Цифровое предыскажение
Коррекция искажений Communications Toolbox/RF
Примените цифровое предварительное искажение (DPD) к комплексному сгенерированному модулированному сигналу с помощью полинома памяти для компенсации нелинейностей в усилителе степени. Для получения дополнительной информации см. Раздел «Цифровое предварительное искажение».
Этот значок показывает блок с включенными всеми портами.
![]()
Типы данных |
|
Многомерные сигналы |
|
Сигналы переменного размера |
|
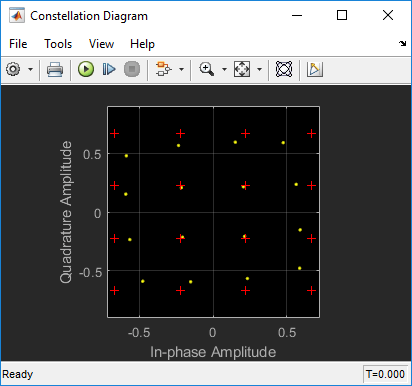
Передачи беспроводной связи обычно требуют широкополосной передачи сигнала в широкой динамической области значений сигналов. Чтобы передавать сигналы в широкой динамической области значений и достигать высокой эффективности, усилители степени RF (PA) обычно работают в своей нелинейной области. Как показывает эта схема созвездия, нелинейное поведение PA вызывает искажения сигнальных созвездий, которые защемляют амплитуду (искажение AM-AM) и фазу скручивания (искажение AM-PM) точек совокупности, пропорциональных амплитуде точки совокупности.
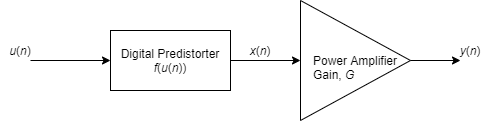
Цель цифрового предварительного искажения состоит в том, чтобы найти нелинейную функцию, которая линеаризирует чистый эффект нелинейного поведения PA на выходе PA через рабочую область значений PA. Когда вход PA x (<reservedrangesplaceholder9>), и функция перед искажением f (u (<reservedrangesplaceholder6>)), где u (<reservedrangesplaceholder4>) является истинным сигналом, который будет усилен, выход PA приблизительно равен <reservedrangesplaceholder3> × <reservedrangesplaceholder2> (<reservedrangesplaceholder1>), где G - желаемая амплитудная выгода PA.
Цифровое предыскажение может быть сконфигурирован, чтобы использовать полином памяти с перекрестными терминами или без них.
Полином памяти с перекрестными терминами предопределяет входной сигнал как
У полинома памяти со взаимными условиями есть (M + <reservedrangesplaceholder5> × <reservedrangesplaceholder4> × (K - 1)) коэффициенты для cm и <reservedrangesplaceholder0> mjk.
Полином памяти без перекрестных членов предваряет входной сигнал как
Полином без перекрестных членов имеет M × K коэффициентов для amk.
Оценка функции предварительного искажения и коэффициентов
Оценка коэффициента DPD использует косвенную архитектуру обучения, чтобы найти f функции (u (n)), чтобы предопределить u входного сигнала (n), который предшествует входу PA.
Алгоритм оценки коэффициентов DPD моделирует нелинейные эффекты памяти PA на основе работы в справочных работах Morgan et al [1] и Schetzen [2], используя теоретический фундамент, разработанный для систем Вольтерры.
В частности, обратное отображение из вывода PA, нормированного усилением PA, {y (n )/ G}, на вход PA, {x (n)}, обеспечивает хорошее приближение к f функции (u (n)), необходимому для предопределения {u (n)} для создания { x (n)}.
Ссылаясь на полиномиальные уравнения памяти выше, оценки вычисляются для полиномиальных коэффициентов памяти:
cm и amjk для полинома памяти с перекрестными терминами
amk для полинома памяти без перекрестных членов
Полиномиальные коэффициенты памяти оцениваются с помощью алгоритма метода наименьших квадратов или рекурсивного алгоритма наименьших квадратов. Алгоритм аппроксимации методом наименьших квадратов или рекурсивный алгоритм наименьших квадратов используют вышеприведенные полиномиальные уравнения памяти для полинома памяти с перекрестными терминами или без них путем замены {u (n)} на {y (n )/ G}. Порядок функции и размерность матрицы коэффициентов заданы степенью и глубиной полинома памяти.
Для примера, который подробно описывает процесс точной оценки полиномиальных коэффициентов памяти и предварительного искажения входного сигнала PA, см. «Цифровое предварительное искажение» для компенсации нелинейностей усилителя степени.
Справочная ссылка материал см. в работах, перечисленных в [1] и [2].
[1] Морган, Деннис Р., Чжэнсян Ма, Джейхён Ким, Майкл Г. Зиердт и Джон Пасталан. «Обобщенная модель Полинома памяти для цифрового предварительного искажения Степени усилителей». IEEE® Транзакции по обработке сигналов. Том 54, № 10, октябрь 2006, стр. 3852-3860.
[2] М. Схетцен. Теории Вольтерры и Винера нелинейных систем. Нью-Йорк: Уайли, 1980.

