В этом разделе описывается, что такое регулярные выражения и как их использовать для поиска текста. Регулярные выражения являются гибкими и мощными, хотя и используют сложный синтаксис. Альтернативой регулярным выражениям является pattern (поскольку R2020b), который проще определить и результаты к коду, который легче считать. Для получения дополнительной информации см. раздел «Построение Шаблона выражения».
Регулярное выражение является последовательностью символов, которая задает определенный шаблон. Обычно вы используете регулярное выражение для поиска текста группы слов, которая соответствует шаблону, например, при анализе входа программы или при обработке блока текста.
Вектор символов 'Joh?n\w*' является примером регулярного выражения. Он задает шаблон, который начинается с букв Jo, опционально сопровождается буквой h (обозначенный 'h?'), затем следует буква n, и заканчивается любым количеством word characters, то есть символов, которые являются буквенными, числовыми или подчеркивающими (обозначены '\w*'). Этот шаблон соответствует любому из следующих:
Jon, John, Jonathan, Johnny
Регулярные выражения обеспечивают уникальный способ поиска объема текста для определенного подмножества символов в этом тексте. Вместо того, чтобы искать точное совпадение символов, как вы бы сделали с такой функцией, как strfindрегулярные выражения дают вам возможность искать конкретный шаблон символов.
Для примера несколько способов выражения метрической скорости:
km/h km/hr km/hour kilometers/hour kilometers per hour
Вы можете найти любой из вышеперечисленных терминов в своем тексте, выпустив пять отдельных команд поиска:
strfind(text, 'km/h'); strfind(text, 'km/hour'); % etc.
Однако, чтобы быть более эффективным, можно создать одну фразу, которая применяется ко всем этим условиям поиска:
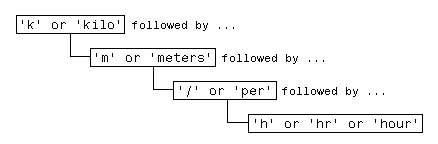
Переведите эту фразу в регулярное выражение (которое будет объяснено позже в этом разделе), и у вас есть:
pattern = 'k(ilo)?m(eters)?(/|\sper\s)h(r|our)?';
Теперь найдите один или несколько терминов, используя всего одну команду:
text = ['The high-speed train traveled at 250 ', ... 'kilometers per hour alongside the automobile ', ... 'travelling at 120 km/h.']; regexp(text, pattern, 'match')
ans =
1×2 cell array
{'kilometers per hour'} {'km/h'}
Существует четыре MATLAB® функции, поддерживающие поиск и замену символов с помощью регулярных выражений. Первые три аналогичны во входных значениях, которые они принимают, и выходных значениях, которые они возвращают. Для получения дополнительной информации щелкните ссылки на страницы с описанием функции.
| Функция | Описание |
|---|---|
regexp | Совпадает с регулярным выражением. |
regexpi | Совпадает с регулярным выражением, игнорируя случай. |
regexprep | Замените часть текста с помощью регулярного выражения. |
regexptranslate | Переведите текст в регулярное выражение. |
При вызове любой из первых трех функций передайте текст, который будет проанализирован, и регулярное выражение в первых двух входных параметрах. При вызове regexprep, передайте дополнительный вход, который является выражением, задающим шаблон для замены.
Существует три шага, связанных с использованием регулярных выражений для поиска текста для определенного термина:
Идентифицируйте уникальные шаблоны в строке
Это влечет за собой разбиение текста, который вы хотите искать, на группы подобных типов символов. Эти типы символов могут быть серией строчных букв, знаком доллара, за которым следуют три цифры, а затем десятичная точка и т.д.
Выразите каждый шаблон как регулярное выражение
Используйте metacharacters и операторы, описанные в этой документации, чтобы выразить каждый сегмент вашего шаблона поиска как регулярное выражение. Затем объедините эти сегменты выражения в одно выражение для использования в поиске.
Вызовите соответствующую функцию поиска
Передайте текст, который вы хотите проанализировать, в одну из функций поиска, таких как regexp или regexpi, или функции замены текста, regexprep.
В примере, показанном в этом разделе, выполняется поиск записи, содержащей контактную информацию, принадлежащую группе из пяти друзей. Эта информация включает имя каждого человека, номер телефона, место жительства и адрес электронной почты. Цель состоит в том, чтобы извлечь конкретную информацию из текста..
contacts = { ...
'Harry 287-625-7315 Columbus, OH hparker@hmail.com'; ...
'Janice 529-882-1759 Fresno, CA jan_stephens@horizon.net'; ...
'Mike 793-136-0975 Richmond, VA sue_and_mike@hmail.net'; ...
'Nadine 648-427-9947 Tampa, FL nadine_berry@horizon.net'; ...
'Jason 697-336-7728 Montrose, CO jason_blake@mymail.com'};
В первой части примера создается регулярное выражение, которое представляет формат стандартного адреса электронной почты. Используя это выражение, пример затем ищет информацию для адреса электронной почты одной из групп друзей. Контактная информация для Дженис находится в строке 2 contacts массив ячеек:
contacts{2}
ans =
'Janice 529-882-1759 Fresno, CA jan_stephens@horizon.net'
Типичный адрес электронной почты состоит из стандартных компонентов: имя учетной записи пользователя, за которым следует знак @, имя интернет-провайдера (ISP) пользователя, точка (точка) и область, к которому принадлежит интернет-провайдер. В таблице ниже перечислены эти компоненты в левом столбце и обобщен формат каждого компонента в правом столбце.
| Уникальные шаблоны адреса электронной почты | Общее описание каждого шаблона |
|---|---|
Начните с имени учетной записиjan_stephens . . . | Одна или несколько строчных букв и подчеркивания |
Добавить '@'jan_stephens@ . . . | @ знак |
Добавьте ISP jan_stephens@horizon . . . | Одна или несколько строчных букв, без подчеркивания |
Добавить точку (точка)jan_stephens@horizon. . . . | Символ точки (период) |
Завершите с областьюjan_stephens@horizon.net | com или net |
На этом шаге вы переводите общие форматы, выведенные на шаге 1, в сегменты регулярного выражения. Затем вы добавляете эти сегменты вместе, чтобы сформировать все выражение.
В таблице ниже показаны обобщенные описания формата каждого шаблона символов в самом левом столбце. (Это было перенесено из правого столбца таблицы на шаге 1.) Во втором столбце показаны операторы или метасимволы, которые представляют шаблон символов.
| Описание каждого сегмента | Шаблон |
|---|---|
| Одна или несколько строчных букв и подчеркивания | [a-z_]+ |
@ знак | @ |
| Одна или несколько строчных букв, без подчеркивания | [a-z]+ |
| Символ точки (период) | \. |
com или net | (com|net) |
Сборка этих шаблонов в один вектор символов дает вам полное выражение:
email = '[a-z_]+@[a-z]+\.(com|net)';
На этом шаге вы используете регулярное выражение, производное от шага 2, чтобы соответствовать адресу электронной почты одного из друзей в группе. Используйте regexp функция для выполнения поиска.
Вот список контактных данных, показанных ранее в этом разделе. Запись каждого человека занимает строку contacts массив ячеек:
contacts = { ...
'Harry 287-625-7315 Columbus, OH hparker@hmail.com'; ...
'Janice 529-882-1759 Fresno, CA jan_stephens@horizon.net'; ...
'Mike 793-136-0975 Richmond, VA sue_and_mike@hmail.net'; ...
'Nadine 648-427-9947 Tampa, FL nadine_berry@horizon.net'; ...
'Jason 697-336-7728 Montrose, CO jason_blake@mymail.com'};
Это регулярное выражение, которое представляет адрес электронной почты, производный от шага 2:
email = '[a-z_]+@[a-z]+\.(com|net)';
Вызовите regexp функция, передающая строку 2 contacts массив ячеек и email регулярное выражение. Это возвращает адрес электронной почты для Дженис.
regexp(contacts{2}, email, 'match')
ans =
1×1 cell array
{'jan_stephens@horizon.net'}
MATLAB анализирует вектор символов слева направо, «потребляя» вектор как он идет. Если найдены соответствующие символы, regexp записывает местоположение и возобновляет синтаксический анализ вектора символов, начиная сразу после окончания последнего совпадения.
Сделайте тот же вызов, но на этот раз для пятого человека в списке:
regexp(contacts{5}, email, 'match')
ans =
1×1 cell array
{'jason_blake@mymail.com'}
Вы также можете искать адрес электронной почты всех в списке, используя весь массив ячеек для входного параметра:
regexp(contacts, email, 'match');
Регулярные выражения могут содержать символы, метасимволы, операторы, лексемы и флаги, которые задают шаблоны, которые будут совпадать, как описано в следующих разделах:
Метасимволы представляют буквы, области значений букв, цифры и пробел символов. Используйте их, чтобы создать обобщенный шаблон символов.
Метасимвол | Описание | Пример |
|---|---|---|
| Любой один символ, включая пустое пространство |
|
| Любой символ, содержащийся в квадратных скобках. К следующим символам относятся буквально: |
|
| Любой символ, не содержащийся в квадратных скобках. К следующим символам относятся буквально: |
|
| Любой символ в области значений |
|
| Любой буквенный, числовой или символ подчеркивания. Для английских наборов символов, |
|
| Любой символ, который не является буквенным, числовым или подчеркивающим. Для английских наборов символов, |
|
| Любой символ белого пространства; эквивалентно |
|
| Любой непустой символ; эквивалентно |
|
| Любая числовая цифра; эквивалентно |
|
| Любой недигит символ; эквивалентно |
|
| Символ восьмеричного значения |
|
| Символ шестнадцатеричного значения |
|
Оператор | Описание |
|---|---|
| Предупреждение (звуковой сигнал) |
| Клавиша Backspace |
| Подача формы |
| Новая линия |
| Возврат каретки |
| Горизонтальная вкладка |
| Вертикальная вкладка |
| Любой символ со специальным смыслом в регулярных выражениях, которым вы хотите соответствовать буквально (для примера используйте |
Количественники задают количество раз, когда шаблон должен происходить в соответствующем тексте.
Квантор | Количество раз, когда происходит выражение | Пример |
|---|---|---|
| 0 или более раз последовательно. |
|
| 0 раз или 1 раз. |
|
| 1 или более раз последовательно. |
|
| По крайней мере
|
|
| По крайней мере
|
|
| Точно Эквивалентно |
|
Количественные значения могут появляться в трех режимах, описанных в следующей таблице. q представляет любой из количеств в предыдущей таблице.
Способ | Описание | Пример |
|---|---|---|
| Жадное выражение: соответствовать как можно большему количеству символов. | Учитывая текст |
| Ленивое выражение: соответствовать столько символов, сколько нужно. | Учитывая текст |
| Посессивное выражение: максимально совпадает, но не повторяет никаких фрагментов текста. | Учитывая текст |
Группирующие операторы позволяют вам захватывать лексемы, применять один оператор к нескольким элементам или отключать обратное отслеживание в определенной группе.
Группировка оператора | Описание | Пример |
|---|---|---|
| Группируйте элементы выражения и захватывайте лексемы. |
|
| Группируйте, но не захватывайте лексемы. |
Не группируя, |
| Группируйте атомарно. Не возвращайте данные в группу, чтобы завершить соответствие, и не захватывайте лексемы. |
|
| Совпадение выражений Если есть совпадение с Можно включать |
|
Якоря в выражении совпадают с началом или концом вектора символов или слова.
Якорь | Соответствует... | Пример |
|---|---|---|
| Начало входного текста. |
|
| Конец входного текста. |
|
| Начало слова. |
|
| Конец слова. |
|
Интерполяционные утверждения ищут шаблоны, которые непосредственно предшествуют или следуют предполагаемому соответствию, но не являются частью соответствия.
Указатель остается в текущем местоположении и символах, соответствующих test выражение не захватывается и не отбрасывается. Поэтому утверждения lookahead могут совпадать с перекрывающимися группами символов.
Интерполяционная заявка | Описание | Пример |
|---|---|---|
| Смотрите вперед для символов, которые совпадают |
|
| Смотрите вперед для символов, которые не совпадают |
|
| Следите за символами, которые совпадают |
|
| Просмотрите символы, которые не совпадают с |
|
Если вы задаете значения перед выражением, операция эквивалентна логической AND.
Операция | Описание | Пример |
|---|---|---|
| Соответствовать обоим |
|
| Совпадайте с |
|
Для получения дополнительной информации см. Раздел «Значения Lookahead в регулярных выражениях».
Логические и условные операторы позволяют вам проверить состояние заданного условия, а затем использовать результат, чтобы определить, какой шаблон, если он есть, будет соответствовать следующему. Эти операторы поддерживают логические OR и if или if/else условия. (Для AND условия, см. Lookaround Assertions.)
Условия могут быть лексемами, интерполяционными утверждениями или динамическими выражениями формы (?@cmd). Динамические выражения должны возвращать логическое или числовое значение.
Условный оператор | Описание | Пример |
|---|---|---|
| Совпадение выражений Если есть совпадение с |
|
| Если условие |
|
| Если условие |
|
Лексемы являются фрагментами совпадающего текста, которые вы задаете, заключая часть регулярного выражения в круглые скобки. Вы можете обратиться к лексеме по его последовательности в тексте (порядковая лексема) или назначить имена лексем для более легкого обслуживания кода и читаемых выходов.
Оператор порядкового маркера | Описание | Пример |
|---|---|---|
| Захват в лексему символов, соответствующих вложенному выражению. |
|
| Соответствовать |
|
| Если на |
|
Оператор именованных маркеров | Описание | Пример |
|---|---|---|
| Захват в именованную лексему символов, соответствующих вложенному выражению. |
|
| Соответствовать лексеме, на которую ссылаются |
|
| Если именованная лексема найдена, то совпадайте с |
|
Примечание
Если выражение имеет вложенные круглые скобки, MATLAB захватывает лексемы, которые соответствуют крайнему набору круглых скобок. Для примера, учитывая шаблон поиска '(and(y|rew))'MATLAB создает лексему для 'andrew' но не для 'y' или 'rew'.
Для получения дополнительной информации см. лексемы в регулярных выражениях».
Динамические выражения позволяют вам выполнить команду MATLAB или регулярное выражение, чтобы определить текст, который будет совпадать.
Круглые скобки, заключающие динамические выражения, не создают группу захвата.
Оператор | Описание | Пример |
|---|---|---|
| Синтаксический анализ При анализе |
|
| Выполните команду MATLAB, представленную |
|
| Выполните команду MATLAB, представленную |
|
В динамических выражениях для определения терминов замены используйте следующие операторы.
Оператор замены | Описание |
|---|---|
| Фрагмент входного текста, которая в данный момент соответствует |
| Фрагмент входного текста, которая предшествует текущему соответствию |
| Фрагмент текста входа, который следует текущему соответствию (используйте |
|
|
| Именованная лексема |
| Выход возвращен, когда MATLAB выполняет команду, |
Для получения дополнительной информации см. раздел Динамические регулярные выражения.
The comment оператор позволяет вставлять комментарии в код, чтобы сделать его более ремонтопригодным. Текст комментария игнорируется MATLAB при сопоставлении с входом текстом.
Персонажи | Описание | Пример |
|---|---|---|
(?#comment) | Вставьте комментарий в регулярное выражение. Текст комментария игнорируется при совпадении с входами. |
|
Флаги поиска изменяют поведение для совпадающих выражений.
Флаг | Описание |
|---|---|
(?-i) | Сопоставьте случай буквы (по умолчанию для |
(?i) | Не совпадайте буква случаем (по умолчанию для |
(?s) | Совпадайте с точкой ( |
(?-s) | Сопоставьте точку в шаблоне с любым символом, который не является символом новой строки. |
(?-m) | Соответствовать |
(?m) | Соответствовать |
(?-x) | Включите символы и комментарии при совпадении (по умолчанию). |
(?x) | Игнорируйте символы и комментарии при совпадении. Использование |
Выражение, которое изменяет флаг, может появиться либо после круглых скобок, таких как
(?i)\w*
или внутри круглых скобок и отделенных от флага двоеточием (:), такие как
(?i:\w*)
Последний синтаксис позволяет изменять поведение на часть большего выражения.
pattern | regexp | regexpi | regexprep | regexptranslate
