В этой теме объясняется, как работать с данными последовательности и временных рядов для задач классификации и регрессии с использованием сетей долгой краткосрочной памяти (LSTM). Для примера, показывающего, как классифицировать данные последовательности с помощью сети LSTM, смотрите Классификацию последовательностей с использованием глубокого обучения.
Сеть LSTM является типом рекуррентной нейронной сети (RNN), который может изучать долгосрочные зависимости между временными шагами данных последовательности.
Основными компонентами сети LSTM являются входной слой последовательности и слой LSTM. Входной слой последовательности вводит данные последовательности или временных рядов в сеть. LSTM слоя изучает долгосрочные зависимости между временными шагами данных последовательности.
Эта схема иллюстрирует архитектуру простой сети LSTM для классификации. Сеть начинается с входного слоя последовательности, за которым следует слой LSTM. Чтобы предсказать метки класса, сеть заканчивается полносвязным слоем, слоем softmax и выходным слоем классификации.
![]()
Эта схема иллюстрирует архитектуру простой сети LSTM для регрессии. Сеть начинается с входного слоя последовательности, за которым следует слой LSTM. Сеть заканчивается полносвязным слоем и выходным слоем регрессии.
![]()
Эта схема иллюстрирует архитектуру сети для классификации видео. Чтобы ввести последовательности изображений в сеть, используйте входной слой последовательности. Чтобы использовать сверточные слои для извлечения функций, то есть для применения сверточных операций к каждой системе координат видео независимо, используйте слой складывания последовательности, за которым следуют сверточные слои, а затем слой развертывания последовательности. Чтобы использовать слои LSTM, чтобы узнать из последовательностей векторов, используйте плоский слой, за которым следуют LSTM и выходные слои.

Чтобы создать сеть LSTM для классификации «последовательность-метка», создайте массив слоев, содержащий входной слой последовательности, слой LSTM, полносвязный слой, слой softmax и выходной слой классификации.
Установите размер входного слоя последовательности равным количеству функций входных данных. Установите размер полносвязного слоя равным количеству классов. Вам не нужно указывать длину последовательности.
Для слоя LSTM задайте количество скрытых модулей измерения и режим выхода 'last'.
numFeatures = 12; numHiddenUnits = 100; numClasses = 9; layers = [ ... sequenceInputLayer(numFeatures) lstmLayer(numHiddenUnits,'OutputMode','last') fullyConnectedLayer(numClasses) softmaxLayer classificationLayer];
Для примера, показывающего, как обучить сеть LSTM для классификации «последовательность-метка» и классификации новых данных, смотрите Классификацию последовательностей с использованием глубокого обучения.
Чтобы создать сеть LSTM для классификации «последовательность-последовательность», используйте ту же архитектуру, что и для классификации «последовательность-метка», но установите выход режим слоя LSTM на 'sequence'.
numFeatures = 12; numHiddenUnits = 100; numClasses = 9; layers = [ ... sequenceInputLayer(numFeatures) lstmLayer(numHiddenUnits,'OutputMode','sequence') fullyConnectedLayer(numClasses) softmaxLayer classificationLayer];
Чтобы создать сеть LSTM для регрессии от последовательности к единице, создайте массив слоев, содержащий входной слой последовательности, слой LSTM, полносвязный слой и выходной слой регрессии.
Установите размер входного слоя последовательности равным количеству функций входных данных. Установите размер полностью подключенного слоя равным количеству откликов. Вам не нужно указывать длину последовательности.
Для слоя LSTM задайте количество скрытых модулей измерения и режим выхода 'last'.
numFeatures = 12; numHiddenUnits = 125; numResponses = 1; layers = [ ... sequenceInputLayer(numFeatures) lstmLayer(numHiddenUnits,'OutputMode','last') fullyConnectedLayer(numResponses) regressionLayer];
Чтобы создать сеть LSTM для регрессии между последовательностями, используйте ту же архитектуру, что и для регрессии между последовательностями, но установите выход режим слоя LSTM на 'sequence'.
numFeatures = 12; numHiddenUnits = 125; numResponses = 1; layers = [ ... sequenceInputLayer(numFeatures) lstmLayer(numHiddenUnits,'OutputMode','sequence') fullyConnectedLayer(numResponses) regressionLayer];
Для примера, показывающего, как обучить сеть LSTM для регрессии между последовательностями и предсказать на новых данных, смотрите Регрессию между последовательностями с использованием глубокого обучения.
Чтобы создать нейронную сеть для глубокого обучения для данных, содержащих последовательности изображений, таких как видеоданные и медицинские изображения, задайте вход последовательности изображений с помощью входного слоя последовательности.
Чтобы использовать сверточные слои для извлечения функций, то есть для применения сверточных операций к каждой системе координат видео независимо, используйте слой складывания последовательности, за которым следуют сверточные слои, а затем слой развертывания последовательности. Чтобы использовать слои LSTM, чтобы узнать из последовательностей векторов, используйте плоский слой, за которым следуют LSTM и выходные слои.
inputSize = [28 28 1]; filterSize = 5; numFilters = 20; numHiddenUnits = 200; numClasses = 10; layers = [ ... sequenceInputLayer(inputSize,'Name','input') sequenceFoldingLayer('Name','fold') convolution2dLayer(filterSize,numFilters,'Name','conv') batchNormalizationLayer('Name','bn') reluLayer('Name','relu') sequenceUnfoldingLayer('Name','unfold') flattenLayer('Name','flatten') lstmLayer(numHiddenUnits,'OutputMode','last','Name','lstm') fullyConnectedLayer(numClasses, 'Name','fc') softmaxLayer('Name','softmax') classificationLayer('Name','classification')];
Преобразуйте слои в график слоев и соедините miniBatchSize выход слоя складывания последовательности на соответствующий вход слоя развертывания последовательности.
lgraph = layerGraph(layers); lgraph = connectLayers(lgraph,'fold/miniBatchSize','unfold/miniBatchSize');
Пример, показывающий, как обучить нейронную сеть для глубокого обучения для классификации видео, см. в разделе Классификация видео с использованием глубокого обучения.
Можно сделать сети LSTM глубже, вставив дополнительные слои LSTM с выходом режимом 'sequence' перед слоем LSTM. Чтобы предотвратить сверхподбор кривой, можно вставить слои выпадающего списка после слоев LSTM.
Для сетей классификации «последовательность-метка» должен быть 'last' режим выхода последнего слоя LSTM.
numFeatures = 12; numHiddenUnits1 = 125; numHiddenUnits2 = 100; numClasses = 9; layers = [ ... sequenceInputLayer(numFeatures) lstmLayer(numHiddenUnits1,'OutputMode','sequence') dropoutLayer(0.2) lstmLayer(numHiddenUnits2,'OutputMode','last') dropoutLayer(0.2) fullyConnectedLayer(numClasses) softmaxLayer classificationLayer];
Для сетей классификации «последовательность-последовательность» должен быть 'sequence' выход последнего слоя LSTM.
numFeatures = 12; numHiddenUnits1 = 125; numHiddenUnits2 = 100; numClasses = 9; layers = [ ... sequenceInputLayer(numFeatures) lstmLayer(numHiddenUnits1,'OutputMode','sequence') dropoutLayer(0.2) lstmLayer(numHiddenUnits2,'OutputMode','sequence') dropoutLayer(0.2) fullyConnectedLayer(numClasses) softmaxLayer classificationLayer];
| Слой | Описание |
|---|---|
| Входной слой последовательности вводит данные последовательности в сеть. | |
| LSTM слоя изучает долгосрочные зависимости между временными шагами во временных рядах и данными последовательности. | |
| Двунаправленный слой LSTM (BiLSTM) изучает двунаправленные долгосрочные зависимости между временными шагами временных рядов или данных последовательности. Эти зависимости могут быть полезны, когда необходимо, чтобы сеть училась из полных временных рядов на каждом временном шаге. | |
| GRU слоя изучает зависимости между временными шагами во временных рядах и данными последовательности. | |
| Слой складывания последовательности преобразует пакет последовательностей изображений в пакет изображений. Используйте слой складывания последовательности для выполнения операций свертки на временных шагах последовательностей изображений независимо. | |
| Слой развертывания последовательности восстанавливает структуру последовательности входных данных после складывания последовательности. | |
| Плоский слой сворачивает пространственные размерности входа в размерность канала. | |
| Слой встраивания слов сопоставляет индексы слов с векторами. |
Чтобы классифицировать или делать предсказания по новым данным, используйте classify и predict.
Сети LSTM могут запоминать состояние сети между предсказаниями. Сетевое состояние полезно, когда у вас нет полного временного ряда заранее, или если вы хотите сделать несколько предсказаний на длинных временных рядах.
Чтобы предсказать и классифицировать части временных рядов и обновить состояние сети, используйте predictAndUpdateState и classifyAndUpdateState. Чтобы сбросить сетевое состояние между предсказаниями, используйте resetState.
Для примера, показывающего, как предсказать будущие временные шаги последовательности, смотрите Прогнозирование временных рядов с использованием глубокого обучения.
Сети LSTM поддерживают входные данные с различными длинами последовательности. При передаче данных через сеть программное обеспечение заполняет, обрезает или разделяет последовательности так, чтобы все последовательности в каждом мини-пакете имели заданную длину. Можно задать длины последовательности и значение, используемое для заполнения последовательностей с помощью SequenceLength и SequencePaddingValue аргументы пары "имя-значение" в trainingOptions.
После обучения сети используйте тот же мини-размер пакета и опции заполнения при использовании classify, predict, classifyAndUpdateState, predictAndUpdateState, и activations функций.
Чтобы уменьшить объем заполнения или отброшенных данных при заполнении или усечении последовательностей, попробуйте отсортировать данные по длине последовательности. Чтобы отсортировать данные по длине последовательности, сначала получите количество столбцов каждой последовательности путем применения size(X,2) к каждой последовательности используя cellfun. Затем отсортируйте длины последовательности, используя sort, и используйте второй выход, чтобы переупорядочить исходные последовательности.
sequenceLengths = cellfun(@(X) size(X,2), XTrain); [sequenceLengthsSorted,idx] = sort(sequenceLengths); XTrain = XTrain(idx);
Следующие рисунки показывают длины последовательности отсортированных и несортированных данных на столбчатых диаграммах.

Если вы задаете длину последовательности 'longest'Затем программа заполняет последовательности так, чтобы все последовательности в мини-пакете имели ту же длину, что и самая длинная последовательность в мини-пакете. Эта опция является опцией по умолчанию.
Следующие рисунки иллюстрируют эффект настройки 'SequenceLength' на 'longest'.

Если вы задаете длину последовательности 'shortest'Затем программа обрезает последовательности так, чтобы все последовательности в мини-пакете имели ту же длину, что и самая короткая последовательность в этом мини-пакете. Оставшиеся данные в последовательностях отбрасываются.
Следующие рисунки иллюстрируют эффект настройки 'SequenceLength' на 'shortest'.

Если вы задаете длину последовательности в целое число значения, то программное обеспечение заполняет все последовательности в мини-пакете самым близким кратным указанной длине, которая больше самой длинной длины последовательности в мини-пакете. Затем программа разделяет каждую последовательность на меньшие последовательности заданной длины. Если происходит разделение, то программное обеспечение создает дополнительные мини-пакеты.
Используйте эту опцию, если полные последовательности не помещаются в памяти. Кроме того, можно попробовать уменьшить количество последовательностей на мини-пакет, установив 'MiniBatchSize' опция в trainingOptions к более низкому значению.
Если вы задаете длину последовательности как положительное целое число, то программное обеспечение обрабатывает меньшие последовательности в последовательных итерациях. Сеть обновляет состояние сети между разделенными последовательностями.
Следующие рисунки иллюстрируют эффект настройки 'SequenceLength' по 5.

Расположение заполнения и усечения может повлиять на обучение, классификацию и точность предсказания. Попробуйте задать 'SequencePaddingDirection' опция в trainingOptions на 'left' или 'right' и посмотрите, что лучше всего подходит для ваших данных.
Потому что слои LSTM обрабатывают данные последовательности по одному временному шагу за раз, когда слой OutputMode свойство 'last'любое заполнение на последних временных шагах может отрицательно повлиять на выход слоя. Чтобы дополнить или обрезать данные последовательности слева, установите 'SequencePaddingDirection' опция для 'left'.
Для сетей от последовательности к последовательности (когда OutputMode свойство 'sequence' для каждого слоя LSTM), любое заполнение в первые временные шаги может негативно повлиять на предсказания для более ранних временных шагов. Чтобы дополнить или обрезать данные последовательности справа, установите 'SequencePaddingDirection' опция для 'right'.
Следующие рисунки иллюстрируют данные последовательности заполнения слева и справа.

Следующие рисунки иллюстрируют усечение данных последовательности слева и справа.

Чтобы автоматически восстановить обучающие данные во время обучения с помощью нормализации с нулевым центром, установите Normalization опция sequenceInputLayer на 'zerocenter'. Кроме того, можно нормализовать данные последовательности путем вычисления сначала среднего по признаку и стандартного отклонения всех последовательностей. Затем для каждого обучающего наблюдения вычитайте среднее значение и разделите на стандартное отклонение.
mu = mean([XTrain{:}],2);
sigma = std([XTrain{:}],0,2);
XTrain = cellfun(@(X) (X-mu)./sigma,XTrain,'UniformOutput',false);Используйте хранилища данных для последовательности, временных рядов и данных о сигнале, когда данные слишком большие, чтобы помещаться в памяти, или чтобы выполнить определенные операции при считывании пакетов данных.
Дополнительные сведения см. в разделе Train сети с использованием данных последовательности за пределами памяти и классификация текстовых данных за пределами памяти с помощью глубокого обучения.
Исследуйте и визуализируйте функции, выученные сетями LSTM из данных последовательности и временных рядов, путем извлечения активаций с помощью activations функция. Дополнительные сведения см. в разделе Визуализация активации сети LSTM.
Эта схема иллюстрирует поток временных рядов, X с C функциями (каналами) длины, S через слой LSTM. В схеме, и обозначает выход (также известный как скрытое состояние) и состояние камеры на временном шаге t, соответственно.
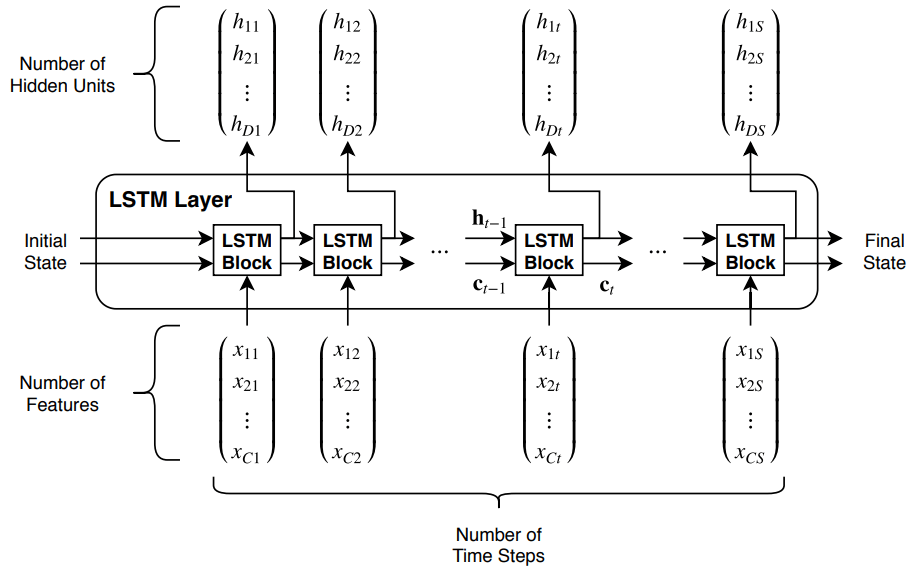
Первый блок LSTM использует начальное состояние сети и первый временной шаг последовательности, чтобы вычислить первый выход и обновленное состояние камеры. Во временной шаг t блок использует текущее состояние сети и следующий временной шаг последовательности для вычисления выхода и обновленного состояния камеры .
Состояние слоя состоит из скрытого состояния (также известного как выход состояние) и камера состояния. Скрытое состояние на временном шаге t содержит выход слоя LSTM для этого временного шага. Состояние камеры содержит информацию, полученную из предыдущих временных шагов. На каждом временном шаге слой добавляет информацию в или удаляет информацию из состояния камеры. Слой управляет этими обновлениями с помощью ворот.
Следующие компоненты управляют состоянием камер и скрытым состоянием слоя.
| Компонент | Цель |
|---|---|
| Входной затвор (i) | Управляйте уровнем обновления состояния камеры |
| Забудьте ворота (f) | Управляйте уровнем сброса состояния камеры (забудьте) |
| Кандидат в камеру (g) | Добавьте информацию в состояние камеры |
| Выходной затвор (o) | Управляйте уровнем состояния камеры, добавленной к скрытому состоянию |
Эта схема иллюстрирует поток данных во временной шаг t. Схема подсвечивает, как ворота забывают, обновляют, и выводят камеру и скрытые состояния.
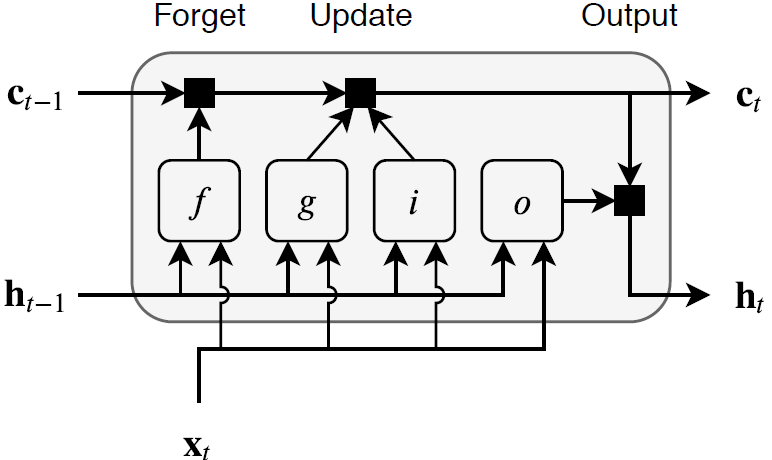
Обучаемые веса слоя LSTM являются входными весами W (InputWeights), периодические веса R (RecurrentWeights), и смещение b (Bias). Матрицы W, R и b являются конкатенациями входных весов, рекуррентных весов и смещения каждого компонента, соответственно. Эти матрицы объединяются следующим образом:
где i, f, g и o обозначают входной затвор, забыть затвор, кандидата камеры и выходной затвор, соответственно.
Состояние камеры на временном шаге t задается как
где обозначает продукт Адамара (поэлементное умножение векторов).
Скрытое состояние во временной шаг t задается как
где обозначает функцию активации состояния. The lstmLayer функция по умолчанию использует гиперболическую тангенциальную функцию (tanh), чтобы вычислить функцию активации состояния.
Следующие формулы описывают компоненты на временном шаге t.
| Компонент | Формула |
|---|---|
| Входной затвор | |
| Забудьте ворота | |
| Кандидат в камеры | |
| Выходной затвор |
В этих вычислениях, обозначает функцию активации затвора. The lstmLayer функция по умолчанию использует сигмоидную функцию, заданную как для вычисления функции активации затвора.
[1] Hochreiter, S., and J. Schmidhuber. «Долгая краткосрочная память». Нейронные расчеты. Том 9, № 8, 1997, ср.1735 - 1780.
activations | bilstmLayer | classifyAndUpdateState | flattenLayer | gruLayer | lstmLayer | predictAndUpdateState | resetState | sequenceFoldingLayer | sequenceInputLayer | sequenceUnfoldingLayer | wordEmbeddingLayer (Symbolic Math Toolbox)
