable.Results{end}ans=4×3 table
Sounds AverageScores MaxScores
________________________ _____________ _________
"Animal" 0.79514 0.99941
"Domestic animals, pets" 0.80243 0.99831
"Cat" 0.8048 0.99046
"Meow" 0.6342 0.90177
Чтобы исследовать, какие классы звука поддерживаются classifySound, использовать yamnetGraph.
Считывайте аудиосигнал и вызывайте classifySound осматривать наиболее вероятные звуки, расположенные в хронологическом порядке обнаружения.
[audioIn,fs] = audioread("multipleSounds-16-16-mono-18secs.wav");
sounds = classifySound(audioIn,fs)sounds = 1×5 string
"Stream" "Machine gun" "Snoring" "Bark" "Meow"
Функции classifySound снова и установите ExcludedSounds на Meow чтобы исключить звук Meow из результатов. Сегмент, ранее классифицированный как Meow теперь классифицируется как Cat, который является его непосредственным предшественником в онтологии AudioSet.
sounds = classifySound(audioIn,fs,"ExcludedSounds","Meow")
sounds = 1×5 string
"Stream" "Machine gun" "Snoring" "Bark" "Cat"
Функции classifySound снова и установите ExcludedSounds на Cat. Когда вы исключаете звук, все преемники также исключены. Это означает, что исключение звука Cat также исключает звук Meow. Сегмент первоначально классифицировался как Meow теперь классифицируется как Domestic animals, pets, который является непосредственным предшественником Cat в онтологии AudioSet.
sounds = classifySound(audioIn,fs,"ExcludedSounds","Cat")
sounds = 1×5 string
"Stream" "Machine gun" "Snoring" "Bark" "Domestic animals, pets"
Функции classifySound снова и установите ExcludedSounds на Domestic animals, pets. Класс звука, Domestic animals, pets является предшественником обоих Bark и Meow, таким образом, исключив его, звуки, ранее идентифицированные как Bark и Meow теперь оба идентифицируются как предшественники Domestic animals, pets, что Animal.
sounds = classifySound(audioIn,fs,"ExcludedSounds","Domestic animals, pets")
sounds = 1×5 string
"Stream" "Machine gun" "Snoring" "Animal" "Animal"
Функции classifySound снова и установите ExcludedSounds на Animal. Класс звука Animal не имеет предшественников.
sounds = classifySound(audioIn,fs,"ExcludedSounds","Animal")
sounds = 1×3 string
"Stream" "Machine gun" "Snoring"
Если вы хотите избежать обнаружения Meow и его предшественники, но продолжайте обнаруживать преемников под теми же предшественниками, используйте IncludedSounds опция. Функции yamnetGraph чтобы получить список всех поддерживаемых классов. Удаление Meow и его предшественников из массива всех классов, а затем вызывать classifySound снова.
[~,classes] = yamnetGraph; classesToInclude = setxor(classes,["Meow","Cat","Domestic animals, pets","Animal"]); sounds = classifySound(audioIn,fs,"IncludedSounds",classesToInclude)
sounds = 1×4 string
"Stream" "Machine gun" "Snoring" "Bark"
Считывайте аудиосигнал и слушайте его.
[audioIn,fs] = audioread('multipleSounds-16-16-mono-18secs.wav');
sound(audioIn,fs)Функции classifySound без выходных аргументов для генерации облака слов обнаруженных звуков.
classifySound(audioIn,fs);

Измените параметры по умолчанию classifySound чтобы исследовать эффект на облако слов.
threshold =0.1; minimumSoundSeparation =
0.92; minimumSoundDuration =
1.02; classifySound (audioIn, fs,... 'Threshold', порог ,... 'MinimumSoundSeparation', minimumSoundSeparation ,... 'MinimumSoundDuration', minimumSoundDuration);

classifySound функция использует YAMNet, чтобы классифицировать сегменты звука в классы звука, описанные онтологией AudioSet. classifySound функция предварительно обрабатывает аудио так, чтобы оно было в формате, требуемом YAMNet, и постпроцессирует предсказания YAMNet с общими задачами, которые делают результаты более интерпретируемыми.
Пропустите каждый из 521 доверительных сигналов через фильтр скользящего среднего значения с длиной окна 7.
Пропустите каждый из сигналов через движущийся медианный фильтр с длиной окна 3.
Преобразуйте доверительные сигналы в двоичные маски с помощью заданной Threshold.
Сбросьте любой звук короче MinimumSoundDuration.
Объедините области, которые ближе MinimumSoundSeparation.
Консолидируйте идентифицированные звуковые области, которые перекрываются на 50% или более, в отдельные области. Время запуска области является наименьшим временем начала всех звуков в группе. Время окончания области является самым большим временем окончания из всех звуков в группе. Функция возвращает метки времени, классы звуков и среднее и максимальное доверие классов звука в области resultsTable.
Уровень специфичности классификации звука можно задать с помощью SpecificityLevel опция. Например, предположим, что в звуковой группе существует четыре класса звука со следующими соответствующими средними счетами по звуковой области:
Water – 0.82817
Stream – 0.81266
Trickle, dribble – 0.23102
Pour – 0.20732
Классы звука, Water, Stream, Trickle, dribble, и Pour расположены в онтологии AudioSet, как обозначено графиком:
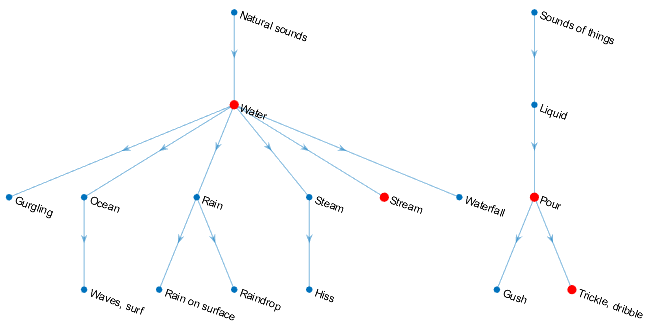
Функции возвращают класс звука для звуковой группы в sounds выходной аргумент в зависимости от SpecificityLevel:
"high" (по умолчанию) -- В этом режиме Stream предпочтительнее Water, и Trickle, dribble предпочтительнее Pour. Stream имеет более высокий средний счет по области, поэтому функция возвращается Stream в sounds выход для области.
"low" - В этом режиме возвращается самая общая онтологическая категория для класса звука с самым высоким средним доверием над областью. Для Trickle, dribble и Pour, наиболее общая категория Sounds of things. Для Stream и Water, наиболее общая категория Natural sounds. Потому что Water имеет самое высокое среднее доверие в звуковой области, функция возвращается Natural sounds.
"none" -- В этом режиме функция возвращает класс звука с самой высокой средней оценкой достоверности, который в этом примере Water.
[1] Gemmeke, Jort F., et al. «Audio Set: An Ontology and Human-Labeled Dataset for Audio Events». 2017 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), IEEE, 2017, pp. 776-80. DOI.org (Crossref), doi:10.1109/ICASSP.2017.7952261.
[2] Hershey, Shawn, et al. «Архитектуры CNN для Крупномасштабной Аудио Классификации». Международная конференция IEEE 2017 года по вопросам Акустики, Речи и Сигнала, Обрабатывающего (ICASSP), IEEE, 2017, стр 131-35. DOI.org (Crossref), doi:10.1109/ICASSP.2017.7952132.
Audio Labeler | vggish | vggishFeatures | yamnet | yamnetGraph
