Вероятностные нейронные сети могут использоваться для задач классификации. Когда представлен вход, первый слой вычисляет расстояния от входного вектора до обучающих входных векторов и производит вектор, элементы которого указывают, насколько близок вход к обучающему входу. Второй слой суммирует эти вклады для каждого класса входов, чтобы создать в качестве чистого выхода вектор вероятностей. Наконец, передаточная функция на выходе второго слоя выбирает максимум этих вероятностей и создает 1 для этого класса и 0 для других классов. Архитектура этой системы показана ниже.
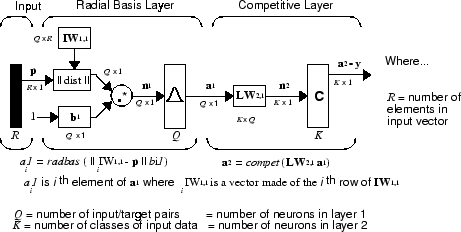
Принято, что существует Q пары входной вектор/целевой вектор. Каждый целевой вектор имеет K элементы. Один из этих элементов равен 1, а остальные равны 0. Таким образом, каждый входной вектор связан с одним из K классы.
Входные веса первого уровня, IW1,1 (net.IW{1,1}), устанавливаются в транспонирование матрицы, образованной из Q пар обучения, P '. Когда вход представлен, ||
dist
|| прямоугольник создает вектор, элементы которого указывают, насколько близок вход к векторам набора обучающих данных. Эти элементы умножаются, элемент за элементом, на смещение и отправляются в radbas передаточная функция. Вектор входа, близкий к обучающему вектору, представлен числом, близким к 1 в векторе выхода a1. Если вход близок к нескольким обучающим векторам одного класса, он представлен несколькими элементами массива1 которые близки к 1.
Веса второго слоя, LW1,2 (net.LW{2,1}), устанавливаются в матрицу T целевых векторов. Каждый вектор имеет только 1 в строке, сопоставленной с этим конкретным классом входов, и 0 в другом месте. (Используйте функцию ind2vec для создания соответствующих векторов.) Умножение Та1 суммирует элементы массива1 из-за каждого из K входные классы. Наконец, передаточная функция второго уровня, compet, создает 1, соответствующее наибольшему элементу n2, и 0s в другом месте. Таким образом, сеть классифицирует вектор входа в конкретное K класс, поскольку этот класс имеет максимальную вероятность быть правильным.
Вы можете использовать функцию newpnn для создания PNN. Например, предположим, что семь входных векторов и их соответствующие цели
P = [0 0;1 1;0 3;1 4;3 1;4 1;4 3]'
который дает
P =
0 1 0 1 3 4 4
0 1 3 4 1 1 3
Tc = [1 1 2 2 3 3 3]
который дает
Tc =
1 1 2 2 3 3 3
Вам нужна целевая матрица с 1s в нужные области кадра. Вы можете получить его с функцией ind2vec. Это дает матрицу с 0 с, кроме как в правильных точках. Так что выполните
T = ind2vec(Tc)
который дает
T = (1,1) 1 (1,2) 1 (2,3) 1 (2,4) 1 (3,5) 1 (3,6) 1 (3,7) 1
Теперь можно создать сеть и моделировать ее, используя вход P убедиться, что он действительно создает правильные классификации. Используйте функцию vec2ind для преобразования выхода Y в строку Yc для уточнения классификаций.
net = newpnn(P,T); Y = sim(net,P); Yc = vec2ind(Y)
Это создает
Yc =
1 1 2 2 3 3 3
Можно попробовать классифицировать векторы, отличные от тех, которые использовались для проектирования сети. Попытайтесь классифицировать векторы, показанные ниже в P2.
P2 = [1 4;0 1;5 2]'
P2 =
1 0 5
4 1 2
Можете угадать, как эти векторы будут классифицированы? Если вы запускаете симуляцию и строите график векторов, как и прежде, вы получаете
Yc =
2 1 3
Эти результаты выглядят хорошо, поскольку эти тестовые векторы были довольно близки к представителям классов 2, 1 и 3 соответственно. Сети удалось обобщить свою операцию, чтобы правильно классифицировать векторы, отличные от тех, которые используются для проектирования сети.
Можно хотеть попробовать классификацию PNN. Он показывает, как спроектировать PNN и как сеть может успешно классифицировать вектор, не используемый в проекте.
