Долгая краткосрочная память (LSTM) слоя
LSTM слоя изучает долгосрочные зависимости между временными шагами во временных рядах и данными последовательности.
Слой выполняет аддитивные взаимодействия, которые могут помочь улучшить градиентный поток в длинных последовательностях во время обучения.
layer = lstmLayer(numHiddenUnits)NumHiddenUnits свойство.
layer = lstmLayer(numHiddenUnits,Name,Value)OutputMode, Активации, Состояние, Параметры и Инициализация, Скорость Обучения и Регуляризация, и Name свойства с использованием одного или нескольких аргументов пары "имя-значение". Можно задать несколько аргументы пары "имя-значение". Заключайте каждое имя свойства в кавычки.
Создайте слой LSTM с именем 'lstm1' и 100 скрытые модули.
layer = lstmLayer(100,'Name','lstm1')
layer =
LSTMLayer with properties:
Name: 'lstm1'
Hyperparameters
InputSize: 'auto'
NumHiddenUnits: 100
OutputMode: 'sequence'
StateActivationFunction: 'tanh'
GateActivationFunction: 'sigmoid'
Learnable Parameters
InputWeights: []
RecurrentWeights: []
Bias: []
State Parameters
HiddenState: []
CellState: []
Show all properties
Включите слой LSTM в Layer массив.
inputSize = 12;
numHiddenUnits = 100;
numClasses = 9;
layers = [ ...
sequenceInputLayer(inputSize)
lstmLayer(numHiddenUnits)
fullyConnectedLayer(numClasses)
softmaxLayer
classificationLayer]layers =
5x1 Layer array with layers:
1 '' Sequence Input Sequence input with 12 dimensions
2 '' LSTM LSTM with 100 hidden units
3 '' Fully Connected 9 fully connected layer
4 '' Softmax softmax
5 '' Classification Output crossentropyex
Обучите сеть LSTM глубокого обучения для классификации «последовательность-метка».
Загрузите набор данных японских гласных, как описано в [1] и [2]. XTrain - массив ячеек, содержащий 270 последовательностей различной длины с 12 функциями, соответствующими коэффициентам cepstrum LPC. Y является категориальным вектором меток 1,2,..., 9. Записи в XTrain являются матрицами с 12 строками (по одной строке для каждой функции) и меняющимся количеством столбцов (по одному столбцу для каждого временного шага).
[XTrain,YTrain] = japaneseVowelsTrainData;
Визуализируйте первые временные ряды на графике. Каждая линия соответствует функции.
figure
plot(XTrain{1}')
title("Training Observation 1")
numFeatures = size(XTrain{1},1);
legend("Feature " + string(1:numFeatures),'Location','northeastoutside')
Определите сетевую архитектуру LSTM. Задайте размер входа как 12 (количество функций входных данных). Задайте слой LSTM, который будет иметь 100 скрытые модули измерения и выводить последний элемент последовательности. Наконец, задайте девять классов, включив полностью соединенный слой размера 9, затем слой softmax и слой классификации.
inputSize = 12; numHiddenUnits = 100; numClasses = 9; layers = [ ... sequenceInputLayer(inputSize) lstmLayer(numHiddenUnits,'OutputMode','last') fullyConnectedLayer(numClasses) softmaxLayer classificationLayer]
layers =
5×1 Layer array with layers:
1 '' Sequence Input Sequence input with 12 dimensions
2 '' LSTM LSTM with 100 hidden units
3 '' Fully Connected 9 fully connected layer
4 '' Softmax softmax
5 '' Classification Output crossentropyex
Задайте опции обучения. Задайте решатель следующим 'adam' и 'GradientThreshold' как 1. Установите размер мини-пакета равным 27 и установите максимальное количество эпох равным 70.
Поскольку мини-пакеты являются маленькими с короткими последовательностями, центральный процессор лучше подходит для обучения. Задайте 'ExecutionEnvironment' на 'cpu'. Для обучения на графическом процессоре, при наличии, установите 'ExecutionEnvironment' на 'auto' (значение по умолчанию).
maxEpochs = 70; miniBatchSize = 27; options = trainingOptions('adam', ... 'ExecutionEnvironment','cpu', ... 'MaxEpochs',maxEpochs, ... 'MiniBatchSize',miniBatchSize, ... 'GradientThreshold',1, ... 'Verbose',false, ... 'Plots','training-progress');
Обучите сеть LSTM с заданными опциями обучения.
net = trainNetwork(XTrain,YTrain,layers,options);

Загрузите тестовый набор и классифицируйте последовательности в динамики.
[XTest,YTest] = japaneseVowelsTestData;
Классификация тестовых данных. Укажите тот же размер мини-пакета, что и для обучения.
YPred = classify(net,XTest,'MiniBatchSize',miniBatchSize);Вычислите классификационную точность предсказаний.
acc = sum(YPred == YTest)./numel(YTest)
acc = 0.9514
Чтобы создать сеть LSTM для классификации «последовательность-метка», создайте массив слоев, содержащий входной слой последовательности, слой LSTM, полносвязный слой, слой softmax и выходной слой классификации.
Установите размер входного слоя последовательности равным количеству функций входных данных. Установите размер полносвязного слоя равным количеству классов. Вам не нужно указывать длину последовательности.
Для слоя LSTM задайте количество скрытых модулей измерения и режим выхода 'last'.
numFeatures = 12; numHiddenUnits = 100; numClasses = 9; layers = [ ... sequenceInputLayer(numFeatures) lstmLayer(numHiddenUnits,'OutputMode','last') fullyConnectedLayer(numClasses) softmaxLayer classificationLayer];
Для примера, показывающего, как обучить сеть LSTM для классификации «последовательность-метка» и классификации новых данных, смотрите Классификацию последовательностей с использованием глубокого обучения.
Чтобы создать сеть LSTM для классификации «последовательность-последовательность», используйте ту же архитектуру, что и для классификации «последовательность-метка», но установите выход режим слоя LSTM на 'sequence'.
numFeatures = 12; numHiddenUnits = 100; numClasses = 9; layers = [ ... sequenceInputLayer(numFeatures) lstmLayer(numHiddenUnits,'OutputMode','sequence') fullyConnectedLayer(numClasses) softmaxLayer classificationLayer];
Чтобы создать сеть LSTM для регрессии от последовательности к единице, создайте массив слоев, содержащий входной слой последовательности, слой LSTM, полносвязный слой и выходной слой регрессии.
Установите размер входного слоя последовательности равным количеству функций входных данных. Установите размер полностью подключенного слоя равным количеству откликов. Вам не нужно указывать длину последовательности.
Для слоя LSTM задайте количество скрытых модулей измерения и режим выхода 'last'.
numFeatures = 12; numHiddenUnits = 125; numResponses = 1; layers = [ ... sequenceInputLayer(numFeatures) lstmLayer(numHiddenUnits,'OutputMode','last') fullyConnectedLayer(numResponses) regressionLayer];
Чтобы создать сеть LSTM для регрессии между последовательностями, используйте ту же архитектуру, что и для регрессии между последовательностями, но установите выход режим слоя LSTM на 'sequence'.
numFeatures = 12; numHiddenUnits = 125; numResponses = 1; layers = [ ... sequenceInputLayer(numFeatures) lstmLayer(numHiddenUnits,'OutputMode','sequence') fullyConnectedLayer(numResponses) regressionLayer];
Для примера, показывающего, как обучить сеть LSTM для регрессии между последовательностями и предсказать на новых данных, смотрите Регрессию между последовательностями с использованием глубокого обучения.
Можно сделать сети LSTM глубже, вставив дополнительные слои LSTM с выходом режимом 'sequence' перед слоем LSTM. Чтобы предотвратить сверхподбор кривой, можно вставить слои выпадающего списка после слоев LSTM.
Для сетей классификации «последовательность-метка» должен быть 'last' режим выхода последнего слоя LSTM.
numFeatures = 12; numHiddenUnits1 = 125; numHiddenUnits2 = 100; numClasses = 9; layers = [ ... sequenceInputLayer(numFeatures) lstmLayer(numHiddenUnits1,'OutputMode','sequence') dropoutLayer(0.2) lstmLayer(numHiddenUnits2,'OutputMode','last') dropoutLayer(0.2) fullyConnectedLayer(numClasses) softmaxLayer classificationLayer];
Для сетей классификации «последовательность-последовательность» должен быть 'sequence' выход последнего слоя LSTM.
numFeatures = 12; numHiddenUnits1 = 125; numHiddenUnits2 = 100; numClasses = 9; layers = [ ... sequenceInputLayer(numFeatures) lstmLayer(numHiddenUnits1,'OutputMode','sequence') dropoutLayer(0.2) lstmLayer(numHiddenUnits2,'OutputMode','sequence') dropoutLayer(0.2) fullyConnectedLayer(numClasses) softmaxLayer classificationLayer];
LSTM слоя изучает долгосрочные зависимости между временными шагами во временных рядах и данными последовательности.
Состояние слоя состоит из скрытого состояния (также известного как выход состояние) и камера состояния. Скрытое состояние на временном шаге t содержит выход слоя LSTM для этого временного шага. Состояние камеры содержит информацию, полученную из предыдущих временных шагов. На каждом временном шаге слой добавляет информацию в или удаляет информацию из состояния камеры. Слой управляет этими обновлениями с помощью ворот.
Следующие компоненты управляют состоянием камер и скрытым состоянием слоя.
| Компонент | Цель |
|---|---|
| Входной затвор (i) | Управляйте уровнем обновления состояния камеры |
| Забудьте ворота (f) | Управляйте уровнем сброса состояния камеры (забудьте) |
| Кандидат в камеру (g) | Добавьте информацию в состояние камеры |
| Выходной затвор (o) | Управляйте уровнем состояния камеры, добавленной к скрытому состоянию |
Эта схема иллюстрирует поток данных во временной шаг t. Схема подсвечивает, как ворота забывают, обновляют, и выводят камеру и скрытые состояния.
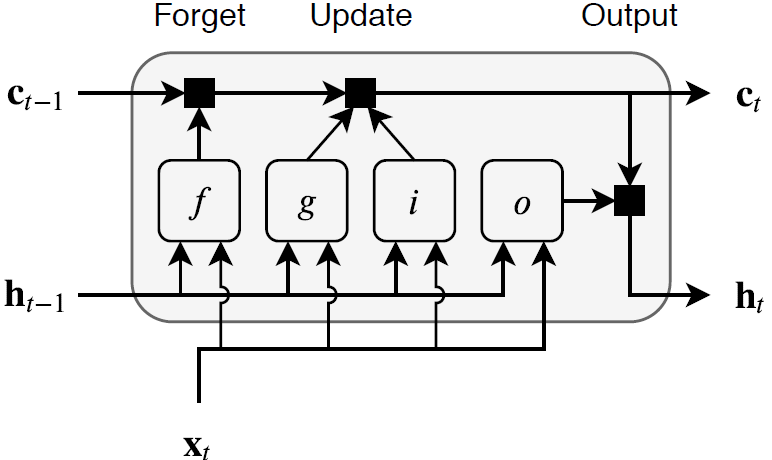
Обучаемые веса слоя LSTM являются входными весами W (InputWeights), периодические веса R (RecurrentWeights), и смещение b (Bias). Матрицы W, R и b являются конкатенациями входных весов, рекуррентных весов и смещения каждого компонента, соответственно. Эти матрицы объединяются следующим образом:
где i, f, g и o обозначают входной затвор, забыть затвор, кандидата камеры и выходной затвор, соответственно.
Состояние камеры на временном шаге t задается как
где обозначает продукт Адамара (поэлементное умножение векторов).
Скрытое состояние во временной шаг t задается как
где обозначает функцию активации состояния. The lstmLayer функция по умолчанию использует гиперболическую тангенциальную функцию (tanh), чтобы вычислить функцию активации состояния.
Следующие формулы описывают компоненты на временном шаге t.
| Компонент | Формула |
|---|---|
| Входной затвор | |
| Забудьте ворота | |
| Кандидат в камеры | |
| Выходной затвор |
В этих вычислениях, обозначает функцию активации затвора. The lstmLayer функция по умолчанию использует сигмоидную функцию, заданную как для вычисления функции активации затвора.
[1] М. Кудо, Дж. Тояма и М. Симбо. «Многомерная классификация кривых с использованием областей». Распознавание Букв. Том 20, № 11-13, стр. 1103-1111.
[2] UCI Machine Learning Repository: Японский набор данных гласных. https://archive.ics.uci.edu/ml/datasets/Japanese+Vowels
[3] Hochreiter, S, and J. Schmidhuber, 1997. Долгая краткосрочная память. Нейронные расчеты, 9 (8), стр. 1735-1780.
[4] Глорот, Ксавьер и Йошуа Бенгио. «Понимание сложности обучения нейронных сетей с глубоким Feedforward». В работе тринадцатой Международной конференции по искусственному интеллекту и статистике, 249-356. Сардиния, Италия: AISTATS, 2010.
[5] He, Kaiming, Xiangyu Zhang, Shaoqing Ren, and Jian Sun. «Delving Deep Into Rectifiers: Overpassing Human-Level Performance on ImageNet Classification». В работе Международной конференции IEEE по компьютерному зрению 2015 года, 1026-1034. Вашингтон, округ Колумбия: IEEE Компьютерное Зрение Society, 2015.
[6] Saxe, Andrew M., James L. McClelland, and Surya Ganguli. «Точные решения нелинейной динамики обучения в глубоких линейных нейронных сетях» .arXiv preprint arXiv:1312.6120 (2013).
bilstmLayer | classifyAndUpdateState | Deep Network Designer | flattenLayer | gruLayer | predictAndUpdateState | resetState | sequenceFoldingLayer | sequenceInputLayer | sequenceUnfoldingLayer
