По мере того, как количество и тип устройств сбора данных ежегодно увеличивается, максимальный размер и скорость сбора данных быстро расширяются. Эти наборы больших данных могут содержать гигабайты или терабайты данных, и могут расти порядка мегабайт или гигабайт в день. Хотя набор этой информации открывает возможности для понимания, он также создает множество проблем. Большинство алгоритмов не предназначены для обработки наборов больших данных за разумное время или с разумным объемом памяти. MapReduce позволяет вам справиться со многими из этих проблем, чтобы получить важное представление о больших наборах данных.
MapReduce является методом программирования для анализа наборов данных, которые не помещаются в памяти. Вы можете ознакомиться с Hadoop® MapReduce, который является популярной реализацией, которая работает с распределенной файловой системой Hadoop (HDFS™). MATLAB® обеспечивает несколько другую реализацию метода MapReduce с mapreduce функция.
mapreduce использует datastore для обработки данных в небольших блоках, которые индивидуально помещаются в память. Каждый блок проходит фазу Map, которая форматирует данные, которые будут обработаны. Затем промежуточные блоки данных проходят фазу Reduce, которая агрегирует промежуточные результаты, чтобы получить конечный результат. Фазы Map и Reduce кодируются функциями map и reduce, которые являются первичными входными параметрами к mapreduce. Существуют бесконечные комбинации функций map и reduce для обработки данных, поэтому этот метод является как гибким, так и чрезвычайно мощным для решения больших задач обработки данных.
mapreduce позволяет расширяться для запуска в нескольких окружениях. Дополнительные сведения об этих возможностях см. в разделах Ускорение и Развертывание MapReduce с использованием других продуктов.
Утилита mapreduce функция заключается в ее способности выполнять вычисления на больших наборах данных. Таким образом, mapreduce не подходит для выполнения вычислений на наборах данных нормальных размеров, которые могут быть загружены непосредственно в память компьютера и проанализированы традиционными методами. Вместо этого используйте mapreduce для выполнения статистического или аналитического вычисления на наборе данных, который не помещается в памяти.
Каждый вызов карты или функции уменьшения на mapreduce не зависит от всех остальных. Для примера вызов функции map не может зависеть от входов или результатов предыдущего вызова функции map. Лучше всего разбить такие вычисления на несколько вызовов к mapreduce.
mapreduce перемещает каждый блок данных в вход datastore через несколько фаз до достижения конечного выхода. Следующий рисунок описывает фазы алгоритма для mapreduce.
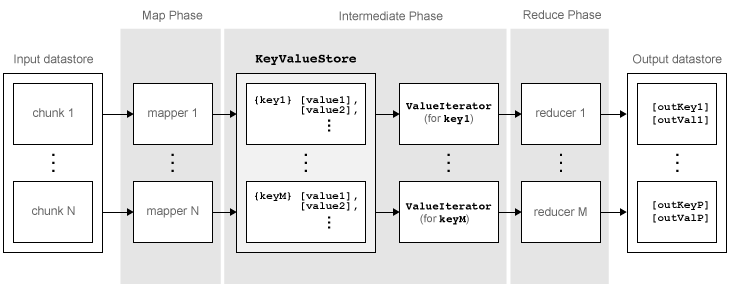
Алгоритм имеет следующие шаги:
mapreduce считывает блок данных из входа datastore используя [data,info] = read(ds), а затем вызывает функцию map, чтобы работать с этим блоком.
Функция map получает блок данных, организует его или выполняет предварительное вычисление, а затем использует add и addmulti функции для добавления пар "ключ-значение" к промежуточному объекту хранения данных, называемому KeyValueStore. Количество вызовов функции map по mapreduce равно количеству блоков в вход datastore.
После того, как функция map работает со всеми блоками данных в datastore, mapreduce группирует все значения в промежуточном KeyValueStore объект уникальным ключом.
Далее, mapreduce вызывает функцию reduce один раз для каждого уникального ключа, добавленного функцией map. Каждый уникальный ключ может иметь много связанных значений. mapreduce передает значения в функцию сокращения как ValueIterator объект, который является объектом, используемым для итерации по значениям. The ValueIterator объект для каждого уникального ключа содержит все связанные значения для этого ключа.
Функция сокращения использует hasnext и getnext функции для итерации значений в ValueIterator объект по одному за раз. Затем, после агрегирования промежуточных результатов из функции map, функция reduce добавляет конечные пары "ключ-значение" к выходу, используя add и addmulti функций. Порядок клавиш в выходе совпадает с порядком, в котором функция reduce добавляет их к конечной KeyValueStore объект. То есть, mapreduce не сортирует выходы явным образом.
Примечание
Функция сокращения записывает последние пары "ключ-значение" в конечное KeyValueStore объект. От этого объекта, mapreduce тянет пары "ключ-значение" в выход datastore, который является KeyValueDatastore объект по умолчанию.
Этот пример использует простое вычисление (среднее расстояние в наборе данных о рейсе), чтобы проиллюстрировать шаги, необходимые для запуска mapreduce.
Первый шаг к использованию mapreduce создает datastore для набора данных. Наряду с функциями map и reduce, datastore для набора данных является необходимым входом к mapreduce, поскольку это позволяет mapreduce для обработки данных в блоках.
mapreduce работает с большинством типов хранилищ данных. Для примера создайте TabularTextDatastore объект для airlinesmall.csv набор данных.
ds = tabularTextDatastore('airlinesmall.csv','TreatAsMissing','NA')
ds =
TabularTextDatastore with properties:
Files: {
' ...\matlab\toolbox\matlab\demos\airlinesmall.csv'
}
Folders: {
' ...\matlab\toolbox\matlab\demos'
}
FileEncoding: 'UTF-8'
AlternateFileSystemRoots: {}
PreserveVariableNames: false
ReadVariableNames: true
VariableNames: {'Year', 'Month', 'DayofMonth' ... and 26 more}
DatetimeLocale: en_US
Text Format Properties:
NumHeaderLines: 0
Delimiter: ','
RowDelimiter: '\r\n'
TreatAsMissing: 'NA'
MissingValue: NaN
Advanced Text Format Properties:
TextscanFormats: {'%f', '%f', '%f' ... and 26 more}
TextType: 'char'
ExponentCharacters: 'eEdD'
CommentStyle: ''
Whitespace: ' \b\t'
MultipleDelimitersAsOne: false
Properties that control the table returned by preview, read, readall:
SelectedVariableNames: {'Year', 'Month', 'DayofMonth' ... and 26 more}
SelectedFormats: {'%f', '%f', '%f' ... and 26 more}
ReadSize: 20000 rows
OutputType: 'table'
RowTimes: []
Write-specific Properties:
SupportedOutputFormats: ["txt" "csv" "xlsx" "xls" "parquet" "parq"]
DefaultOutputFormat: "txt"Несколько из ранее описанных опций полезны в контексте mapreduce. mapreduce выполнение функции read на datastore, чтобы извлечь данные для передачи в функцию map. Поэтому можно использовать SelectedVariableNames, SelectedFormats, и ReadSize опции, чтобы непосредственно сконфигурировать размер и тип данных блока, которые mapreduce переходит к функции map.
Например, чтобы выбрать Distance (общее расстояние рейса) переменная как единственная интересующая переменная, задайте SelectedVariableNames.
ds.SelectedVariableNames = 'Distance';Теперь, всякий раз, когда read, readall, или preview функции действуют на ds, они будут возвращать только информацию для Distance переменная. Чтобы подтвердить это, можно предворительно просмотреть первые несколько строк данных в datastore. Это позволяет вам изучить формат данных, которые mapreduce функция перейдет в функцию map.
preview(ds)
ans =
8×1 table
Distance
________
308
296
480
296
373
308
447
954 Чтобы просмотреть точные данные, которые mapreduce перейдет в функцию map, используйте read.
Для получения дополнительной информации и полных сводных данных по доступным опциям смотрите Datastore.
mapreduce функция автоматически вызывает карту и уменьшает функции во время выполнения, поэтому эти функции должны соответствовать определенным требованиям, чтобы работать правильно.
Входы в функцию map data, info, и intermKVStore:
data и info являются результатом вызова на read функцию на входе datastore, которая mapreduce выполняется автоматически перед каждым вызовом функции map.
intermKVStore - имя промежуточного KeyValueStore объект, к которому функция map должна добавить пар "ключ-значение". add и addmulti функции используют это имя объекта для добавления пар "ключ-значение". Если ни один из вызовов функции map не добавляет пар "ключ-значение" к intermKVStore, затем mapreduce не вызывает функцию reduce, и полученный datastore пуст.
Простым примером функции map является:
function MeanDistMapFun(data, info, intermKVStore) distances = data.Distance(~isnan(data.Distance)); sumLenValue = [sum(distances) length(distances)]; add(intermKVStore, 'sumAndLength', sumLenValue); end
Эта функция map имеет только три линии, которые выполняют некоторые простые роли. Первая линия отфильтровывает все NaN значения в блоке данных расстояния. Вторая линия создает двухэлементный вектор с общим расстоянием и количеством для блока, а третья линия добавляет этот вектор значений к intermKVStore с помощью клавиши, 'sumAndLength'. После этого функция map запускается на всех блоках данных в ds, а intermKVStore объект содержит общее расстояние и количество для каждого блока данных расстояния.
Сохраните эту функцию в текущей папке как MeanDistMapFun.m.
Входы в функцию reduce intermKey, intermValIter, и outKVStore:
intermKey is для активного ключа, добавленного функцией map. Каждый вызов функции сокращения на mapreduce задает новый уникальный ключ из ключей в промежуточном KeyValueStore объект.
intermValIter является ValueIterator связана с активной клавишей, intermKey. Этот ValueIterator объект содержит все значения, связанные с активным ключом. Прокрутка значений осуществляется с помощью hasnext и getnext функций.
outKVStore - имя для конечного KeyValueStore объект, к которому функция сокращения должна добавить пар "ключ-значение". mapreduce принимает выходные пары "ключ-значение" из outKVStore и возвращает их в выход datastore, который является KeyValueDatastore объект по умолчанию. Если ни один из вызовов функции сокращения не добавляет пар "ключ-значение" к outKVStore, затем mapreduce возвращает пустой datastore.
Простой пример функции редукции:
function MeanDistReduceFun(intermKey, intermValIter, outKVStore) sumLen = [0 0]; while hasnext(intermValIter) sumLen = sumLen + getnext(intermValIter); end add(outKVStore, 'Mean', sumLen(1)/sumLen(2)); end
Это уменьшает циклы функции через каждое из значений расстояния и счета в intermValIterПосле этого цикла функция сокращения вычисляет общее среднее расстояние рейса с простым делением, а затем добавляет одну клавишу к outKVStore.
Сохраните эту функцию в текущей папке как MeanDistReduceFun.m.
Для получения информации о записи более продвинутых функций map и reduce, смотрите Написание функции map и Запись функции reduce.
mapreduceПосле того, как у вас есть datastore, функция map и функция reduce, вы можете вызвать mapreduce для выполнения расчета. Чтобы вычислить среднее расстояние рейса в наборе данных, вызовите mapreduce использование ds, MeanDistMapFun, и MeanDistReduceFun.
outds = mapreduce(ds, @MeanDistMapFun, @MeanDistReduceFun);
******************************** * MAPREDUCE PROGRESS * ******************************** Map 0% Reduce 0% Map 16% Reduce 0% Map 32% Reduce 0% Map 48% Reduce 0% Map 65% Reduce 0% Map 81% Reduce 0% Map 97% Reduce 0% Map 100% Reduce 0% Map 100% Reduce 100%
По умолчанию, mapreduce функция отображает информацию о прогрессе в командной строке и возвращает KeyValueDatastore объект, который указывает на файлы в текущей папке. Вы можете настроить все три из этих опций, используя Name,Value аргументы в виде пар для 'OutputFolder', 'OutputType', и 'Display'. Для получения дополнительной информации смотрите страницу с описанием для mapreduce.
Используйте readall функция для чтения пар "ключ-значение" из выхода datastore.
readall(outds)
ans =
1×2 table
Key Value
________ ____________
{'Mean'} {[702.1630]}mapreduce | tabularTextDatastore
