datastore является объектом для чтения одного файла или набора файлов или данных. datastore действует как репозиторий для данных, который имеет ту же структуру и форматирование. Например, каждый файл в datastore должен содержать данные того же типа (такие как число или текст), появляющиеся в том же порядке и разделенные одним и тем же разделителем.
datastore полезен, когда:
Каждый файл в наборе может быть слишком большим, чтобы помещаться в памяти. Datastore позволяет вам считать и анализировать данные из каждого файла в небольших фрагментах, которые помещаются в памяти.
Файлы в наборе имеют произвольные имена. datastore действует как репозиторий для файлов в одной или нескольких папках. Файлы не должны иметь последовательных имен.
Можно создать datastore на основе типа данных или приложения. Различные типы хранилищ данных содержат свойства, относящиеся к типу данных, которые они поддерживают. Для получения примера см. следующую таблицу для списка MATLAB® datastores. Полный список хранилищ данных см. в разделе Выбор Datastore для формата файла или приложения.
| Тип файла или данных | Тип Datastore |
|---|---|
| Текстовые файлы, содержащие ориентированные на столбцы данные, включая файлы CSV. | TabularTextDatastore |
Файлы изображений, включая форматы, которые поддерживаются imread такие как JPEG и PNG. | ImageDatastore |
Файлы электронной таблицы с поддерживаемым Excel® формат, такой как .xlsx. | SpreadsheetDatastore |
Данные пары "ключ-значение", которые являются входами или выходами mapreduce. | KeyValueDatastore |
| Файлы Parquet, содержащие ориентированные на столбцы данные. | ParquetDatastore |
| Пользовательские форматы файлов. Требуется функция для чтения данных. | FileDatastore |
Datastore для выгрузки tall массивы. | TallDatastore |
Используйте tabularTextDatastore функция для создания datastore из файла образца airlinesmall.csv, который содержит информацию о рейсах и прибытии отдельных авиакомпаний. Результатом является TabularTextDatastore объект.
ds = tabularTextDatastore('airlinesmall.csv')ds =
TabularTextDatastore with properties:
Files: {
' ...\matlab\toolbox\matlab\demos\airlinesmall.csv'
}
Folders: {
' ...\matlab\toolbox\matlab\demos'
}
FileEncoding: 'UTF-8'
AlternateFileSystemRoots: {}
PreserveVariableNames: false
ReadVariableNames: true
VariableNames: {'Year', 'Month', 'DayofMonth' ... and 26 more}
DatetimeLocale: en_US
Text Format Properties:
NumHeaderLines: 0
Delimiter: ','
RowDelimiter: '\r\n'
TreatAsMissing: ''
MissingValue: NaN
Advanced Text Format Properties:
TextscanFormats: {'%f', '%f', '%f' ... and 26 more}
TextType: 'char'
ExponentCharacters: 'eEdD'
CommentStyle: ''
Whitespace: ' \b\t'
MultipleDelimitersAsOne: false
Properties that control the table returned by preview, read, readall:
SelectedVariableNames: {'Year', 'Month', 'DayofMonth' ... and 26 more}
SelectedFormats: {'%f', '%f', '%f' ... and 26 more}
ReadSize: 20000 rows
OutputType: 'table'
RowTimes: []
Write-specific Properties:
SupportedOutputFormats: ["txt" "csv" "xlsx" "xls" "parquet" "parq"]
DefaultOutputFormat: "txt"После создания datastore можно предворительно просматривать данные, не загружая все это в память. Вы можете задать интересующие переменные (столбцы), используя SelectedVariableNames свойство для предварительного просмотра или чтения только этих переменных.
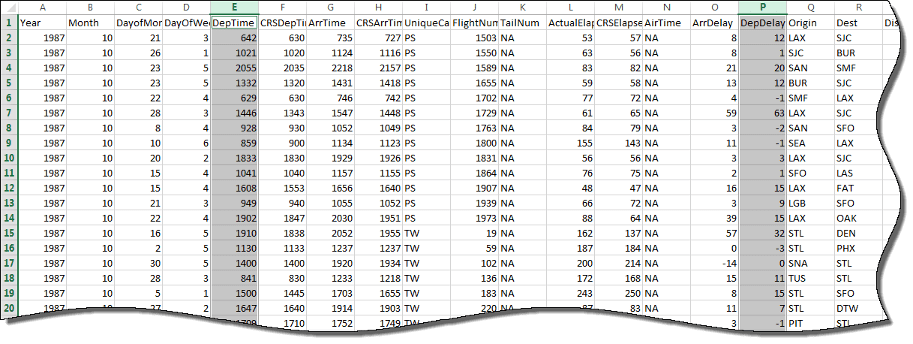
ds.SelectedVariableNames = {'DepTime','DepDelay'};
preview(ds)ans =
8×2 table
DepTime DepDelay
_______ ________
642 12
1021 1
2055 20
1332 12
629 -1
1446 63
928 -2
859 -1 Можно задать значения в данных, которые представляют отсутствующие значения. В airlinesmall.csvотсутствующие значения представлены NA.
ds.TreatAsMissing = 'NA';Если все данные в datastore для переменных, представляющих интерес, помещаются в памяти, вы можете прочитать его, используя readall функция.
T = readall(ds);
В противном случае считайте данные в меньших подмножествах, которые помещаются в памяти, используя read функция. По умолчанию, read функция читается из TabularTextDatastore 20 000 строк за раз. Однако можно изменить это значение, присвоив новое значение ReadSize свойство.
ds.ReadSize = 15000;
Сбросьте datastore в начальное состояние перед перечитыванием, используя reset функция. По вызову read функция в while цикл, можно выполнить промежуточные вычисления на каждом подмножестве данных, а затем агрегировать промежуточные результаты в конце. Этот код вычисляет максимальное значение DepDelay переменная.
reset(ds) X = []; while hasdata(ds) T = read(ds); X(end+1) = max(T.DepDelay); end maxDelay = max(X)
maxDelay =
1438Если данные в каждом отдельном файле помещаются в памяти, можно указать, что каждый вызов read следует считать один полный файл, а не определенное количество строк.
reset(ds) ds.ReadSize = 'file'; X = []; while hasdata(ds) T = read(ds); X(end+1) = max(T.DepDelay); end maxDelay = max(X);
В дополнение к чтению подмножеств данных в datastore можно применить функции map и reduce к datastore используя mapreduce или создайте длинный массив с помощью tall. Для получения дополнительной информации смотрите Начало работы с MapReduce и Длинные Массивы for Данная , Которая Не Помещаются в Память,.
fileDatastore | imageDatastore | KeyValueDatastore | mapreduce | spreadsheetDatastore | tabularTextDatastore | tall
