![]()
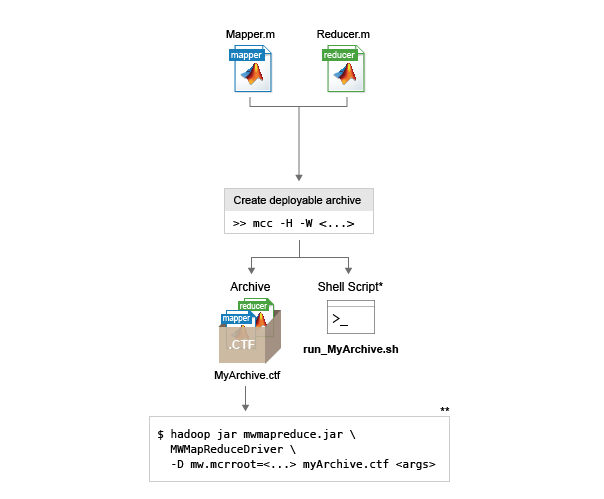
Напишите функции mapper и reducer в MATLAB®.
Создайте MAT-файл, содержащий datastore, который описывает структуру данных и имена переменных для анализа. datastore в MAT-файле может быть создан из тестовых данных набора, представляющего фактический набор данных.
Создайте текстовый файл, содержащий Hadoop® такие настройки, как имя отображателя, редуктор и тип анализируемых данных. Этот файл создается автоматически, если вы используете приложение Hadoop Compiler.
Используйте Hadoop Compiler приложение или mcc Команда для упаковки компонентов в развертываемый архив. Обе опции генерируют развертываемый архив (файл .ctf), который можно включить в задание mapreduce Hadoop.
Включите развертываемый архив в задание mapreduce Hadoop с помощью hadoop команда и синтаксис.
Подпись выполнения

Ключ
| Буква | Описание |
|---|---|
| A | Команда Hadoop |
| B | Опция JAR |
| C | Стандартное имя файла JAR. Все приложения имеют одинаковый JAR: mwmapreduce.jar.Настройка пути к JAR также фиксируется относительно местоположения MATLAB Runtime. |
| D | Стандартное имя драйвера. Все приложения имеют одинаковое имя драйвера: MWMapReduceDriver |
| E | Типовая опция, задающая расположение MATLAB Runtime в виде пары "ключ-значение". |
| F | Развертываемый архив (.ctf файл), сгенерированный приложением Hadoop Compiler или mcc передается как аргумент полезной нагрузки в задание. |
| G | Расположение файлов входа на HDFS™. |
| H | Расположение на HDFS, где можно записать вывод. |
Упрощение включения развертываемого архива (.ctf файл) в задание mapreduce Hadoop, как приложение Hadoop Compiler, так и приложение mcc команда сгенерирует интерпретатор наряду с развертываемым архивом. У интерпретатор скрипта есть следующее соглашение об именовании: run_<deployableArchiveName>.sh
Чтобы запустить развертываемый архив с помощью скрипта интерпретатора, используйте следующий синтаксис:

